
When I first saw a bullet item stating SQL Server 2022 would support instant file initialization for log file growth, I was excited. When I later learned it only applies to automatic growths, and only those of 64 MB or less, I was a little less excited. With those limitations, I was skeptical this enhancement could supplant my long-standing practice of using 1 GB autogrowth for log files – at least ever since SSDs and other modern storage became more commonplace.
But after playing with it, I’m a believer.
Since the advent of the instant file initialization feature, data file growths are nearly instantaneous, because the newly-allocated space can be created empty. When log files grow, on the other hand, the new space must be zero-initialized to make sure SQL Server uses the transaction log correctly, as Paul Randal explains in Why can’t the transaction log use instant file initialization?
PREEMPTIVE_OS_WRITEFILEGATHER is the wait type you’ll see if a session is waiting on log file initialization. You can check if an instance is generally suffering this pain by comparing against other prevalent waits in your workload, by checking sys.dm_os_wait_stats:
|
1 2 3 4 5 |
SELECT wait_type, waiting_tasks_count, wait_time_ms FROM sys.dm_os_wait_stats WHERE wait_type = N'PREEMPTIVE_OS_WRITEFILEGATHER'; |
In the days of spinning rust platters, growing a log file was extremely painful, particularly in highly concurrent, write-heavy workloads. For most of my career, this alone has cast log files in general in a negative light. Even on fast and modern storage, log file expansion can be quite disruptive, because all transactions need to wait on any file growth operations.
In most cases, best practice has dictated that you just size your log files as large as possible, to avoid any unexpected growth events. But this isn’t always possible – on systems with many databases, for example, you only have so many drives, and you can’t size all of your log files to fill the disk up front. It is also sometimes difficult to predict which ones will grow more – or in more spiky ways – over time. In these cases, a smaller autogrowth setting for log files can still be a good strategy today, even without this enhancement.
But let’s see the impact of the change.
On two different instances on the same machine, I’ll create the following four databases, each with an 8 GB data file and 32 MB log file – all on the same drive. The differences will just be the version and the log file’s filegrowth setting:
- SQL Server 2019:
- 1 GB autogrow
- 64 MB autogrow
- SQL Server 2022:
- 1 GB autogrow
- 64 MB autogrow
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/* values in brackets should all be set before running script {2019|2022} = version; {64|1024} = log file size */ CREATE DATABASE ifi_{64|1024} ON ( name = N'ifi_data', filename = 'D:\data\ifi_{2019|2022}_{64|1024}.mdf', size = 8192MB, filegrowth = 2048MB ) LOG ON ( name = N'ifi_log', filename = 'D:\data\ifi_{2019|2022}_{64|1024}.ldf', size = 32MB, filegrowth = {64|1024}MB ); |
Then I’ll set up a simple but log-heavy workload script to execute against each database, measuring the following:
- total workload duration
- total duration of
PREEMPTIVE_OS_WRITEFILEGATHERwaits - number of log growth events
- total virtual log file fragments (VLFs)
- average VLF size
- ending log file size
The workload itself is pretty simple:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP TABLE IF EXISTS dbo.dummy; SELECT TOP (0) ID = IDENTITY(int,1,1), name = CONVERT(nchar(2048), N'x') INTO dbo.dummy; CREATE UNIQUE CLUSTERED INDEX CIX_dummy ON dbo.dummy(ID); INSERT dbo.dummy(name) SELECT TOP (500000) N'x' FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2; |
You can monitor the impact of this “workload” in a number of ways, including a query against sys.dm_os_wait_stats similar to the one above, as well as an Extended Events session including the following:
|
1 2 3 4 5 6 7 8 |
CREATE EVENT SESSION [log_size_changes] ON SERVER ADD EVENT sqlos.wait_info_external (WHERE ([wait_type] = N'PREEMPTIVE_OS_WRITEFILEGATHER')), ADD EVENT sqlserver.database_file_size_change ADD TARGET package0.event_file(SET filename = N'ifi_log_size_changes') /* ... */ |
Just note that some events report durations in microseconds, and others in milliseconds.
Or queries against the default trace, if you still have it enabled:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT t.DatabaseName, GrowthEvents = COUNT(*), AverageDuration = AVG(t.Duration/1000.0), TotalDuration = SUM(t.Duration/1000.0) FROM ( SELECT [path] = REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc' FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) AS s(p) ) AS p CROSS APPLY sys.fn_trace_gettable(p.[path], DEFAULT) AS t WHERE t.EventClass = 93 /* AND t.DatabaseName LIKE N'ifi%' */ GROUP BY t.DatabaseName; |
And checking the output of sys.dm_db_log_info you can see more information about the number of virtual log files and their sizes:
|
1 2 3 4 5 6 7 8 9 |
SELECT d.name, VLFCount = COUNT(li.database_id), AvgSizeMB = AVG(li.vlf_size_mb) FROM sys.databases AS d CROSS APPLY sys.dm_db_log_info(d.database_id) AS li /* WHERE d.name LIKE N'ifi%' */ GROUP BY d.name; |
After running the workload against each database, I observed the following:
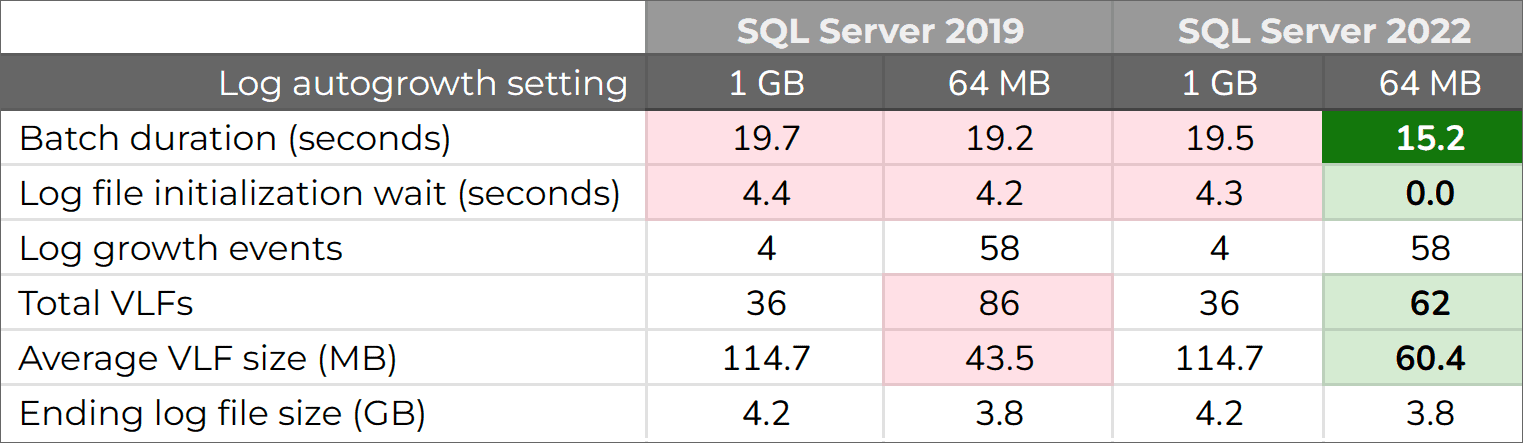
Those are favorable and promising results – we’re shaving roughly 20% off the workload duration simply by moving to 64 MB autogrowth, entirely due to eliminating PREEMPTIVE_OS_WRITEFILEGATHER waits and capitalizing on instant file initialization. In addition, we see a slight benefit from an improved VLF algorithm (recently documented), resulting in fewer, larger VLFs for the exact same log growth events.
Now, your mileage may vary. On more capable hardware, the percentage of time spent on initialization may be lower, so the benefit might be more subtle. Still, zeroing out a new portion of a log file will never be instantaneous for growth events larger than 64 MB (barring more enhancements in future versions, of course). So, as you start planning for SQL Server 2022, or even if you’re already there, this configuration option is worth testing against your workload and hardware. This is especially true if you’re not in a position to pre-size your log files bigger than you’ll ever need. After all, the fastest file change is the one that doesn’t have to happen in the first place; the next fastest is the one that can take advantage of instant file initialization.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments