
The series so far:
- Heaps in SQL Server: Part 1 The Basics
- Heaps in SQL Server: Part 2 Optimizing Reads
- Heaps in SQL Server: Part 3 Nonclustered Indexes
- Heaps in SQL Server: Part 4 PFS contention
This article is the beginning of a series of articles about Heaps in Microsoft SQL Server. Heaps are rejected by many database developers using Microsoft SQL Server. The concerns about Heaps are even fuelled by Microsoft itself by generally recommending the use of clustered indexes for every table. Globally renowned SQL Server experts also generally advise that tables in Microsoft SQL Server be provided with a clustered index.
Again, and again, I try to convince developers that a heap can even have advantages. I have discussed many pros and cons with these people and would now like to break a “PRO HEAP” lance. This article deals with the basics. Important system objects that play a major role in Heaps are only superficially presented in this article and described in detail in a follow up article.
The Basics of Heaps
Heaps are avoided in Microsoft SQL Server as the devil avoids holy water. One reason for the rejection is that many blog articles by renowned SQL Server Experts indicate that a table should use a clustered index. This article is the beginning of a series of articles that focuses on the broadest possible scope of application pro or con Heaps. The focus is on the heap to decide for yourself whether and when a heap has advantages or disadvantages compared to a clustered index. A sensible decision requires that you understand the way of working and the internal structures.
What are Heaps
Heaps are tables without a clustered index. Without an index, no sorting of the data is guaranteed. Data is stored in the table where there is space without a predetermined order. If the table is empty, data records are entered in the table in the order of the INSERT commands.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE dbo.Customers ( Id INT NOT NULL, Name VARCHAR (200) NOT NULL, Street VARCHAR (200) NOT NULL, Code CHAR (3) NOT NULL, ZIP VARCHAR (5) NOT NULL, City VARCHAR (200) NOT NULL, State VARCHAR (200) NOT NULL ) GO INSERT INTO dbo.Customers(Id, Name, Street, Code, Zip, City, State) VALUES(1,'John Smith','Times Square','123','10001', 'New York','New York'); |
The script creates a new table for storing customer data and inserts one row. Since neither an index nor a primary key is used with the CLUSTERED option, data will be stored “unsorted” in this table.
If a table does not have a clustered index, the heap can be seen in the system view [sys]. [Indexes] which will always have the [Index_Id] = 0.
|
1 2 3 4 5 6 7 8 |
-- A Heap has always the index_id = 0 SELECT object_id, name, index_id, type_desc FROM sys.indexes WHERE object_id = OBJECT_ID (N'dbo.Customers', N'U'); GO |

Figure 1: [index_id] = 0 or [index_id] = 1 is reserved for Heaps OR Clustered Indexes
The Structure of Heaps
Since Heaps are primitive data stores, no complex structures are required to manage Heaps. Heaps have one row in sys.partitions, with [index_id] = 0 for each partition used by the Heap. When a Heap has multiple partitions, each partition has a Heap structure that contains the data for that specific partition.
Depending on the data types in the Heap, each Heap structure will have one or more allocation units to store and manage the data for a specific partition. At a minimum, each Heap will have one IN_ROW_DATA allocation unit per partition.
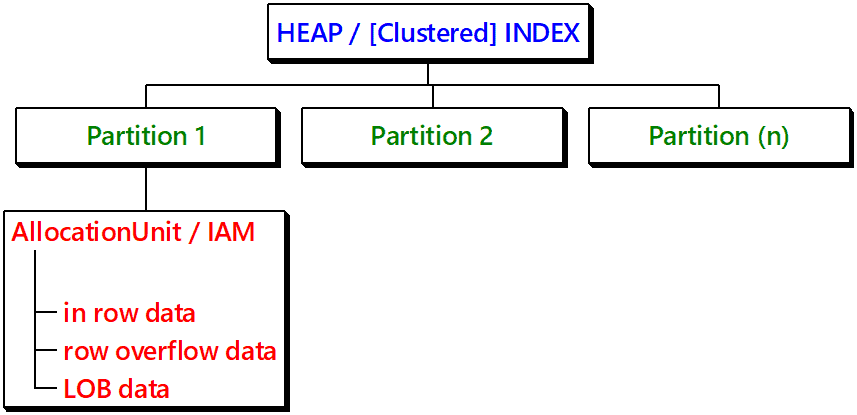
Figure 2: Storage concept of Heaps / Clustered Indexes / Nonclustered Indexes
Index Allocation Map
Each table and index use IAM structures (Index Allocation Map) to manage the data pages. An IAM page contains information about blocks (extents) that are used by a table or index per allocation unit.
Data pages of a Heap do not store references to next or previous data pages (links). This is not necessary for Heaps because a Heap does not require data to be sorted according to defined criteria.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT SIAU.type_desc, SIAU.total_pages, SIAU.used_pages, SIAU.data_pages, SIAU.first_iam_page, sys.fn_PhysLocFormatter(SIAU.first_iam_page) AS iam_page FROM sys.system_internals_allocation_units AS SIAU INNER JOIN sys.partitions AS P ON SIAU.container_id = CASE WHEN SIAU.type IN (1, 3) THEN P.hobt_id ELSE P.partition_id END WHERE P.object_id = OBJECT_ID (N'dbo.Customers', N'U'); GO |
The column [first_iam_page] in the [sys].[system_internals_allocation_units] system view points to the first IAM page in the chain of IAM pages that manage the allocated data pages of a Heap in a specific partition. Don’t worry about the mystic hex code; it can easily be deciphered with the function sys.fn_PhysLocFormatter!

Figure 3: Information about page allocations and first IAM page
The above query returns information about the storage type, number of pages and the location of the first IAM-page which manages the data pages of the Heap. Microsoft SQL Server only needs the first IAM page because it holds a reference to the next IAM and so on.
To have a look into the secrets of an IAM Page, you can use DBCC PAGE but be careful about using undocumented functions in a production system.
|
1 2 3 4 |
-- route the output of DBCC PAGE to the client DBCC TRACEON (3604); -- Show the content of a data page DBCC PAGE (0, 1, 188, 3); |
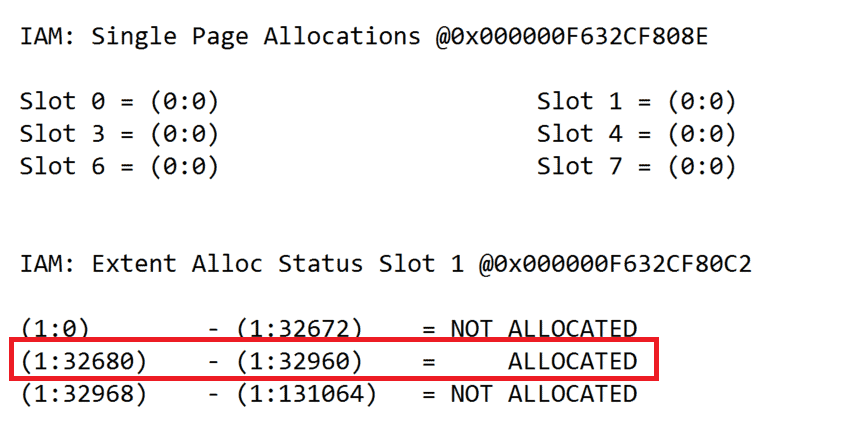
Figure 4: A deeper look into the content of an IAM-page
The above depiction shows the stored information in the IAM page of our Heap. It says that pages 32,680 – 32,967 are allocated by the table [dbo].[Customers]. So now Microsoft SQL Server knows what data pages hold data when running a SELECT statement against the Heap.
Page Free Space (PFS)
The fill level of a data page can only be specified for data pages of a Heap. Unlike a clustered index, the data rows are not sorted and do not have to be entered in a sorted form. It is up to Microsoft SQL Server to decide on which data page a data record is saved.
However, to assess where a record can be saved, Microsoft SQL Server needs to know where there is enough space on allocated data pages to complete the transaction. This information is retrieved via the recorded fill level of the data page. The information is held in the PFS page.
The problem is that this degree of filling is not saved “exactly”. Rather, Microsoft SQL Server only uses “rough” percentages to indicate the degree of filling.

The next higher fill level is updated as soon as the state is exceeded. For example, a data page is ALWAYS 50% full as soon as the first data record is entered.
The current fill level of data pages of a heap can be determined with the – undocumented – system function [sys]. [dm_db_database_page_allocations].
The next example shows how the fill level changes when the state (bytes) is exceeded. To do this, a Heap is created that stores 2,004 bytes per data record.
|
1 2 3 4 5 6 7 8 9 10 |
DROP TABLE IF EXISTS dbo.demo_table; GO CREATE TABLE dbo.demo_table ( C1 INT NOT NULL IDENTITY (1, 1), C2 CHAR(2000) NOT NULL DEFAULT ('Test') ); GO INSERT INTO dbo.demo_table DEFAULT VALUES; GO |
After the table has been created, insert one record into the table. Although the data page is filled with only 25%, Microsoft SQL Server records the filling status of the page with 50%.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- What pages have been allocated? SELECT allocated_page_page_id, previous_page_page_id, next_page_page_id, page_type_desc, page_free_space_percent FROM sys.dm_db_database_page_allocations ( DB_ID(), OBJECT_ID(N'dbo.demo_table', N'U'), 0, NULL, N'DETAILED' ); GO |

Figure 5: The page_free_space_percent
When you insert a second row the fill level won’t change since 2 * 2011 bytes = 4,022 bytes do not reach 50%. The fill level only needs to be updated for the third data record!
|
1 2 3 |
-- Insert a second row into the demo table INSERT INTO dbo.demo_table DEFAULT VALUES; GO |
NOTE: Each data record has a record header that describes the structure of the data record. The structure is stored in 7 bytes. The physical length of a sample data record is therefore not 2,004 bytes but 2,011 bytes. To learn more about the anatomy of a record, read this article by Paul Randal.
Conclusion
This article described the internals of Heaps, but you may still be wondering if there are any advantages to using them. Here is a summary of the advantages and disadvantages which I’ll write about in future articles:
Advantages of Heaps
Using a heap can be more efficient than a table with a clustered index. In general, there are some use cases for Heaps like loading staging tables or storing protocol data into a Heap, since there is no need to pay attention to sorting when saving data. Data records are saved on the next possible data page on which there is sufficient space. Furthermore, the INSERT process does not require moving down the B-Tree of an index structure to the data page to save the record!
Disadvantages of Heaps
Heaps can have several disadvantages:
A Heap cannot scale if the database design is unsuitable because of PFS contention (will be handled in the next articles in detail!)
You cannot efficiently search for data in a Heap.
The time to search for data in a Heap increases linearly with the volume of data.
A Heap is unsuitable for frequent data updates because of the risk of forwarded records (will be handled in the next articles in detail)
A Heap is horrible for every database administrator when it comes to maintenance because a Heap requires an update of nonclustered indexes when the Heap is rebuilt.
Some of the “disadvantages” mentioned above can be eliminated or bypassed if you know how a heap “ticks” internally. I hope I can convince one or the other that a clustered index is not always the better choice. How to optimize the handling of Heaps will be described in future articles, so stay tuned!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments