
If you haven’t already heard, SQL Server 2022 introduced a new built-in system function called GREATEST. Simply put, it is to a set of columns, variables, expressions etc. what the MAX function is to a set of values (i.e., rows) of a single column or expression. The opposite of GREATEST function is LEAST function which returns the smallest value from the supplied list of columns, variables, constants etc. GREATEST & LEAST can be considered a pair, just as MIN/MAX functions are.
So, on a SQL Server 2022 instance, you can simply call GREATEST function with list of columns, variables, or constant values to get the highest value out of all of them. Here is an example with list of constants:
|
1 2 3 |
SELECT GREATEST(500, 10, 3, 50, 200, 8) [Greatest], GREATEST(10, 500, 3, 50, 200, 8) [Greatest2], GREATEST(200, 10, 3, 50, 500, 8) [Greatest3] |
This will return:
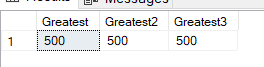
In the same manner,
I can also pass a list of columns to it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
with cte as ( select DB_NAME(database_id) db_name, max(last_user_seek) last_user_seek, max(last_user_scan) last_user_scan, max(last_user_lookup) last_user_lookup, max(last_user_update) last_user_update from sys.dm_db_index_usage_stats group by DB_NAME(database_id) ) select *, GREATEST(last_user_seek, last_user_scan, last_user_lookup,last_user_update) last_access_time_cte from cte; |
This returns the following:

And while it is not as easy to read, note that you can pass in expressions as well, as you can get the same result by pushing the GREATEST function up into the primary query too:
|
1 2 3 4 5 6 7 8 9 10 11 |
select DB_NAME(database_id) db_name, max(last_user_seek) last_user_seek, max(last_user_scan) last_user_scan, max(last_user_lookup) last_user_lookup, max(last_user_update) last_user_update, GREATEST(max(last_user_seek), max(last_user_scan), max(last_user_lookup), max(last_user_update)) AS last_access_time_cte from sys.dm_db_index_usage_stats group by DB_NAME(database_id); |
Isn’t that a nifty feature?
This rest of this article, focuses on how to achieve the same functionality in pre-SQL Server 2022 versions of SQL Server. Same approaches can be used to mimic the functionality of LEAST function as well.
I recently had to remind a client of mine that we are past the halfway mark of year 2023 that they still didn’t have a single SQL Server 2022 server, even though their SQL Server licenses covered it. I would not be surprised if there are many organizations that may still have a sizable number of SQL Servers pre-SQL 2022.
I personally though, am looking forward to when the next release of SQL Server will come out, whether it would be in 2024, 2025, or 2026? Hopefully Microsoft doesn’t make us wait beyond the year 2026.
In this article I am going to demonstrate 2 viable alternative solutions to find the largest value of a group of values in your queries (not including writing a very complicated CASE expression!)
Table Value Constructor
To start with, I will discuss using a Table Value Constructor (TVC) as I think it is easier to write and understand. TVC is very similar to the VALUES clause that you have used with the INSERT INTO statements to add new data into a table. You are maybe already aware that you can insert multiple rows in a single INSERT INTO statement:
|
1 2 3 4 5 6 7 |
declare @customer table (id int identity, name varchar(100)); insert into @customer(name) values ('tom'), ('jerry'), ('brian'); select * from @customer; |
This returns:
id name
----------- ----------
1 tom
2 jerry
3 brian
Similarly, you can use a VALUES clause to construct a derived table. Here is an example of using it with constants:
|
1 2 3 4 5 6 7 |
SELECT [Greatest] = ( SELECT MAX([Greatest]) FROM (VALUES (500),(1000),(3), (50), (200),(8)) AS derived_table([Greatest]) ); |
This will return the greatest of values in that derived table:
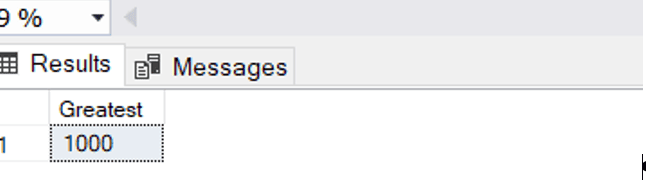
Similarly, you can use list of columns, variables, expressions etc.
So, using the VALUES construct here, I will construct a derived table to convert values from multiple columns into values/rows for a single derived column, last_access_time, sort its results in descending order (from highest to lowest) then select the first row’s value to get the highest (i.e. GREATEST) value.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
with cte as ( select DB_NAME(database_id) db_name, max(last_user_seek) last_user_seek, max(last_user_scan) last_user_scan, max(last_user_lookup) last_user_lookup, max(last_user_update) last_user_update from sys.dm_db_index_usage_stats group by DB_NAME(database_id) ) select *, last_access_time_derived = (select top 1 last_access_time from (values (last_user_seek), (last_user_scan), (last_user_lookup), (last_user_update)) derived_table(last_access_time) order by last_access_time desc ) from cte; |
This will return something like the following (depending on your actual server’s utilization):

Note: depending on the kind of server you are using this on, it may have NULL values for some of the values. For example, on the editor’s computer, it returned:
![]()
So, just like MAX, it does not return NULL unless all scalar expressions are NULL. This method is by no means as easy to work with as the GREATEST function, but it is generally straightforward to implement if needed.
It looks complicated without the built-in GREATEST function, doesn’t it? Well, I think the next method, UNPIVOT, I will show you is even more complicated. That’s just my opinion, the opinions of others in general may vary.
Unpivot
The idea with using an unpivot is to take values from multiple columns and turns them into rows for a single column. In other words, it can be used to convert a set of columns into a row. If you are familiar with the TRANSPOSE function in excel, unpivot is very similar. It’s the opposite of the PIVOT statement, which takes values for a single column from multiple rows and turns each value into multiple columns.
Here is an example of how you can use UNPIVOT to convert columns into rows (note that if you have not executed any queries in the other databases since a reboot, no data may be returned by this query):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
/* The DMV sys.dm_db_index_usage_stats returns the operational stats on each index in every database that have had any read and/or write activity since the last restart of the sql instance. It returns one row for each index. However, by use of the UNPIVOT clause, I am converting it's four columns with "last_*" names, into rows so instead of a single row for each index, it returns multiple rows, one row for each column that has a not-null value. The where clause filters out: 1. System databases i.e. where database_id > 4 2. Non-clustered indexes i.e where index_id <= 1 Essentially, when index_id is 0 the table is a heap i.e. it has no clustered index when index_id is 1 the table has a clustered index and is not a heap */ SELECT TOP 10 DB_NAME(database_id) [db_name], OBJECT_NAME(object_id, database_id) [object_name], [column_name], [column_value] FROM sys.dm_db_index_usage_stats UNPIVOT ([column_value] FOR [column_name] IN ( last_user_seek, last_user_scan, last_user_lookup, last_user_update ) ) unpv WHERE index_id <= 1 AND database_id > 4 ORDER BY [db_name], [object_name], [column_name]; |
The values for the four columns last_user_lookup, last_user_scan, last_user_seek and last_user_update in the sys.dm_db_index_usage_stats are now showing as rows.
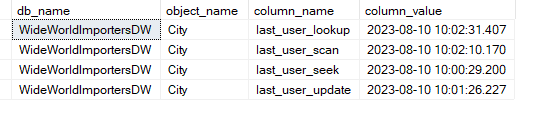
And I just want to know the highest value from the 4 columns, I can just use the MAX function and slightly modify the query to add the GROUP BY clause.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT TOP 10 DB_NAME(database_id) [db_name], OBJECT_NAME(object_id, database_id) [object_name], [last_accessed] = MAX([column_value]) FROM sys.dm_db_index_usage_stats UNPIVOT ([column_value] FOR [column_name] IN ( last_user_seek, last_user_scan, last_user_lookup, last_user_update ) ) unpv WHERE database_id > 4 GROUP BY database_id, object_id ORDER BY [db_name], [object_name]; |
This returns the following on my server.
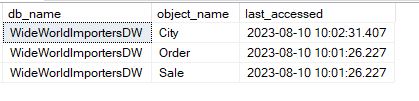
To extend the example further, I want to know if/when the last time a table in the the database was accessed. This query is longer than it may need to be because I also want to display the individual values for the 4 columns as well as the MAX/highest value among them.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
USE MSDB; with cte as ( SELECT [last_user_seek] = MAX(last_user_seek), [last_user_scan] = MAX(last_user_scan), [last_user_lookup] = MAX(last_user_lookup), [last_user_update] = MAX(last_user_update) FROM sys.dm_db_index_usage_stats AS i WHERE i.database_id = DB_ID() ) SELECT [Database] = DB_NAME(), * FROM cte, ( SELECT MAX([last_access_time]) [last_access_time] FROM ( SELECT [last_user_seek] = MAX(last_user_seek), [last_user_scan] = MAX(last_user_scan), [last_user_lookup] = MAX(last_user_lookup), [last_user_update] = MAX(last_user_update) FROM cte ) p UNPIVOT ([last_access_time] FOR [Column] IN ( last_user_seek, last_user_scan, last_user_lookup, last_user_update) ) AS unpvt ) unpvt; |
This returns:

As you can see, the using UNPIVOT can take more lines of code and can be quite a bit complicated. As you will see later in this article, per the performance test I performed, it is also slower than the Table Value Constructor method.
I have tested these syntaxes in SQL Server versions going back to 2012. PIVOT and UNPIVOT were first introduced in SQL 2005 so the syntax’s I presented in this article should still work there.
Performance Test
How is the query performance between the TVF and Unpivot methods, or with the new greatest function?
To find that out, I am going to generate some random data. The following SQL script creates a table with name random_data_for_testing and inserts 10 million rows into it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
SET NOCOUNT ON; if object_id('random_data_for_testing', 'U') is not null drop table random_data_for_testing; GO create table random_data_for_testing ( id int identity primary key, value_01 float default substring(cast(rand() as varchar(20)), 3, 15), value_02 float default substring(cast(rand() as varchar(20)), 3, 15), value_03 float default substring(cast(rand() as varchar(20)), 3, 15), value_04 float default substring(cast(rand() as varchar(20)), 3, 15), value_05 float default substring(cast(rand() as varchar(20)), 3, 15), value_06 float default substring(cast(rand() as varchar(20)), 3, 15), value_07 float default substring(cast(rand() as varchar(20)), 3, 15), value_08 float default substring(cast(rand() as varchar(20)), 3, 15), value_09 float default substring(cast(rand() as varchar(20)), 3, 15), value_10 float default substring(cast(rand() as varchar(20)), 3, 15) ); GO declare @commit_size int = 100000; declare @max_rows int = 10000000; declare @counter int = 1; declare @commit_counter int = 0; declare @max_commit_count int = @max_rows / @commit_size; while @counter <= @max_rows begin if @@TRANCOUNT = 0 BEGIN TRAN insert into random_data_for_testing default values set @counter = @counter + 1 IF @@TRANCOUNT > 0 and @counter % @commit_size = 0 BEGIN set @commit_counter = @commit_counter + 1 raiserror('Committing %i of %i transactions....', 10, 1, @commit_counter, @max_commit_count) with nowait commit; END end if @@TRANCOUNT > 0 COMMIT; |
My first test query is to do a test to get the highest value among the 10 columns (named value_01 to value_10 in the test table), using all 3 methods. I ran the script multiple times to make sure there are no physical reads or read-ahead reads with any of the queries so we can compare just the duration, logical IO and CPU as accurately as possible.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
SET NOCOUNT ON; SET ANSI_WARNINGS OFF; GO PRINT '---------------------------------------------' PRINT '********* Test using the function Greatest...' PRINT '---------------------------------------------' SET STATISTICS IO ON; SET STATISTICS TIME ON; GO SELECT MAX(GREATEST((value_01),(value_02),(value_03), (value_04),(value_05),(value_06), (value_07),(value_09),(value_10))) AS using_greatest_function FROM random_data_for_testing; SET STATISTICS IO OFF; SET STATISTICS TIME OFF; GO PRINT '---------------------------------------------' PRINT '********* Test using the TVC method..........' PRINT '---------------------------------------------' SET STATISTICS IO ON; SET STATISTICS TIME ON; GO SELECT MAX(greatest_value) using_tvf FROM ( SELECT greatest_value = (SELECT MAX(greatest_value) FROM (VALUES(value_01),(value_02),(value_03), (value_04),(value_05),(value_06), (value_07),(value_09),(value_10) ) derived_table(greatest_value) ) FROM random_data_for_testing ) a; SET STATISTICS IO OFF; SET STATISTICS TIME OFF; GO PRINT '---------------------------------------------' PRINT '********* Test using the Unpivot...' PRINT '---------------------------------------------' SET STATISTICS IO ON; SET STATISTICS TIME ON; GO SELECT MAX(greatest_value) using_unpivot FROM random_data_for_testing UNPIVOT ([greatest_value] FOR [Column] IN (value_01, value_02, value_03 , value_04, value_05,value_06, value_07,value_09, value_10)) AS unpvt SET STATISTICS IO OFF; SET STATISTICS TIME OFF; GO |
Results:
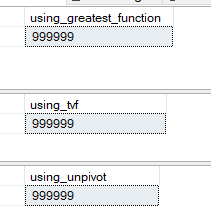
Here are the key stats from the STATISTICS IO and STATISTICS TIME:
********* Test using the function Greatest...
Table 'random_data_for_testing'. Scan count 5, logical reads 118295
SQL Server Execution Times:
CPU time = 4405 ms, elapsed time = 1381 ms.
********* Test using the TVC method..........
Table 'random_data_for_testing'. Scan count 5, logical reads 117343
SQL Server Execution Times:
CPU time = 12000 ms, elapsed time = 3332 ms.
********* Test using the Unpivot...
Table 'random_data_for_testing'Scan count 5, logical reads 117179
SQL Server Execution Times:
CPU time = 17219 ms, elapsed time = 4813 ms.
The amount of IO (logical reads) is almost identical among the three methods. But notice the difference in the CPU time and Elapsed time values for each. The elapsed time for the function GREATEST is 1381 ms, for the TVC it is 3332 ms and for UNPIVOT it is 4813 ms.
Below is the screenshot of the actual execution plan and as you can see the query cost as relative to the batch, cost of function GREATEST is 12%, TVC is 34% and the UNPIVOT is 54%.
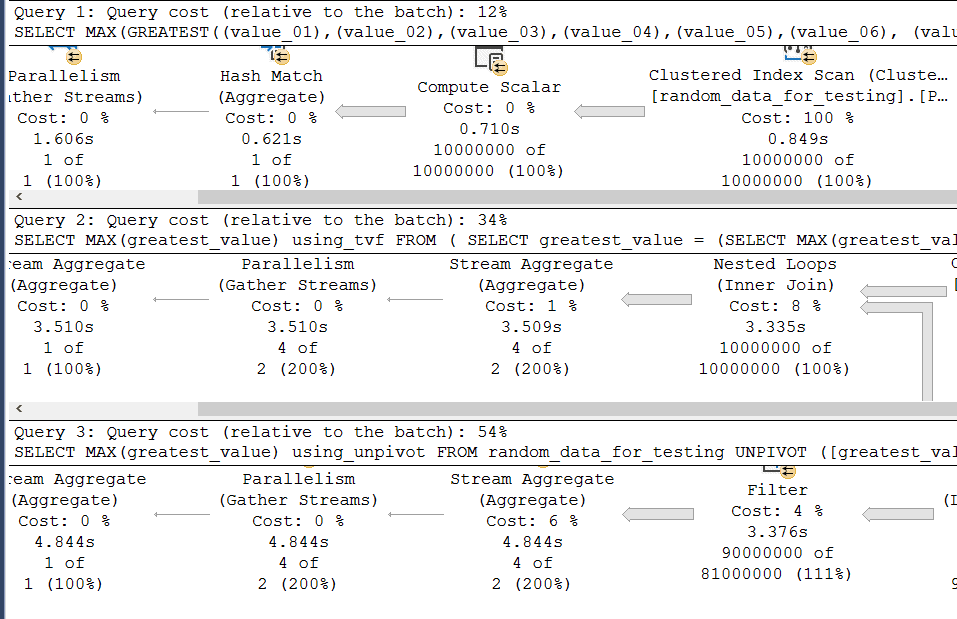
As you can see from the thickness of the pipe going from right to left, when a query needs to process a relatively great deal of rows, using the build in function gives the best performance. That shouldn’t be a surprise. If that wasn’t the case, somebody at Microsoft made a big booboo! However, between the TVF and Unpivot, TVF is faster.
Note: This by no means a scientific test. Generally, though I have seen TVF to be faster than Unpivot.
What if the query is using a very selective filter condition on a clustered primary key on a single, integer column? This kind of queries are usually ideal queries in “almost” any conditions, even if it includes columns with LOB data types like XML, VARBINARY(MAX) etc.
Just to be sure, let’s look at the following example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
SET NOCOUNT ON; SET ANSI_WARNINGS OFF; GO declare @id int = 100100; PRINT '---------------------------------------------'; PRINT '********* Test using the function Greatest...'; PRINT '---------------------------------------------'; SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT *, using_greatest_function = GREATEST(value_01,value_02,value_03,value_04, value_05,value_06,value_07,value_08, value_09, value_10 ) FROM random_data_for_testing WHERE id = @id; SET STATISTICS IO OFF; SET STATISTICS TIME OFF; PRINT '---------------------------------------------' PRINT '********* Test using the TVC method..........' PRINT '---------------------------------------------' SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT *, using_tvf = ( SELECT MAX(greatest_value) FROM (VALUES (value_01),(value_02),(value_03), (value_04),(value_05),(value_06), (value_07),(value_08),(value_09), (value_10)) AS derived_table(greatest_value) ) FROM random_data_for_testing WHERE id = @id; SET STATISTICS IO OFF; SET STATISTICS TIME OFF; PRINT '---------------------------------------------'; PRINT '********* Test using the Unpivot...'; PRINT '---------------------------------------------'; SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT t.*, p.using_unpivot FROM random_data_for_testing t INNER JOIN ( SELECT id, MAX(greatest_value) using_unpivot FROM random_data_for_testing UNPIVOT ([greatest_value] FOR [Column] IN (value_01,value_02,value_03, value_04, value_05, value_06, value_07, value_08, value_09, value_10)) AS unpvt WHERE id = @id group by id ) p on p.id = t.id; SET STATISTICS IO OFF; SET STATISTICS TIME OFF; |
This returns three identical result sets:
And quite similar execution times as well:
********* Test using the function Greatest...
Table 'random_data_for_testing'. Scan count 0, logical reads 3
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
********* Test using the TVC method..........
Table 'random_data_for_testing'. Scan count 0, logical reads 3
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
********* Test using the Unpivot...
Table 'random_data_for_testing'. Scan count 0, logical reads 6
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
With the following actual execution plans:

The entire script finishes in sub-sub-second. Still, at a microsecond (a millionth of a second) level, you can see that the Unpivot performs the worst.
Summary
In this article, I have demonstrated the new GREATEST and LEAST value functions in SQL Server 2022 and have show that in general testing, these functions are very fast. However, as not everyone is using SQL Server 2022, I also demonstrated a method using Table Value Constructors that give you similar functionality (with much less straightforward code), as well as a method using the often disregarded UNPIVOT function.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments