
We’re going to use the AdventureWorks sample database (get your copy here), where the folks in marketing requested a list of users to e-mail a new promotional campaign. The customers need to meet at least one of the following criteria:
- last placed an order more than a year ago
- placed 3 or more orders in the past year
- have ordered from a specific category in the past two weeks
These criteria don’t have to make sense! They just need to make the query a little bit more complex than your average CRUD operations.
First, we’re going to update Sales.SalesOrderHeader to modern times so that dates make sense relative to today. We only care about OrderDate here, but there are check constraints that protect a couple of other columns (as well as a trigger that sometimes fails on db<>fiddle but that I have no energy to troubleshoot):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DISABLE TRIGGER Sales.uSalesOrderHeader ON Sales.SalesOrderHeader; GO DECLARE @months int; SELECT @months = DATEDIFF(MONTH, MAX(OrderDate), GETDATE()) FROM Sales.SalesOrderHeader; UPDATE Sales.SalesOrderHeader SET DueDate = DATEADD(MONTH, @months-1, DueDate); UPDATE Sales.SalesOrderHeader SET ShipDate = DATEADD(MONTH, @months-1, ShipDate); UPDATE Sales.SalesOrderHeader SET OrderDate = DATEADD(MONTH, @months-1, OrderDate); GO ENABLE TRIGGER Sales.uSalesOrderHeader ON Sales.SalesOrderHeader; |
This stored procedure that someone wrote will now return data (without the update, it would be hard to write predictable queries based on, say, some offset from GETDATE()).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
create proc sp_find_customers(@paramIntCategoryId INT) as select customerid, firstname, emailaddress from ( -- last placed an order more than a year ago select distinct customerid, firstname, emailaddress from sales.customer a (nolock), person.person b(nolock), person.emailaddress c(nolock) where personid = b.businessentityid and b.businessentityid = c.businessentityid and (select max(orderdate) from sales.salesorderheader (nolock) where customerid = a.customerid) < dateadd(yyyy,-1,convert(DATE,getdate())) union -- placed at least 3 orders in the past year select distinct customerid, firstname, emailaddress from person.person p (nolock) join person.emailaddress e (nolock) on p.businessentityid = e.businessentityid join sales.customer c (nolock) on personid = p.businessentityid where customerid in (select customerid from sales.salesorderheader (nolock) where orderdate between dateadd(yy, -1, convert(DATE,getdate())) and getdate() group by customerid having count(*) >= 3) union -- ordered within specified category in past two weeks select distinct customerid, firstname, emailaddress from person.emailaddress em (nolock) join person.person pp with (nolock) on em.businessentityid=pp.businessentityid join sales.customer cu (nolock) on personid = pp.businessentityid where customerid in (select top (2147483647) customerid from sales.salesorderheader oh (nolock) join sales.salesorderdetail od (nolock) on oh.salesorderid = od.salesorderid and datediff(day, oh.orderdate, convert(DATE,getdate())) <= 14 join production.product pr (nolock) on od.productid = pr.productid inner join production.productsubcategory AS sc (nolock) on pr.productsubcategoryid = sc.productsubcategoryid and sc.productcategoryid = @paramIntCategoryId order by customerid) ) x order by 1 |
You laugh. Or maybe you cry. But I do see all of this, all the time, just maybe not always all at the same time.
While the stored procedure itself is only 40 lines, I’m sure a quick skim will reveal some things you don’t like. But do you think I can find 40 problems?
Challenge Accepted.
Before we start, I can’t emphasize enough that just about any convention in T-SQL is completely subjective, and you may or may not agree with any of mine. And that’s okay. Still, I’ll tell you the problems I spotted, line by line, and why I think they’re problems (with helpful links to more details, where appropriate).
|
1 |
create proc sp_find_customers(@paramIntCategoryId INT) |
On the very first line, there are multiple problems:
- All lower case keywords – I’m only going to mention this once, but reading a wall of code in all lower case (or all upper case!) is hard on the eyes. Personally, I like upper casing T-SQL keywords, Pascal case for entity names, and lower case for data types (to be mentioned in a moment).
- Shorthand – The abbreviation
procis grating to me because people start to talk that way, too. “Can you create a prock?” It’s a procedure; just spell it out. - Missing schema prefix – Leaving out the schema can be problematic both for performance and for other users and maintainers. While the performance issue is less relevant during object creation, it’s a mindset and we should all be consistent.
- Bad procedure name – Not just the
sp_prefix, which should be avoided but, also, what does “find_customers” mean? This name should be more specific to the task at hand, and also match your existing naming scheme. Something likeCustomer_GetListForCampaignXYZ, for example. (Generally, I preferentity_action, likeCustomer_Find, overaction_entity, likeFind_Customer, primarily due to sorting and grouping. I’m very rarely looking for all the stored procedures that find anything.) - Parentheses for nothing – It’s a minor gripe, but I don’t like adding extra control characters for the sake of it. Stored procedure parameter lists do not need to be enclosed in parentheses, so add them only if your team agrees that they actually make the procedure more readable.
- Bad parameter name (i) – It doesn’t need to start with
@param– that is obvious from where it is and, later in the procedure, the source isn’t likely to be important anyway. - Bad parameter name (ii) – It also doesn’t need to be prefixed with its data type – that is also obvious from the definition, and naming it this way locks it in (making future changes to that data type harder).
- Bad parameter name (iii) – In AdventureWorks, the IDs are upper case, so it should be
@CategoryIDjust to be consistent and avoid any confusion or ambiguity. - Upper case data type – I learned the hard way the best pattern for data types is to match the case in
sys.typesexactly, which is arguably more important if you ever deal with case sensitive databases or instances. While it doesn’t affect the basic native types, for consistency, this means you would useint, notINT. - Everything on one line – For formatting purposes I kept the parameter list short, but I’ve seen lists of 10+ parameters scroll way off the screen to the right, and I don’t have to tell you what a headache that is during a fire drill. Strive to be more liberal with white space – the goal shouldn’t be to keep the line count short at the cost of readability.
|
2 |
as |
It’s only two characters, but it’s more about what’s missing here:
- No BEGIN/END – I prefer to wrap my procedure body in clear block elements that are even more explicit about where the procedure ends than indentation and the (non-T-SQL!)
GObatch separator could ever be. - No SET NOCOUNT – I always add
SET NOCOUNT ON;to the beginning of every stored procedure to suppress all of those chattyDONE_IN_PROCmessages. While in modern versions of SQL Server and various transport layers the benefits aren’t as pronounced as they used to be, the extra chatter still can’t possibly help anything.
|
3 |
select customerid, firstname, emailaddress from |
Only one new problem here:
- Lower case columns – In the metadata, those columns are named
CustomerID,FirstName, andEmailAddress. Every single reference to them should match.
|
5 |
-- last placed an order more than a year ago |
- Single-line comments – While it’s actually refreshing to see comments inside of queries, not all comments are the same. As Brent Ozar explains in Never, Ever, Ever Start T-SQL Comments with Two Dashes, single-line comments cause many problems downstream – for example, when reviewing queries from the plan cache or monitoring tools, or even returning the definition to a grid in Management Studio. I’m far from perfect, especially in quick throwaway fiddles, but I’ve been trying harder to always use
/* this form */. Contradicting Brent a little bit, Andy Mallon has a great productivity use case of combining the two forms in slide 28 of this presentation.
|
7 |
select distinct customerid, firstname, emailaddress |
- Unnecessary DISTINCT – This query is part of a
UNIONwhich – by default, and possibly not commonly known – has to perform aDISTINCTagainst the output of the concatenation anyway, so doing so inside any of the inputs to theUNIONis redundant. This query is littered with these and they can all be avoided – typically they are used to suppress duplicate rows from joins that should have been implemented asEXISTSchecks instead and/or deferring the joins until later.
|
8 |
from sales.customer a (nolock), person.person b(nolock), |
All right, now we’re getting warmed up! A few new problems here:
- Lower case object names – These tables are called
Sales.CustomerandPerson.Person, and it’s important for code to match what is in the metadata since it may be destined for case sensitive environments. IntelliSense and other tools make missing this detail hard to excuse these days. If you have a case sensitive database, being cavalier about this can lead to problems, especially if production is case sensitive and your development environment is not. I’m a big advocate of always developing in case sensitive because surprises are easier to fix locally and up front than after they’ve been deployed. - Bad aliases – Why is
customeraliased asaandpersonasb? In longer and more complex queries, reverse engineering this bizarre (but common!) mapping pattern is a recipe for migraines. As an aside, I detest aliases that are added in this form without using theASkeyword – while optional, I think it gives an important visual cue. - Littering of NOLOCK – This hint is not a magic go-faster switch; it is just bad news in general. Placing it next to every table reference throughout all queries is even worse. If you have some reason you can’t use
READ COMMITTED SNAPSHOT(RCSI), at the very least set the isolation level once at the top of the procedure (and maybe even add a comment explaining why this is necessary). Then, when you come to your senses, it’s just one line to fix. (I collected a treasure trove of resources detailing the many perils ofNOLOCKhere.) - Old-style joins – I still see these all the time, even though better syntax replaced them more than 30 years ago!
FROM a, bis less desirable than explicit joins for a couple of reasons. One is that it forces you to group join criteria and filter predicates together (and an argument there that is only partially true is that it can invite unintended Cartesian products). The other is that it forces inconsistency because in SQL Server there is no longer a way to perform deterministic outer joins without switching to explicitOUTER JOINsyntax.
|
9 |
person.emailaddress c(nolock) where personid = b.businessentityid |
- Missing alias – Why is there no alias reference associated with
personid? When writing the initial query, this might not be a problem, because you’d get an ambiguous column name error if it were. But what about when someone comes back later and adds another table to the query? Now they have to go fix all unreferenced columns and possibly go look up all the tables to unravel. I talked about how we should always reference all columns for a recent T-SQL Tuesday.
|
10 |
and b.businessentityid = c.businessentityid and (select max(orderdate) |
There’s definitely a code smell starting to waft from this line:
- Correlated subquery in a predicate – Running an aggregate against another table as part of a
WHEREclause has the potential to scan that other table completely for every row in the current query (which could be a cross product for all we know). - Subquery indentation – Any time you introduce an
INorEXISTSor other type of correlated anything, you should use white space to make it clear something radical is happening here – start it on the next line, make the left margin wider, do something to make it obvious and easier to follow.
|
12 |
where customerid = a.customerid) < dateadd(yyyy,-1,convert(DATE,getdate())) |
- DATEPART shorthand – I don’t even know if you could call this “shorthand,” as I certainly see no advantage to typing four letters (
yyyy) instead of four different letters that form a self-documenting word (year). A shorthand habit here can lead to problems, e.g. play with date parts likeWandY. I talk about abusing shorthand and several other date-related topics in Dating Responsibly. - Repeated non-deterministic variable – A minor thing but if
getdate()is evaluated multiple times in the query, it could give a different answer, especially if the query is run right around midnight. Much better to pull these calculations out into a variable – not necessarily for better estimates, but to make sure all the predicates are speaking the same language.
|
21 |
where orderdate between dateadd(yy, -1, convert(DATE,getdate())) and getdate() |
No new problems until we hit line 21:
- DATEPART shorthand – I’m mentioning this again not because of the shorthand itself but because it’s inconsistent. If you’re going to use
yyyythen always useyyyy. Don’t get even lazier about it sometimes. - BETWEEN {some time} and … {now}? – I’m already not a big fan of
BETWEENfor date range queries (it can lead to lots of ambiguity), but I certainly see no reason to include the current time as the upper bound, rather than the whole clause just being>= {some time}. Orders generally aren’t placed in the future and, if they are, all the queries in this procedure should use that same upper bound. And if there is some reason the query should filter out future dates, there should be a comment here explaining why.
|
27 |
from person.emailaddress em (nolock) join person.person pp with (nolock) |
- Inconsistent join ordering – in the previous section, the tables were listed
personthenemailaddress. Now the order is swapped, and maybe there’s a reason, but it causes the reader to pause and wonder what it is. - Inconsistent aliasing – In the previous section of the query,
personwas aliased asp, andemailaddressase. Now they’ve changed toppandem– while they are technically different queries, it is much better for future maintainers to adopt a consistent aliasing strategy (including what to do when a single query is aliased multiple times in the same query), so that there is less reverse engineering every time a query is reviewed. - Inconsistent hinting – All the other
NOLOCKhints in the query are just added to the table alias. This one is done more correctly, with the properWITHkeyword, but it’s a variation that can be disruptive to a reviewer.
|
28 |
on pp.businessentityid=em.businessentityid |
- Inconsistent clause ordering – Getting nit-picky here perhaps, but in the previous section, the clauses were listed in the same order the tables were introduced to the join; this time, they’re swapped. If there’s a reason the order has changed, there should be a comment to help a future maintainer understand.
- Inconsistent spacing – I like white space around my keywords and operators, so it really stands out to me when there is a change in pattern – in this case, there is no helpful white space around the
=operator.
|
30 |
where customerid in (select top (2147483647) customerid |
- TOP (2 billion) – This seems a holdover from the SQL Server 2000 days, where you could fool the engine into returning data from a view in a specific order without having to say so, simply by putting
TOP 100 PERCENT ... ORDER BYinto the view definition. That hasn’t worked in 20 years, but I see this technique sometimes used to try to defeat row goals or coerce a specific index. Most likely it was just copied and pasted from somewhere else, but it has no place here.
|
33 |
and datediff(day, oh.orderdate, convert(DATE,getdate())) <= 14 |
- Expression against a column – SQL Server won’t be able to use an index on
OrderDatebecause it will have to evaluate the expression for every row. This is a pattern I see quite a bit, and it can be hard to explain to newer users because, rightly so, they expect SQL Server to be able to rewrite the expression so that it can use an index. Always question when aWHEREorONclause has to change what’s in the column in order to perform a comparison. In this case, much better (and more logical) to sayWHERE oh.OrderDate >= @TwoWeeksAgo.
|
35 |
inner join production.productsubcategory AS sc (nolock) |
- Inconsistent join syntax – This one wasn’t really a problem for me until it became inconsistent – don’t say
joinsometimes, andinner joinother times. Personally, I prefer being more explicit about the type of join, but pick one or the other and always use that form. - Another table alias issue – Suddenly we get an
AShere, seemingly out of nowhere. I think this is another case where inconsistency is borne from queries being copied & pasted from other sources or multiple authors contributing to a query. It may seem trite but take the time to step through the query and make sure all of the conventions match your established style (and if you don’t have one, create one).
|
37 |
and sc.productcategoryid = @paramIntCategoryId order by customerid) |
- Filter as a join clause – Technically, that
andshould be aWHERE, since that is not a part of the join criteria. When we’re talking aboutOUTERjoins, there is more nuance depending on which table the predicate applies to, but for anINNERjoin, the join and filter criteria shouldn’t mix. - Misplaced ORDER BY – Merely mentioning this because when the
TOPis removed this pointless clause will actually cause a compilation error.
|
39 |
x |
- Meaningless alias name – This alias should be more descriptive about the subquery it references. And trust me, I’m guilty of this too; you’ll see
xas an alias or CTE name in many of my solutions on Stack Overflow (but never in production code). I never said some of the problems I’d point out here aren’t my own problems too!
|
40 |
order by 1 |
- ORDER BY ordinal – Using ordinal numbers to define sorting is convenient, sure, but it’s very brittle and not self-documenting. Anyone reading the code now has to go parse the
SELECTlist to work it out, and anyone modifying theSELECTlist might not realize that adding or rearranging columns just introduced a bug in the application. - No statement terminator – This is one of the things I’ve been harping on throughout a decent portion of my career – we should always be terminating statements with semi-colons. Though, personally, I don’t like adding them to block wrappers, like
BEGIN/END, because to me those aren’t independent statements (and try adding a semi-colon toBEGIN/END TRYandBEGIN/END CATCH– one of these things is definitely not like the others.
Read also:
Temporary tables in SQL Server
Subqueries vs. derived tables
Dependencies and references in SQL Server
CHOOSE function for conditional logic
See, That Wasn’t So Hard.
I looked at a 40-line stored procedure and identified 40 problems (not counting the ones that occurred multiple times). That’s a problem per line! And it wasn’t even that hard to come up with this “crazy” stored procedure – it’s actually quite believable that something similar could have crossed your desk as part of a pull request.
But How Would You Write It, Aaron?
Well, that’s a good question.
I would certainly start by stepping back to understand what the procedure is actually trying to accomplish. We have three separate queries that all do similar things: they join order and customer tables and include or exclude rows based on dates and counts and other criteria. Doing this independently and then combining them with multiple distinct sorts to remove duplicates is wasteful and could lead to unacceptable performance at scale.
So, I would attack the problem with the goal of touching each table only once – and of course cleaning up all the other things I noticed (most of which, admittedly, are aesthetic and have no bearing on performance). Taking a quick swing at it, and keeping in mind there are a dozen ways to write this, I came up with the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
CREATE PROCEDURE dbo.Customer_GetListForCampaignXYZ @CategoryID int AS BEGIN SET NOCOUNT ON; DECLARE @AYearAgo date = DATEADD(YEAR, -1, GETDATE()), @TwoWeeksAgo date = DATEADD(WEEK, -2, GETDATE()); WITH CandidateCustomers AS ( SELECT CustomerID, IsAnOrderOlderThanAYearAgo = MAX ([old]), OrdersInPastYear = COUNT([new]), RecentOrderFromDefinedCategory = MAX ([cat]) FROM ( SELECT CustomerID, [old] = CASE WHEN OrderDate < @AYearAgo THEN 1 END, [new] = CASE WHEN OrderDate >= @AYearAgo THEN 1 END, [cat] = CASE WHEN OrderDate >= @TwoWeeksAgo AND EXISTS ( SELECT 1 FROM Sales.SalesOrderDetail AS d WHERE d.SalesOrderID = h.SalesOrderID AND EXISTS ( SELECT 1 FROM production.product AS p INNER JOIN Production.ProductSubcategory AS sc ON p.ProductSubcategoryID = sc.ProductSubcategoryID WHERE sc.ProductCategoryID = @CategoryID AND p.ProductID = d.ProductID ) ) THEN 1 END FROM Sales.SalesOrderHeader AS h ) AS agg GROUP BY CustomerID ) SELECT cc.CustomerID, pp.FirstName, em.EmailAddress FROM CandidateCustomers AS cc INNER JOIN Sales.Customer AS cu ON cc.CustomerID = cu.CustomerID INNER JOIN Person.Person AS pp ON cu.PersonID = pp.BusinessEntityID INNER JOIN Person.EmailAddress AS em ON pp.BusinessEntityID = em.BusinessEntityID WHERE (cc.IsAnOrderOlderThanAYearAgo = 1 AND cc.OrdersInPastYear = 0) OR (cc.OrdersInPastYear >= 3) OR (cc.RecentOrderFromDefinedCategory = 1) ORDER BY cc.CustomerID; END |
Total cost (in terms of line count): 10 additional lines (20%). Character count is actually slightly lower: 1,845 -> 1,793. But the improvement to readability, maintainability, and grokability: priceless.
What About Performance?
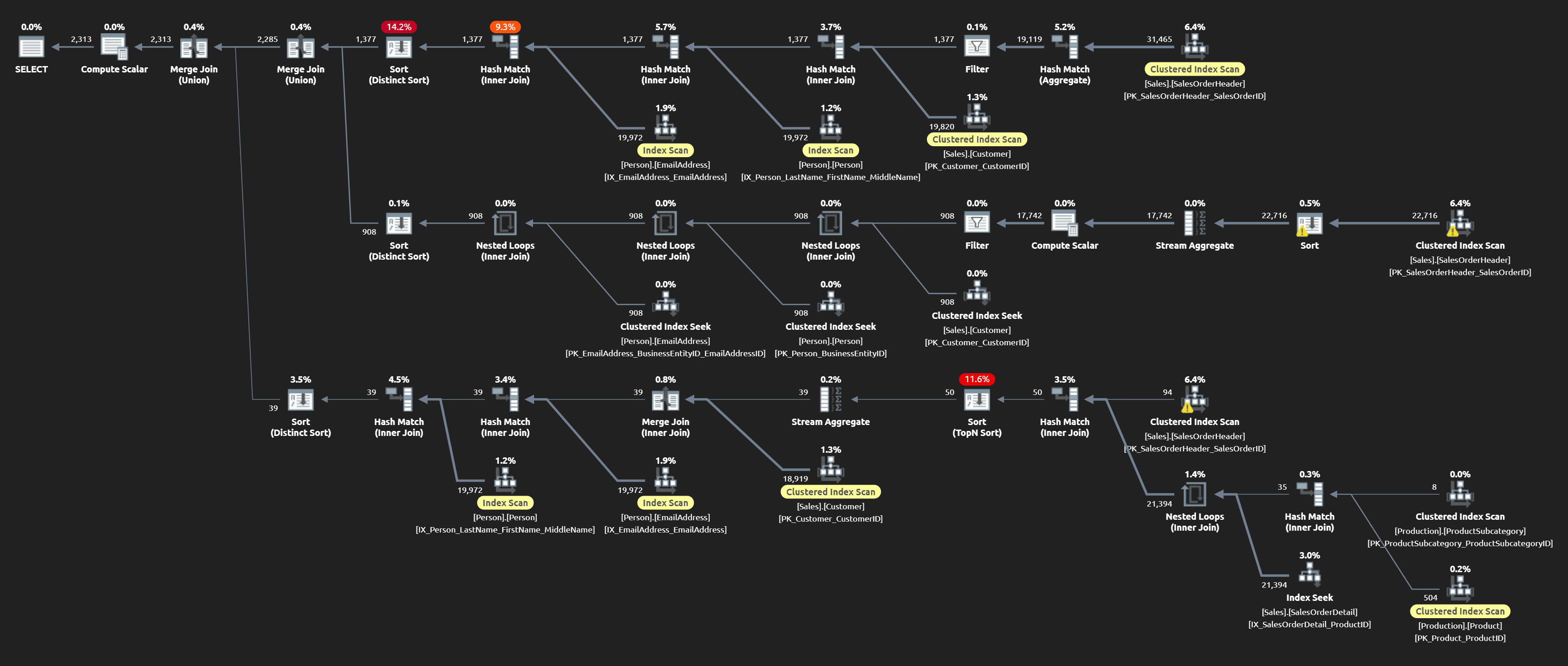
After confirming that they return the same results, I compared execution times and a few plan characteristics. Here are the raw metrics observed at runtime (click to enlarge):

On my system, which has modern NVMe drives, the original query is a lot faster than I thought (even with a cold cache). But notice the much higher number of reads, which could be an issue on systems with slower or more contentious I/O, or not enough memory to always have the data in the buffer pool. Let’s look at the execution plans a little closer.
For the old query, here is the plan (click to enlarge):
And here is the new plan, which is far simpler (click to enlarge):
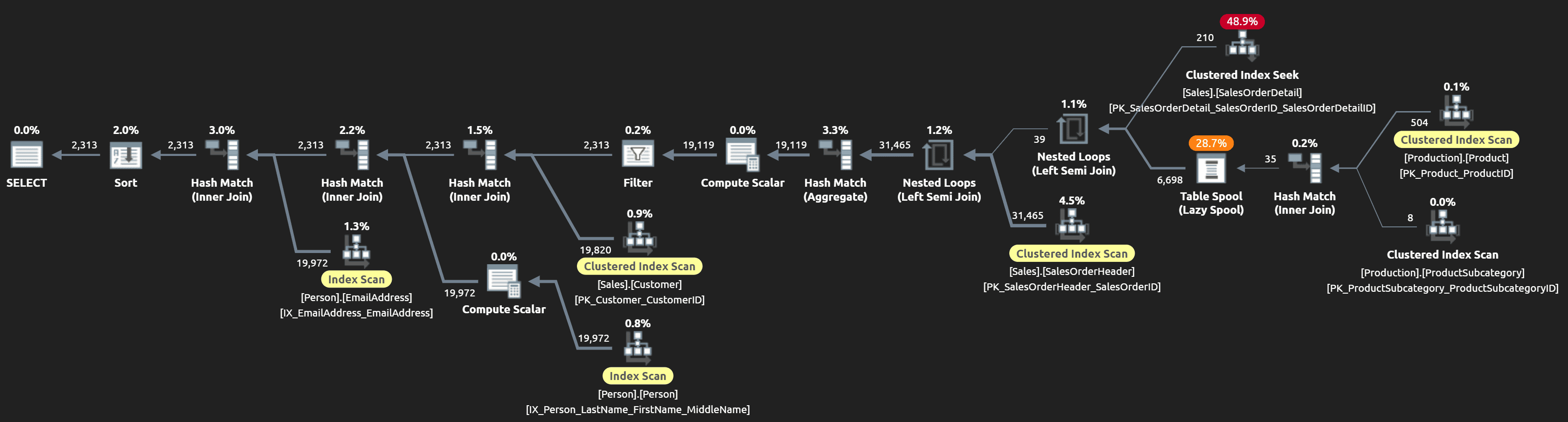
You can get a general sense for the differences by looking at the plans casually, but we can also take a quantitative comparison of the operators and other information the plans provide (with the worse figure highlighted in this salmon-y color):
| Metric | Original | New | Notes |
|---|---|---|---|
| Estimated Cost % | 40.9% | 59.1% | Given everything else below, this demonstrates why estimated cost % can be misleading (a.k.a. garbage). |
| Estimated Rows (Actual: 2,313) |
25,700 1,111% |
6,920 299% |
Neither estimate was a bullseye, but the UNION query was off by more than an order of magnitude. |
| Reads | 9,626 | 1,902 | This can be a good warning for systems that are I/O-bound and/or memory-bound. |
|
Clustered Index Scans
|
7 | 4 | Scans against SalesOrderHeader: 3 vs. 1 |
| Hash Matches | 8 | 5 | This can be a good warning for systems that are memory-bound (more info). |
| Sorts | 5 | 1 | And one sort in each plan (the final ORDER BY) isn’t necessary. |
| Spills | 1 | 0 | There was one level 2 spill in the original plan, nothing disastrous; likely a result of bad estimates. |
| Spools | 0 | 1 | The spool in the new plan is the only operator that is concerning – it only handles ~7K rows, but represents 13% of overall CPU. |
| Residual I/O Warnings | 2 | 0 | These are two bright yellow signs that the original query is reading a lot more data than it should. |
Given all that, there’s very little redeeming about the original approach to union three separate queries – and I would still feel that way even without the unnecessary distinct sorts. The code review created a much more readable procedure and made the query perform better in nearly every measurable aspect. And it could potentially be tuned even further, even though a one-off lead generation procedure isn’t likely to be performance critical. The important thing is that making these conventions and processes commonplace will make it more likely that the next procedure won’t face such a rigorous review.
What If The Problems Aren’t Obvious?
As I stated at the beginning, I’ve developed a sense of code smells and best practices through experience over my entire career, and I’m still adjusting my techniques. So nobody expects you to be able to spot all of these problems out of the gate. One way to get a head start is to try out an add-in like SQL Prompt, which certainly did identify several of the above issues.
Read also: SQL naming conventions
Wrapping Up
Now, would I torture a co-worker with a code review this thorough and pedantic? Of course not. But if the code raises my left eyebrow this many times, now I have a blog post I can point them at. 🙂
Fast, reliable and consistent SQL Server development…
FAQs: Common SQL Server stored procedure problems
1. What are the most common stored procedure problems in SQL Server?
The most frequent issues include: missing SET NOCOUNT ON (causes extra result sets), no error handling (TRY/CATCH), inconsistent naming conventions (sp_ prefix, mixed case), non-sargable WHERE clauses (wrapping columns in functions), using SELECT instead of SET for variable assignment, missing schema qualification (dbo.), using SELECT * instead of named columns, and not specifying varchar/decimal precision. These are coding standards issues – the procedure runs but is fragile and hard to maintain.
2. How do you do a stored procedure code review in SQL Server?
Review line by line checking: (1) Does it SET NOCOUNT ON? (2) Is there TRY/CATCH error handling? (3) Are all objects schema-qualified? (4) Are naming conventions consistent? (5) Are WHERE clauses sargable? (6) Is UNION ALL used instead of UNION where duplicates aren’t possible? (7) Are temp tables properly indexed and cleaned up? (8) Does the execution plan show unexpected scans or sorts? Tools like SQL Prompt can automate detection of many of these issues.
3. Should stored procedures use SET or SELECT for variable assignment in SQL Server?
Use SET. SET is the ANSI standard, assigns one variable at a time, and returns NULL if the query returns no rows (making errors detectable). SELECT can assign multiple variables in one statement but silently keeps the previous value if no rows are returned, which can cause subtle bugs. The only exception: if you need to assign multiple variables from the same row for performance, SELECT is slightly more efficient – but document why.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments