
It is always an afterthought. New objects are created that start off small and current. New feature development takes over and the recently architected data structures become old news. Over time, data grows and suddenly a previously small table contains millions or billions of rows.
Is all that data necessary? How long should it be retained for? If there is no answer to this question, then the actuality may be “Forever”, or more honestly “No one knows for sure.”
Retention takes on many forms and this article dives into ways in which data can be managed over time to ensure that it is fast, accurate, and readily available.
Note: the code for this article can be found here.
The Common Scenario
A new feature has been added and it requires verbose logging, which will provide troubleshooting information, as well as useful usage data that can be crunched in the future. The following is how this table might look:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE dbo.OrderChangeLog ( OrderChangeLogID INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_OrderChangeLog PRIMARY KEY CLUSTERED, OrderID INT NOT NULL, CustomerID INT NOT NULL, ModifiedDateTime DATETIME NOT NULL, ModifiedByPersonID INT NOT NULL, ChangeRequestAPIDetails VARCHAR(MAX) NOT NULL, BatchNumber INT NOT NULL, ColumnChanged VARCHAR(128) NOT NULL, OldValue VARCHAR(MAX) NULL, NewValue VARCHAR(MAX) NULL ); |
If you have ever worked with a log table, then some of this will no doubt look familiar. Alongside some basic information as to who made the change and when, there is extensive detail documenting exactly what happened and why. Given that there are three strings of MAX length, a row could conceivably be quite large.
In development, this data set starts off small. Orders are created, modified, completed, and deleted, and the log table accumulates some data that spans the lifecycle of the software release. This typically would be a few weeks or months. Once released, the new feature performs equally well, and the development team moves on to new projects.
Six months later, complaints come in that making changes to orders is slow. The issue is tracked back to this log table containing what has grown to be over a billion rows of verbose data, consuming hundreds of gigabytes of space (or in reality, much more maybe?). To further complicate this problem, some new reports were written that expose this data to end-users. Prior to this, the log data existed solely for internal troubleshooting and posterity.
Now what?
This is the problem. Since no one defined the lifecycle of this data, the administrator will likely be hesitant to just delete considerable amounts of it. What if it was required for some regulatory reason? Note that this is really common with logging type data, but it pertains to data of all types. Do you need an order for a cheeseburger from 1966 in your database? Or for a toaster in 2008? Of for that matter, any item sold last week? The latter is probably more likely to be “yes”, but it isn’t necessarily so.
What is Retention?
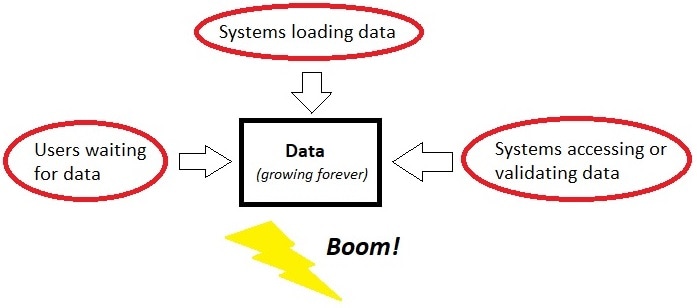
This diagram illustrates (with a pinch of humor) what happens to data that grows forever unchecked. The purpose of retention is to carefully architect how data is stored so that it remains highly available, even as it grows in size and complexity over time.
There are many techniques that can be used to make data more manageable as it grows. Some require organizational support to implement, whereas others are completely technical in nature, and can be completed via data engineering or development. The following are a wide variety of strategies that can be used to improve data usability, even when it grows to an enormous size.
Create a Retention Period
A retention period specified how long data will be maintained in its current form. Oftentimes, (and ideally in all cases,) data is only needed as-is for a set period, after which it can be deleted, moved, compressed, archived, or something else.
I firmly believe that when data is architected that has any chance of growing large, a retention period should be defined up-front and documented. A retention period can be “Forever”. This is 100% acceptable. The knowledge that data will be maintained as-is forever provides valuable information. That knowledge can be used to ensure that those data structures are built with a future of big data in mind. (Of course, forever typically just means that data growth is not tremendous so we will leave it to the future to deal with!)
Retention periods can be any amount of time and will vary greatly based on the type of data being discussed. Some common examples are:
- Temporary Data: This includes session data, temporary report parameters, temporary filter properties, etc…This data is needed for a specific purpose, after which it is disposable. This type of data can be stored in temporary objects, memory-optimized tables, or other structures that are automatically dropped when their purpose is fulfilled.
- Short-Term Data: Data that is needed for minutes or hours and is critical for operational or short-term application needs. A retention period for this sort of data would be either a short time span, or when processes using the data are complete. This data likely needs to be durable but might not need to be. It may also be tolerant of delayed durability.
- Mid-Term Data: This is data that needs to be retained for days or weeks. It may be part of ETL processes, log tables, email metadata, or other processes that are important, but in no way long-term or permanent in nature. This data may be tolerant of compression and other space-saving strategies.
- Long-Term Data: Data that should be retained for months or years. Not only can it get quite large, but it may consist of a mix of OLAP and OLTP processes. Depending on usage, it will likely benefit from a combination of different data architecture strategies. Because it can get large, it is helpful to understand if the RPO and RTO for this data is the same, regardless of its age.
- Indefinite/Forever Data: Some data needs to be saved forever. This may be because users may need to go back and validate old data. It may be due to legal or contractual obligations. Regardless of reason, this is data that can grow massive and needs to be managed in a way that ensures that is stays usable. Oftentimes, this data will be analytic in nature, but this will not always be the case.
- Defining retention periods up-front not only ensures a more appropriate data architecture, but it also avoids inconsistencies. Without a policy, it is possible that an operator may delete old data in response to a performance problem, user request, or some other unusual evet. Once this begins to happen, then the retention period for that data becomes a giant question mark:
Data mysteries are typically not fun to tackle. This specific type of mystery is one that will end up poorly documented if anyone bothers to document it at all. The result is that this informal data retention event lives on only in the brain of an operator, destined to be forgotten or misinterpreted.
A Note on RPO, RTO, and Availability
Data retention is directly linked to the concepts of RPO and RTO. Availability is equally important to anyone that will be consuming data in any form. Therefore, there is value in briefly reviewing what these terms mean.
RPO: Recovery Point Objective. In the event of a disaster, data incident, outage, or any other unusual hardware or software problem, RPO describes the maximum amount of data that will be lost.
While many executives will want the RPO for their applications to be near-zero, maintaining that minimal amount of data loss is very expensive. In reality, RPO is based on operational processes such as replication, Availability Groups, snapshots, or backups.
RTO: Recovery Time Objective. In the event of a disaster, data incident, outage, or any other unusual hardware or software problem, RTO describes the maximum amount of time needed for a system to return to its normal operation.
To briefly summarize the above descriptions: RTO is how long users have to wait for an outage to end, whereas RPO is how much data could be lost via that outage.
Retention Strategies
There are a wide variety of strategies that can be used to convert unwieldy and large data into manageable data. The table provided earlier in this article will be used to demonstrate each option. The column ModifiedDateTime will be used to evaluate any changes made via retention. The following are many common strategies:
Deletion of Data
The simplest form of retention is to delete data that is outside of the retention period. When an organization decides that data is no longer needed in any form, then deleting it provides relief by reducing data size and maintaining that reduction indefinitely. If retention of 12 months was implemented against the ModifiedDateTime column, then a recurring job could execute that deletes any data older than 12 months.
The following code example would be one way to accomplish this task:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DELETE TOP (1000) OrderChangeLog FROM dbo.OrderChangeLog WHERE OrderChangeLog.ModifiedDateTime <= DATEADD(MONTH, -12, GETUTCDATE()); WHILE @@ROWCOUNT > 0 BEGIN DELETE TOP (1000) OrderChangeLog FROM dbo.OrderChangeLog WHERE OrderChangeLog.ModifiedDateTime <= DATEADD(MONTH, -12, GETUTCDATE()); END; |
The code above deletes 1000 rows from OrderChangeLog and then continues to do so, as long as rows are being deleted. The batch size is customizable and should be based on data size. 1000 rows is arbitrary and that number can be adjusted lower for a table with very wide rows or higher for a table with narrow rows. Also consider the impact on the transaction log as each DELETE statement will be logged. Therefore, deleting one million rows at one time will generate a larger transaction that could cause log growth and delays while being committed.
Archiving Data
Some organizations no longer require older data for production use but want to maintain it somewhere for posterity. Often data is retained for legal or contractual reasons. Sometimes it is retained “just in case”. Regardless of reason, archival of data allows it to be removed from its source location and moved somewhere else.
A benefit of data archival is that while the production data source may be housed on expensive hardware, the archival destination will usually have less stringent requirements. Archived data can often be treated as cool/cold data, rather than as time-sensitive/mission-critical application data. This translates directly into resource and cost savings. The destination for archived data may not even need to be a database server. It could be a file server or some other easy-to-manage location.
This code illustrates one way to archive data older than 12 months, including the creation of the archive table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
CREATE TABLE dbo.OrderChangeLogArchive ( OrderChangeLogID INT NOT NULL CONSTRAINT PK_OrderChangeLogArchive PRIMARY KEY CLUSTERED WITH (DATA_COMPRESSION = PAGE), OrderID INT NOT NULL, CustomerID INT NOT NULL, ModifiedDateTime DATETIME NOT NULL, ModifiedByPersonID INT NOT NULL, ChangeRequestAPIDetails VARCHAR(MAX) NOT NULL, BatchNumber INT NOT NULL, ColumnChanged VARCHAR(128) NOT NULL, OldValue VARCHAR(MAX) NULL, NewValue VARCHAR(MAX) NULL ); GO DELETE TOP (1000) OrderChangeLog OUTPUT DELETED.OrderChangeLogID, DELETED.OrderID, DELETED.CustomerID, DELETED.ModifiedDateTime, DELETED.ModifiedByPersonID, DELETED.ChangeRequestAPIDetails, DELETED.BatchNumber, DELETED.ColumnChanged, DELETED.OldValue, DELETED.NewValue INTO dbo.OrderChangeLogArchive WHERE OrderChangeLog.ModifiedDateTime <= DATEADD(MONTH, -12, GETUTCDATE()); WHILE @@ROWCOUNT > 0 BEGIN DELETE TOP (1000) OrderChangeLog OUTPUT DELETED.OrderChangeLogID, DELETED.OrderID, DELETED.CustomerID, DELETED.ModifiedDateTime, DELETED.ModifiedByPersonID, DELETED.ChangeRequestAPIDetails, DELETED.BatchNumber, DELETED.ColumnChanged, DELETED.OldValue, DELETED.NewValue INTO dbo.OrderChangeLogArchive WHERE OrderChangeLog.ModifiedDateTime <= DATEADD(MONTH, -12, GETUTCDATE()); END |
Note that the IDENTITY attribute was removed from OrderChangeLogID, as this value will be taken directly from the source table. Therefore, there is no need to modify or create a value for it. Using DELETE coupled with OUTPUT DELETED allows for data to be deleted from the source table and inserted into the archive table in a single step, which simplifies code and allows the operation to be more atomic than if we were to write these as separate steps. Lastly, the archive table is page compressed, to save space. Since it presumably will not by modified via UPDATE statements, this is a safe way to save storage, memory, and speed up data access.
If this table were to be exceptionally large, there may also be value in partitioning it. This would allow for more efficient maintenance operations, if sheer table size became problematic. The archive table does not need to reside in the same database or even the same server. Some organizations prefer archived data to be sent to reporting/analytics environments, to a data lake, or some other less expensive environment. This decision would be based on who needs the data and how often it would be needed.
Delete Specific Dimensions
Sometimes historical data is important, but not all parts of it are needed once enough time has passed. For example, consider the table discussed earlier:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE dbo.OrderChangeLog ( OrderChangeLogID INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_OrderChangeLog PRIMARY KEY CLUSTERED, OrderID INT NOT NULL, CustomerID INT NOT NULL, ModifiedDateTime DATETIME NOT NULL, ModifiedByPersonID INT NOT NULL, ChangeRequestAPIDetails VARCHAR(MAX) NOT NULL, BatchNumber INT NOT NULL, ColumnChanged VARCHAR(128) NOT NULL, OldValue VARCHAR(MAX) NULL, NewValue VARCHAR(MAX) NULL ); |
Within this table are three VARCHAR(MAX) columns that can potentially be very large. The remaining columns are relatively small and limited in size. A common retention scenario occurs when the logging of changes is critical, but the extensive details are no longer needed after some period. In this table, the column ChangeRequestAPIDetails is likely to be the largest column as it will contain some sort of detail regarding API calls. Whether stored as XML, JSON, test, or some other format, let us consider the scenario where this is by and far the widest column in the table by a significant margin.
For an organization where knowledge of change is critical, but complete detail becomes unneeded after a year, a retention process could be implemented that sets the column ChangeRequestAPIDetails to NULL, blank, or some other trivial value that indicates that the data was removed for retention purposes.
By clearing out the largest column(s) in a table, a significant amount of space can be saved, especially if the table is also the target of compression. The result is a table that still provides extensive history but omits detail that does not need to be saved forever.
A process to do this would be very similar to retention processes introduced earlier:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
UPDATE TOP (1000) OrderChangeLog SET ChangeRequestAPIDetails = NULL FROM dbo.OrderChangeLog WHERE OrderChangeLog.ModifiedDateTime <= DATEADD(MONTH, -12, GETUTCDATE()) AND OrderChangeLog.ChangeRequestAPIDetails IS NOT NULL; WHILE @@ROWCOUNT > 0 BEGIN UPDATE TOP (1000) OrderChangeLog SET ChangeRequestAPIDetails = NULL FROM dbo.OrderChangeLog WHERE OrderChangeLog.ModifiedDateTime <= DATEADD(MONTH, -12, GETUTCDATE()) AND OrderChangeLog.ChangeRequestAPIDetails IS NOT NULL; END; |
This is another effective way to reduce the footprint of historical data when specific columns are quite large and are no longer needed once outside of a prescribed retention period.
Data Compression
When data is older and less often used, compression is an excellent way to save on storage space, memory, and often speed up queries against it. While a full discussion of row and page compression is out-of-scope for this article, Microsoft has extensive documentation on the implementation and best practices for each: https://learn.microsoft.com/en-us/sql/relational-databases/data-compression/data-compression?view=sql-server-ver16
So long as archived data is expected to not be updated often (or ever), page compression would be the most likely candidate to use on it. Page compression can reduce the footprint of repetitive data by 50%-75% or sometimes more. Compression ratios are based on the data types, values, and repetitiveness of the underlying data. For administrators or developers interested in estimating the impact of compression prior to implementation, they may use the system stored procedure sp_estimate_data_compression_savings.
Columnstore compression (and columnstore archive compression) are also viable alternatives for compressing archived data. There are more caveats as to which data profiles are ideal for columnstore compression. Ideally, columnstore compressed data should be narrower, repetitive, and somewhat similar to data warehouse-style data. That being said, it is intended for analytic data. Columnstore indexes will underperform on highly transactional data. More info on columnstore indexes can be found in this hands-on series on SimpleTalk.
Partitioning a Table
Partitioning allows a table to be physically split up by a specific dimension or set of dimensions, allowing each partition to be managed separately. This allows for faster and easier maintenance operations, as well as potentially improved performance.
In a table that blends OLTP and OLAP, oftentimes the recent data is the target of most transactional operations, whereas the older data is the target of analytic operations (if it is even accessed often).
Relating to retention, the most significant benefits of partitioning are:
- The ability to compress each partition differently. This allows active data to remain uncompressed whereas less active data can be row or page compressed.
- Partition truncation and range splits/merges can be used to quickly delete old data via truncation. The details of how to automate sliding partition ranges are out of scope for this article, but there is significant documentation on partitioning, as well as how to configure dynamic partition ranges. Microsoft’s documentation is a great place to start: https://learn.microsoft.com/en-us/sql/relational-databases/partitions/partitioned-tables-and-indexes?view=sql-server-ver16
Partition elimination allows queries against a partitioned table to automatically skip reading data from partitions that do not match a filter criteria against the partition column(s). This is typically not the primary reason to partition a table, but it can provide a significant performance boost for tables that have a limited set of active data and an extensive set of inactive data, such as tables that are targeted with retention policies.
Partitioned tables require some components to be used:
- Partition Function: Defined the boundaries that will be used to divide data up based on a key column or columns.
- Partition Scheme: Determines which filegroups will be used to store data based on the details of the partition function.
- Database Filegroups and Files: Data in a partitioned table can be stored in any filegroup or file, but the ideal way to do so is to have a separate filegroup/file for each partition. This allows each partition to be managed separately without impacting other data.
The following is a simple example of how to partition the table introduced earlier in this article:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
ALTER DATABASE WideWorldImporters ADD FILEGROUP WideWorldImporters_2022_fg; ALTER DATABASE WideWorldImporters ADD FILEGROUP WideWorldImporters_2023_fg; ALTER DATABASE WideWorldImporters ADD FILEGROUP WideWorldImporters_2024_fg; ALTER DATABASE WideWorldImporters ADD FILEGROUP WideWorldImporters_2025_fg; ALTER DATABASE WideWorldImporters ADD FILEGROUP WideWorldImporters_2026_fg; ALTER DATABASE WideWorldImporters ADD FILE (NAME = WideWorldImporters_2022_data, FILENAME = 'C:\SQLData\WideWorldImporters_2022_data.ndf', SIZE = 100MB, MAXSIZE = UNLIMITED, FILEGROWTH = 500MB) TO FILEGROUP WideWorldImporters_2022_fg; ALTER DATABASE WideWorldImporters ADD FILE (NAME = WideWorldImporters_2023_data, FILENAME = 'C:\SQLData\WideWorldImporters_2023_data.ndf', SIZE = 100MB, MAXSIZE = UNLIMITED, FILEGROWTH = 500MB) TO FILEGROUP WideWorldImporters_2023_fg; ALTER DATABASE WideWorldImporters ADD FILE (NAME = WideWorldImporters_2024_data, FILENAME = 'C:\SQLData\WideWorldImporters_2024_data.ndf', SIZE = 100MB, MAXSIZE = UNLIMITED, FILEGROWTH = 500MB) TO FILEGROUP WideWorldImporters_2024_fg; ALTER DATABASE WideWorldImporters ADD FILE (NAME = WideWorldImporters_2025_data, FILENAME = 'C:\SQLData\WideWorldImporters_2025_data.ndf', SIZE = 100MB, MAXSIZE = UNLIMITED, FILEGROWTH = 500MB) TO FILEGROUP WideWorldImporters_2025_fg; ALTER DATABASE WideWorldImporters ADD FILE (NAME = WideWorldImporters_2026_data, FILENAME = 'C:\SQLData\WideWorldImporters_2026_data.ndf', SIZE = 100MB, MAXSIZE = UNLIMITED, FILEGROWTH = 500MB) TO FILEGROUP WideWorldImporters_2026_fg; GO CREATE PARTITION FUNCTION OrderChangeLogPartitioned_years_function (DATE) AS RANGE RIGHT FOR VALUES ('2023-01-01', '2024-01-01', '2025-01-01', '2026-01-01'); GO CREATE PARTITION SCHEME fact_order_BIG_CCI_years_scheme AS PARTITION OrderChangeLogPartitioned_years_function TO (WideWorldImporters_2022_fg, WideWorldImporters_2023_fg, WideWorldImporters_2024_fg, WideWorldImporters_2025_fg, WideWorldImporters_2026_fg); GO CREATE TABLE dbo.OrderChangeLogPartitioned ( OrderChangeLogID INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_OrderChangeLogPartitioned PRIMARY KEY CLUSTERED, OrderID INT NOT NULL, CustomerID INT NOT NULL, ModifiedDateTime DATETIME NOT NULL, ModifiedByPersonID INT NOT NULL, ChangeRequestAPIDetails VARCHAR(MAX) NOT NULL, BatchNumber INT NOT NULL, ColumnChanged VARCHAR(128) NOT NULL, OldValue VARCHAR(MAX) NULL, NewValue VARCHAR(MAX) NULL ) ON fact_order_BIG_CCI_years_scheme (ModifiedDateTime); |
The code above performs the following tasks:
- Creates 5 filegroups to logically store data from the partitioned table. These can be shared with other partitioned tables as time periods overlap.
- Creates 5 files to physically store data for the filegroups created above.
- Creates a partition function to split the data up logically based on date ranges.
- Creates a partition schema to determine where data should be stored based on the details of the partition function.
- Creates a table on the partition scheme, rather than on
PRIMARY.
When data is inserted into the partitioned table, it will be stored in the data file corresponding to the value of ModifiedDateTime automatically. From here, there is a wide variety of options that open up, allowing partitions to be manipulated independently of each other, like this:
|
1 2 3 4 5 6 |
TRUNCATE TABLE dbo.OrderChangeLogPartitioned WITH (PARTITIONS(1)); ALTER INDEX PK_OrderChangeLogPartitioned ON dbo.OrderChangeLogPartitioned REBUILD PARTITION = 4 WITH (DATA_COMPRESSION = PAGE); |
Being able to truncate a partition allows retention to be applied to a table without the need to delete rows and consume time and transaction log space. Being able to perform index maintenance and only target a current partition (rather than historical data) will reduce the time and resources needed to perform that maintenance.
Turn Old OLTP Data into OLAP Data
Oftentimes, as data transitions from being hot to warm and then to cool/cold, its purpose shifts from transactional to analytic in nature. What used to be data that was frequently inserted, updated, and deleted, is now read-only and only a small fraction of it is used at any one time.
In these scenarios, consider storing this data as analytic data, rather than as transactional. This provides more flexibility to you to choose an analytic storage solution that maximizes compression, read speeds, and whatever indexing/optimizations support the reads that will occur against it. In this case, the data will be used in fundamentally different ways. Therefore, it can be stored in a fundamentally different way.
If the data needs to remain in SQL Server, consider columnstore indexes or page compression to maximize space/memory savings. Also consider removing any unneeded covering indexes that used to support transactional activities, but now are no longer applicable.
If the data can leave SQL Server, then consider whatever solutions your organization already has available for large, relatively static analytic data. Solutions such as Synapse Analytics, Fabric, a data warehouse, Azure Databricks, and others are all potential options. Which you choose will be based on your own skill set and the tools available to your organization.
Other Options
These are some of the more common retention methods and their application in SQL Server. There are many other ways to manage retention, including third-party applications, hardware solutions, hosted data management platforms, and more. Choose the retention plan that fits your environment best, as it may be a single option discussed here or a combination of many.
A Note on Retention Process Timing and Impact
Any process that manipulates large amounts of data should be isolated to the safest time possible to run. This may be overnight, early in the morning, on a weekend, or during some other quiet time. Retention should not negatively impact the systems they service.
In a highly transactional environment, changes should occur at times when the fewest users are trying to access the impacted data. Any data manipulation should be batched to avoid locking underlying objects and blocking other users from accessing them. In most OLTP systems, this ideal time is late in the evening or early in the morning. In geo-located or distributed/global systems, retention timing can be customized based on the time zone or other usage details.
In an analytic environment, retention changes should occur either as part of data load processes or at times when they will not conflict with data loads. Similarly, if retention could impact analytics, then those processes should run when as few analytic processes are expected to run. Since administrators generally have more control over OLAP environments, finding a good time to implement retention processes will often be simpler than in buys transactional environments.
The Magic of Retention Policies
Understanding retention methods is helpful, but without a formal agreement between business stakeholders and those responsible for its data, retention will not exist in a meaningful way.
A retention policy is an official contract between a business, its users, its employees, and any other stakeholders that determines how long data will be retained. The details of this policy might be simple, or they may be nuanced and complex.
For example, an organization might decide that any transactional data older than 10 years can be deleted forever. This retention policy sounds quite simple and would be documented so that all stakeholders have access to it and understand it. However, you do have to be careful with things like product data, which, unlike transactional data that records Bob from Hoboken purchasing a red shelf set, may have a lifecycle greater than 10 years.
Retention policies are often referenced in contracts, data privacy agreements, or other terms-of-service agreements. Note that determining what data is 10 years or older might be complex:
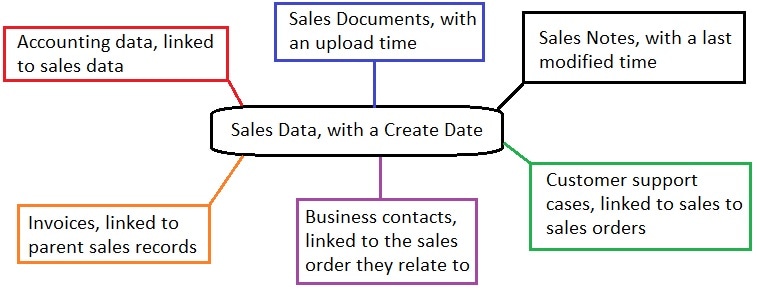
In this image, it becomes clear that some technical decision-making will be required to determine exactly what “10 years of retention” means, but this is a question that can be answered with some patience and diligence.
If the question is asked: “How long is this data kept for?”, the answer should be, “it is in the retention policy” (or something similar). Without a policy, no one knows for sure. Without a policy, the answer can be murky:
- “We keep this data forever. I think(?)”
- We keep this data for 2 years. This undocumented process handles it!
- We keep the data forever, but sometimes delete an arbitrary amount when performance issues arise.
- We keep this data for 1 year. Except on this one legacy server where it is 2 years. And for these 10 customers where it is 3 years. Our subject-matter expert knows all of this, so it is OK.
Any conversation remotely like these should leave us feeling a bit queasy. The uncertainty is the problem and the solution is a policy to remove the need for guesswork. With a policy, the answer to “How long is this data kept for?” will be one of two possible answers:
- It is in the retention policy: right here.
- It is not in the retention policy. We will decide on a retention period and add it to the policy.
A retention policy is the final step to solving the problem introduced in this article – so do not skip it! In general, organizations may be hesitant to apply retention at first, but once they understand that this is not as hard as it seems, they’ll warm up to the idea and become more open to it over time.
Keep in mind that a retention policy can state that certain data is retained indefinitely. This is 100% acceptable. As long as the organization acknowledges this fact and will ensure that the hardware and software are available to support the size of forever-data, then it is OK. Having the policy that states this is far superior to having no policy and *thinking* that the data lasts forever when it may or not actually be accurate.
Conclusion
Retention is an important dimension of data architecture, development, and operations that allows data size and scope to remain manageable over time. Simple questions, research, and answers can help shape the retention periods for different objects and help ensure that the time period that data is retained for is aligned with its purpose within an application.
Retention policies formalize retention and ensure that retention details are communicated effectively to any stakeholders that may need to understand them. Retention without a retention policy often takes the form of unofficial, undocumented, or confusing processes that are known to some people, but not to others. A policy removes confusion and replaces it with fact.
As a bonus, being the author and enabler of a retention policy presents a leadership and collaboration opportunity that can be helpful to one’s career. These are all opportunities to improve an organization’s data, which will ultimately ensure that processes that use that data are more effective. This includes everything from applications to reports to AI. Good data ensures these applications are effective, whereas excessively large or confusing data can impede that progress.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments