
As a DBA and performance tuning consultant, for Ambient Consulting in Minneapolis, I’m often asked to analyze performance issues on a SQL Server instance with which I’m unfamiliar. It can be a daunting task. Let’s face it, most of the time companies do not have good documentation about their databases. Or if they do, it is outdated, or it takes a few days to locate and retrieve it.
In this article, I share a set of basic scripts that I’ve developed, over the years, which mine the metadata in the various system functions, stored procedures, tables, catalog views, and dynamic management views, Together, they reveal all the secrets of the databases on the instance, their size, file locations, and their design, including columns, data types, defaults, keys and indexes.
If you’ve been used to retrieving some of this information by clinging to the mouse with whited knuckles and stabbing at the screen, then I hope you’ll be pleasantly surprised at the wealth of information some of these simple scripts reveal, instantly.
As with any scripts, always test them before running them in a production environment. I recommend that you start first with one of the SQL Server sample databases like AdventureWorks or pubs that you can download from: AdventureWorksDW Databases – 2012, 2008R2 and 2008.
OK, enough preamble, just show me the scripts!
Exploring your Servers
We’ll start with some queries that offer the server-level view of your databases.
Basic Server Information
First, some simple @@functions that provide basic server information.
|
1 2 3 4 5 6 7 8 9 |
-- Server and instance name Select @@SERVERNAME as [Server\Instance]; -- SQL Server Version Select @@VERSION as SQLServerVersion; -- SQL Server Instance Select @@ServiceName AS ServiceInstance; -- Current Database Select DB_NAME() AS CurrentDB_Name; |
Listing 1: Basic server information
How long has your server been running since the last SQL Server startup? Note the tempdb system database is recreated every time the server restarts. Thus this is one method to tell when the database server was last restarted.
|
1 2 3 4 5 6 7 8 9 |
-- Note the tempdb system database is recreated every time the server restarts -- Thus this is one method to tell when the database server was last restarted SELECT @@Servername AS ServerName , create_date AS ServerStarted , DATEDIFF(s, create_date, GETDATE()) / 86400.0 AS DaysRunning , DATEDIFF(s, create_date, GETDATE()) AS SecondsRunnig FROM sys.databases WHERE name = 'tempdb'; GO |
Listing 2: how long has your server been running since startup?
Linked Servers
Linked Servers are database connections set up to allow communication from SQL Server to other data servers. Distributed queries can be ran against these linked servers. It’s good to know if your database server is an isolated self-contained database server or if there are links to other database servers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
EXEC sp_helpserver; --OR EXEC sp_linkedservers; --OR SELECT @@SERVERNAME AS Server , Server_Id AS LinkedServerID , name AS LinkedServer , Product , Provider , Data_Source , Modify_Date FROM sys.servers ORDER BY name; GO |
Listing 3: Linked Servers
List All Databases
First step is to take inventory of all the databases found on the server. Note the four or five system databases (master, model, msdb, tempdb, and distribution if you are using replication). You may want to exclude these system databases in future queries. It is very easy to see a list of database directly from SQL Server Management Studio SQL Server (SSMS). However, these simple database queries are building blocks for more complicated queries.
There are several ways to get a list of the databases in T-SQL, and Listing 4 presents just a few of them. Each method produces a similar result set, but with subtle differences.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
EXEC sp_helpdb; --OR EXEC sp_Databases; --OR SELECT @@SERVERNAME AS Server , name AS DBName , recovery_model_Desc AS RecoveryModel , Compatibility_level AS CompatiblityLevel , create_date , state_desc FROM sys.databases ORDER BY Name; --OR SELECT @@SERVERNAME AS Server , d.name AS DBName , create_date , compatibility_level , m.physical_name AS FileName FROM sys.databases d JOIN sys.master_files m ON d.database_id = m.database_id WHERE m.[type] = 0 -- data files only ORDER BY d.name; GO |
Listing 4: Database Inventory
Last Databases Backup?
Stop! Before you go any further, every good DBA should be certain they have recent database backup(s).
|
1 2 3 4 5 6 7 8 9 |
SELECT @@Servername AS ServerName , d.Name AS DBName , MAX(b.backup_finish_date) AS LastBackupCompleted FROM sys.databases d LEFT OUTER JOIN msdb..backupset b ON b.database_name = d.name AND b.[type] = 'D' GROUP BY d.Name ORDER BY d.Name; |
Listing 5: Last Database Backup
Better still if you know the physical file location of the last backups.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT @@Servername AS ServerName , d.Name AS DBName , b.Backup_finish_date , bmf.Physical_Device_name FROM sys.databases d INNER JOIN msdb..backupset b ON b.database_name = d.name AND b.[type] = 'D' INNER JOIN msdb.dbo.backupmediafamily bmf ON b.media_set_id = bmf.media_set_id ORDER BY d.NAME , b.Backup_finish_date DESC; GO |
Listing 6: Physical file location for recent backups
Active User Connections by Database
It’s a good idea to have an understanding of what databases are being used at any point in time, especially if you are experiencing performance problems.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Similar information can be derived from sp_who SELECT @@Servername AS Server , DB_NAME(database_id) AS DatabaseName , COUNT(database_id) AS Connections , Login_name AS LoginName , MIN(Login_Time) AS Login_Time , MIN(COALESCE(last_request_end_time, last_request_start_time)) AS Last_Batch FROM sys.dm_exec_sessions WHERE database_id > 0 AND DB_NAME(database_id) NOT IN ( 'master', 'msdb' ) GROUP BY database_id , login_name ORDER BY DatabaseName; |
Listing 7: Active connections by database
Basic Database Exploration
Let’s now drill down and see how we can gather information about the objects in each of our databases, using various catalog views and Dynamic management Views. Most of the queries presented in this section let’s look at the individual database so remember to change the current database in SSMS or by a Use database; command. Remember to you can always check the current default database with Select DB_NAME();.
The sys.objects system table is one of the key system tables for gathering a lot of information on the objects that comprise your data model, with sys.objects.type being the key column on which to filter.
|
1 2 3 4 5 6 7 |
-- In this example U is for tables. -- Try swapping in one of the many other types. USE MyDatabase; GO SELECT * FROM sys.objects WHERE type = 'U'; |
Listing 8: Listing out all user-defined tables in a database
The following table shows the list of objects types on which we can filter (see also the sys.objects documentation on Microsoft’s MSDN website).
|
sys.objects.type |
||
|
AF = Aggregate function (CLR) |
P = SQL Stored Procedure |
TA = Assembly (CLR) DML trigger |
|
C = CHECK constraint |
PC = Assembly (CLR) stored-procedure |
TF = SQL table-valued-function |
|
D = DEFAULT (constraint or stand-alone) |
PG = Plan guide |
TR = SQL DML trigger |
|
F = FOREIGN KEY constraint |
PK = PRIMARY KEY constraint |
TT = Table type |
|
FN = SQL scalar function |
R = Rule (old-style, stand-alone) |
U = Table (user-defined) |
|
FS = Assembly (CLR) scalar-function |
RF = Replication-filter-procedure |
UQ = UNIQUE constraint |
|
FT = Assembly (CLR) table-valued function |
S = System base table |
V = View |
|
IF = SQL inline table-valued function |
SN = Synonym |
X = Extended stored procedure |
|
IT = Internal table |
SQ = Service queue |
|
Other catalog views, such as sys.tables and sys.views, inherit from sys.objects and provide the information for that particular object type. With these views, plus the OBJECTPROPERTY metadata function, we can uncover a great deal of information on each of the objects that make up our database schemas.
Database File Location
Physical location and drive of the current database file, including the master database file (*.mdf) and the Log database file (*.ldf) can be found using these queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
EXEC sp_Helpfile; --OR SELECT @@Servername AS Server , DB_NAME() AS DB_Name , File_id , Type_desc , Name , LEFT(Physical_Name, 1) AS Drive , Physical_Name , RIGHT(physical_name, 3) AS Ext , Size , Growth FROM sys.database_files ORDER BY File_id; GO |
Listing 9: Physical file location of the current database
Tables
Of course, the Object Explorer in SSMS provides a convenient list of the tables in a specific database, but using scripts we can unveil information that isn’t easily available via the GUI. The ANSI Standard approach is to use the INFORMATION_SCHEMA views, but they won’t return information regarding objects that are not part of the Standard (such as triggers, extended properties, and so on), so use of the SQL Server Catalog views is common.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
EXEC sp_tables; -- Note this method returns both table and views. --OR SELECT @@Servername AS ServerName , TABLE_CATALOG , TABLE_SCHEMA , TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE' ORDER BY TABLE_NAME ; --OR SELECT @@Servername AS ServerName , DB_NAME() AS DBName , o.name AS 'TableName' , o.[Type] , o.create_date FROM sys.objects o WHERE o.Type = 'U' -- User table ORDER BY o.name; --OR SELECT @@Servername AS ServerName , DB_NAME() AS DBName , t.Name AS TableName, t.[Type], t.create_date FROM sys.tables t ORDER BY t.Name; GO |
Listing 10: Exploring table details
Row Counts for all Tables
If you know nothing about a table, all tables are equal. The more you know about the tables the more you can mentally begin to determine which tables are more important and which tables are less important. Generally speaking, tables with the largest number of rows tend to be the ones that suffer most often from performance issues.
From SSMS object explorer, we can right-click on any table name and select Properties, and view the Storage page will provide a row count for that table.
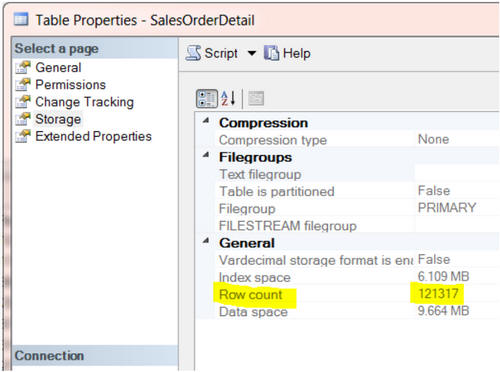
However, it’s hard to collect this information for all tables, manually. Likewise, the brute force approach of executing SELECT COUNT(*) FROM TABLENAME; for every table is likely to involve a lot of typing.
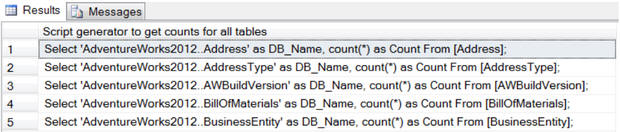
A much better approach is to use T-SQL as a script generator. The script in Listing 11 will generate a set of T-SQL statements to return the row count for each table in the current database. Simply execute it, then copy-and-paste the generated statements into the query window and execute them.
|
1 2 3 4 5 6 7 |
SELECT 'Select ''' + DB_NAME() + '.' + SCHEMA_NAME(SCHEMA_ID) + '.' + LEFT(o.name, 128) + ''' as DBName, count(*) as Count From ' + o.name + ';' AS ' Script generator to get counts for all tables' FROM sys.objects o WHERE o.[type] = 'U' ORDER BY o.name; GO |
Listing 11: A script to generate a script to return row counts for all tables
sp_msforeachtable
sp_msforeachtable is an undocumented Microsoft function that will loop through all the tables in a database executing a query, and replacing ‘?’ with each table name. There is also a similar database level function called sp_msforeachdb.
There are some known issues with these undocumented functions, as they do not handle special characters in the object names. For example, table or database names containing a dash character (“-“) will cause the stored procedure to fail.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE #rowcount ( Tablename VARCHAR(128) , Rowcnt INT ); EXEC sp_MSforeachtable 'insert into #rowcount select ''?'', count(*) from ?' SELECT * FROM #rowcount ORDER BY Tablename , Rowcnt; DROP TABLE #rowcount; |
Listing 12: Using sp_msforeachtable to return row counts for all tables
A faster way to get row counts – use the clustered index
All of the previous methods to return row counts for each table rely on use of COUNT(*), which performs poorly for tables with more than about 500K rows, in my experience.
A faster way to get table row counts is to get the record counts from the clustered index or heap partition. Note while this method is much faster, Microsoft has indicated the record count updates on indexes may not always match the record counts of the table, due to a delay in the index counts getting updated. In most cases they are exactly the same or very, very close and will be the same shortly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
-- A faster way to get table row counts. -- Hint: get it from an index, not the table. SELECT @@ServerName AS Server , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(p.object_id) AS SchemaName , OBJECT_NAME(p.object_id) AS TableName , i.Type_Desc , i.Name AS IndexUsedForCounts , SUM(p.Rows) AS Rows FROM sys.partitions p JOIN sys.indexes i ON i.object_id = p.object_id AND i.index_id = p.index_id WHERE i.type_desc IN ( 'CLUSTERED', 'HEAP' ) -- This is key (1 index per table) AND OBJECT_SCHEMA_NAME(p.object_id) <> 'sys' GROUP BY p.object_id , i.type_desc , i.Name ORDER BY SchemaName , TableName; -- OR -- Similar method to get row counts, but this uses DMV dm_db_partition_stats SELECT @@ServerName AS ServerName , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(ddps.object_id) AS SchemaName , OBJECT_NAME(ddps.object_id) AS TableName , i.Type_Desc , i.Name AS IndexUsedForCounts , SUM(ddps.row_count) AS Rows FROM sys.dm_db_partition_stats ddps JOIN sys.indexes i ON i.object_id = ddps.object_id AND i.index_id = ddps.index_id WHERE i.type_desc IN ( 'CLUSTERED', 'HEAP' ) -- This is key (1 index per table) AND OBJECT_SCHEMA_NAME(ddps.object_id) <> 'sys' GROUP BY ddps.object_id , i.type_desc , i.Name ORDER BY SchemaName , TableName; GO |
Listing 13: Return table row counts from the index or table partition
Finding Heaps (tables with no clustered index)
Working with heap tables is like working with a flat file, instead of a database. If you want to guarantee a full table scan for any and all queries, use a heap table. My general recommendation would be to add a primary key clustered index to all heap tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
-- Heap tables (Method 1) SELECT @@Servername AS ServerName , DB_NAME() AS DBName , t.Name AS HeapTable , t.Create_Date FROM sys.tables t INNER JOIN sys.indexes i ON t.object_id = i.object_id AND i.type_desc = 'HEAP' ORDER BY t.Name --OR -- Heap tables (Method 2) SELECT @@Servername AS ServerName , DB_NAME() AS DBName , t.Name AS HeapTable , t.Create_Date FROM sys.tables t WHERE OBJECTPROPERTY(OBJECT_ID, 'TableHasClustIndex') = 0 ORDER BY t.Name; --OR -- Heap tables (Method 3) also provides row counts SELECT @@ServerName AS Server , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(ddps.object_id) AS SchemaName , OBJECT_NAME(ddps.object_id) AS TableName , i.Type_Desc , SUM(ddps.row_count) AS Rows FROM sys.dm_db_partition_stats AS ddps JOIN sys.indexes i ON i.object_id = ddps.object_id AND i.index_id = ddps.index_id WHERE i.type_desc = 'HEAP' AND OBJECT_SCHEMA_NAME(ddps.object_id) <> 'sys' GROUP BY ddps.object_id , i.type_desc ORDER BY TableName; |
Listing 14: Finding heaps
Investigating Table Activity
Knowing which tables have the most reads and writes is another important piece of information when performance tuning your database. Previously, we examined queries to return the row counts for each table. The following examples show the number of table reads and writes.
Note these statistics from Dynamic Management Views are cleared out each time SQL Server restarts (wait and latch statistics can also be cleared out manually). The longer the server has been up, the more reliable the statistics. I have a lot more confidence with statistics that are over 30 days (assumes the tables have been through a month end cycle) and a lot less confidence if they are less than 7 days.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
-- Table Reads and Writes -- Heap tables out of scope for this query. Heaps do not have indexes. -- Only lists tables referenced since the last server restart SELECT @@ServerName AS ServerName , DB_NAME() AS DBName , OBJECT_NAME(ddius.object_id) AS TableName , SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups) AS Reads , SUM(ddius.user_updates) AS Writes , SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups + ddius.user_updates) AS [Reads&Writes] , ( SELECT DATEDIFF(s, create_date, GETDATE()) / 86400.0 FROM master.sys.databases WHERE name = 'tempdb' ) AS SampleDays , ( SELECT DATEDIFF(s, create_date, GETDATE()) AS SecoundsRunnig FROM master.sys.databases WHERE name = 'tempdb' ) AS SampleSeconds FROM sys.dm_db_index_usage_stats ddius INNER JOIN sys.indexes i ON ddius.object_id = i.object_id AND i.index_id = ddius.index_id WHERE OBJECTPROPERTY(ddius.object_id, 'IsUserTable') = 1 AND ddius.database_id = DB_ID() GROUP BY OBJECT_NAME(ddius.object_id) ORDER BY [Reads&Writes] DESC; GO |
Listing 15: Read and write activity for all tables referenced since the last server restart, in a database
A more advanced version of the same query uses a cursor to consolidate the information for all Tables for all databases on the server. While I am not a fan of cursors due to their slow performance, navigating multiple databases does seem to be a good use for one.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
-- Table Reads and Writes -- Heap tables out of scope for this query. Heaps do not have indexes. -- Only lists tables referenced since the last server restart -- This query uses a cursor to identify all the user databases on the server -- Consolidates individual database results into a report, using a temp table. DECLARE DBNameCursor CURSOR FOR SELECT Name FROM sys.databases WHERE Name NOT IN ( 'master', 'model', 'msdb', 'tempdb', 'distribution' ) ORDER BY Name; DECLARE @DBName NVARCHAR(128) DECLARE @cmd VARCHAR(4000) IF OBJECT_ID(N'tempdb..TempResults') IS NOT NULL BEGIN DROP TABLE tempdb..TempResults END CREATE TABLE tempdb..TempResults ( ServerName NVARCHAR(128) , DBName NVARCHAR(128) , TableName NVARCHAR(128) , Reads INT , Writes INT , ReadsWrites INT , SampleDays DECIMAL(18, 8) , SampleSeconds INT ) OPEN DBNameCursor FETCH NEXT FROM DBNameCursor INTO @DBName WHILE @@fetch_status = 0 BEGIN ---------------------------------------------------- -- Print @DBName SELECT @cmd = 'Use ' + @DBName + '; ' SELECT @cmd = @cmd + ' Insert Into tempdb..TempResults SELECT @@ServerName AS ServerName, DB_NAME() AS DBName, object_name(ddius.object_id) AS TableName , SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups) AS Reads, SUM(ddius.user_updates) as Writes, SUM(ddius.user_seeks + ddius.user_scans + ddius.user_lookups + ddius.user_updates) as ReadsWrites, (SELECT datediff(s,create_date, GETDATE()) / 86400.0 FROM sys.databases WHERE name = ''tempdb'') AS SampleDays, (SELECT datediff(s,create_date, GETDATE()) FROM sys.databases WHERE name = ''tempdb'') as SampleSeconds FROM sys.dm_db_index_usage_stats ddius INNER JOIN sys.indexes i ON ddius.object_id = i.object_id AND i.index_id = ddius.index_id WHERE objectproperty(ddius.object_id,''IsUserTable'') = 1 --True AND ddius.database_id = db_id() GROUP BY object_name(ddius.object_id) ORDER BY ReadsWrites DESC;' --PRINT @cmd EXECUTE (@cmd) ----------------------------------------------------- FETCH NEXT FROM DBNameCursor INTO @DBName END CLOSE DBNameCursor DEALLOCATE DBNameCursor SELECT * FROM tempdb..TempResults ORDER BY DBName , TableName; --DROP TABLE tempdb..TempResults; |
Listing 16: Read and write activity for all tables referenced since the last server restart, in all databases
Views
Views are scripted queries that are stored in the database. You can think of them as virtual tables. Data is not stored in the view but we reference the view in our queries in exactly the same way we would reference a table.
In SQL Server, we can even, in some circumstances, update data through a view. To make a view read only, one trick is to use SELECT DISTINCT in the view definition. A view is only updateable if each row in the view maps unambiguously to a single row in the underlying table. Any view that fails this criteria, such as any view built on more than one table, or that uses grouping, aggregations, and calculations in its definition, will be read only.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
SELECT @@Servername AS ServerName , DB_NAME() AS DBName , o.name AS ViewName , o.[Type] , o.create_date FROM sys.objects o WHERE o.[Type] = 'V' -- View ORDER BY o.NAME --OR SELECT @@Servername AS ServerName , DB_NAME() AS DBName , Name AS ViewName , create_date FROM sys.Views ORDER BY Name --OR SELECT @@Servername AS ServerName , TABLE_CATALOG , TABLE_SCHEMA , TABLE_NAME , TABLE_TYPE FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'VIEW' ORDER BY TABLE_NAME --OR -- View details (Show the CREATE VIEW Code) SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , o.name AS 'ViewName' , o.Type , o.create_date , sm.[DEFINITION] AS 'View script' FROM sys.objects o INNER JOIN sys.sql_modules sm ON o.object_id = sm.OBJECT_ID WHERE o.Type = 'V' -- View ORDER BY o.NAME; GO |
Listing 17: Exploring views
Synonyms
A synonym is an “also known as (aka)” name for an object in the database. A few times in my career I have been asked to review a query only to be scratching my head trying to figure out the table to which the query is referring. For example, consider a simple query Select * from Client. I search for the table named Client but I can’t find it. OK, it must be a view then, search for view named Client and I still can’t find it. I must have the wrong database? Turns out Client is a synonym for a customer and the actual table is Customer. The marketing group wanted to refer to this table as Client so created a synonym. Thankfully, use of synonyms is rare, but they can cause confusion if you are not aware of them.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
-- which synonyms exist? SELECT @@Servername AS ServerName , DB_NAME() AS DBName , o.name AS ViewName , o.Type , o.create_date FROM sys.objects o WHERE o.[Type] = 'SN' -- Synonym ORDER BY o.NAME; --OR -- synonymn details SELECT @@Servername AS ServerName , DB_NAME() AS DBName , s.name AS synonyms , s.create_date , s.base_object_name FROM sys.synonyms s ORDER BY s.name; GO |
Listing 18: Exploring synonyms
Stored Procedures
A stored procedure is a group of script(s) that are compiled into a single execution plan. We can use the catalog views to find out which stored procedures exist, what activity they perform, and which tables they reference.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
-- Stored Procedures SELECT @@Servername AS ServerName , DB_NAME() AS DBName , o.name AS StoredProcedureName , o.[Type] , o.create_date FROM sys.objects o WHERE o.[Type] = 'P' -- Stored Procedures ORDER BY o.name --OR -- Stored Procedure details SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , o.name AS 'ViewName' , o.[type] , o.Create_date , sm.[definition] AS 'Stored Procedure script' FROM sys.objects o INNER JOIN sys.sql_modules sm ON o.object_id = sm.object_id WHERE o.[type] = 'P' -- Stored Procedures -- AND sm.[definition] LIKE '%insert%' -- AND sm.[definition] LIKE '%update%' -- AND sm.[definition] LIKE '%delete%' -- AND sm.[definition] LIKE '%tablename%' ORDER BY o.name; GO |
Listing 19: Exploring stored procedures
With a simply addition to the WHERE clause of the stored procedure details query, we can investigate, for example, only those stored procedures that perform inserts.
|
1 2 3 4 5 |
... WHERE o.[type] = 'P' -- Stored Procedures AND sm.definition LIKE '%insert%' ORDER BY o.name ... |
Simply modify the WHERE clause as required to investigate stored procedures that do updates (LIKE '%update%'), deletes (LIKE '%delete%'), or reference a particular table (LIKE '%tablename%').
Functions
A function is stored SQL that accept parameters, performs an action or calculation and returns a result.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- Functions SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , o.name AS 'Functions' , o.[Type] , o.create_date FROM sys.objects o WHERE o.Type = 'FN' -- Function ORDER BY o.NAME; --OR -- Function details SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , o.name AS 'FunctionName' , o.[type] , o.create_date , sm.[DEFINITION] AS 'Function script' FROM sys.objects o INNER JOIN sys.sql_modules sm ON o.object_id = sm.OBJECT_ID WHERE o.[Type] = 'FN' -- Function ORDER BY o.NAME; GO |
Listing 20: Exploring functions
Triggers
A trigger is like a stored procedure that executes in response to a particular event that occurs on the table to which the trigger belongs. For example, we can create INSERT, UPDATE and DELETE triggers.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
-- Table Triggers SELECT @@Servername AS ServerName , DB_NAME() AS DBName , parent.name AS TableName , o.name AS TriggerName , o.[Type] , o.create_date FROM sys.objects o INNER JOIN sys.objects parent ON o.parent_object_id = parent.object_id WHERE o.Type = 'TR' -- Triggers ORDER BY parent.name , o.NAME --OR SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , Parent_id , name AS TriggerName , create_date FROM sys.triggers WHERE parent_class = 1 ORDER BY name; --OR -- Trigger Details SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , OBJECT_NAME(Parent_object_id) AS TableName , o.name AS 'TriggerName' , o.Type , o.create_date , sm.[DEFINITION] AS 'Trigger script' FROM sys.objects o INNER JOIN sys.sql_modules sm ON o.object_id = sm.OBJECT_ID WHERE o.Type = 'TR' -- Triggers ORDER BY o.NAME; GO |
Listing 21: Exploring triggers
CHECK Constraints
CHECK constraints are a good way to implement business logic in a database. For example, certain fields must be positive or negative or a date in one column must be later than a date in another column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
-- Check Constraints SELECT @@Servername AS ServerName , DB_NAME() AS DBName , parent.name AS 'TableName' , o.name AS 'Constraints' , o.[Type] , o.create_date FROM sys.objects o INNER JOIN sys.objects parent ON o.parent_object_id = parent.object_id WHERE o.Type = 'C' -- Check Constraints ORDER BY parent.name , o.name --OR --CHECK constriant definitions SELECT @@Servername AS ServerName , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(parent_object_id) AS SchemaName , OBJECT_NAME(parent_object_id) AS TableName , parent_column_id AS Column_NBR , Name AS CheckConstraintName , type , type_desc , create_date , OBJECT_DEFINITION(object_id) AS CheckConstraintDefinition FROM sys.Check_constraints ORDER BY TableName , SchemaName , Column_NBR GO |
Listing 22: Exploring CHECK constraints
Exploring your Data Model in depth
Up to this point, we’ve examined scripts that gives us a ‘high level’ view of the objects that comprise our databases. Often though, we’ll want more in-depth knowledge of each table, including the columns, their data types and any default values defined, which keys, constraints and indexes exist (or are missing) and so on.
The queries presented across the coming sections build on this foundation, and provide a means almost to “reverse engineer” your existing data model.
Columns
The following script documents the tables and their column definitions, in a specified database. The resulting output is a good one to cut and paste into Excel, where you can filter or sort on column names to get a good understanding of the data types that exist in a given database. Watch out for and question column names that are the same but have different data types or different lengths.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
-- Table Columns SELECT @@Servername AS Server , DB_NAME() AS DBName , isc.Table_Name AS TableName , isc.Table_Schema AS SchemaName , Ordinal_Position AS Ord , Column_Name , Data_Type , Numeric_Precision AS Prec , Numeric_Scale AS Scale , Character_Maximum_Length AS LEN , -- -1 means MAX like Varchar(MAX) Is_Nullable , Column_Default , Table_Type FROM INFORMATION_SCHEMA.COLUMNS isc INNER JOIN information_schema.tables ist ON isc.table_name = ist.table_name -- WHERE Table_Type = 'BASE TABLE' -- 'Base Table' or 'View' ORDER BY DBName , TableName , SchemaName , Ordinal_position; -- Summary of Column names and usage counts -- Watch for column names with different data types or different lengths SELECT @@Servername AS Server , DB_NAME() AS DBName , Column_Name , Data_Type , Numeric_Precision AS Prec , Numeric_Scale AS Scale , Character_Maximum_Length , COUNT(*) AS Count FROM information_schema.columns isc INNER JOIN information_schema.tables ist ON isc.table_name = ist.table_name WHERE Table_type = 'BASE TABLE' GROUP BY Column_Name , Data_Type , Numeric_Precision , Numeric_Scale , Character_Maximum_Length; -- Summary of data types SELECT @@Servername AS ServerName , DB_NAME() AS DBName , Data_Type , Numeric_Precision AS Prec , Numeric_Scale AS Scale , Character_Maximum_Length AS [Length] , COUNT(*) AS COUNT FROM information_schema.columns isc INNER JOIN information_schema.tables ist ON isc.table_name = ist.table_name WHERE Table_type = 'BASE TABLE' GROUP BY Data_Type , Numeric_Precision , Numeric_Scale , Character_Maximum_Length ORDER BY Data_Type , Numeric_Precision , Numeric_Scale , Character_Maximum_Length -- Large object data types or Binary Large Objects(BLOBs) -- Note if you are using Enterprise edition, these tables can't rebuild indexes "Online" SELECT @@Servername AS ServerName , DB_NAME() AS DBName , isc.Table_Name , Ordinal_Position AS Ord , Column_Name , Data_Type AS BLOB_Data_Type , Numeric_Precision AS Prec , Numeric_Scale AS Scale , Character_Maximum_Length AS [Length] FROM information_schema.columns isc INNER JOIN information_schema.tables ist ON isc.table_name = ist.table_name WHERE Table_type = 'BASE TABLE' AND ( Data_Type IN ( 'text', 'ntext', 'image', 'XML' ) OR ( Data_Type IN ( 'varchar', 'nvarchar', 'varbinary' ) AND Character_Maximum_Length = -1 ) ) -- varchar(max), nvarchar(max), varbinary(max) ORDER BY isc.Table_Name , Ordinal_position; |
Listing 23: Exploring columns and their data types
Column Defaults
Column Defaults are values that are stored in the column, if no value is entered for that column, when the record is first inserted. A common default for a column that stores dates is getdate() or current_timestamp. Another common default in auditing is system_user, to identify the login that performed a certain action.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
-- Table Defaults SELECT @@Servername AS ServerName , DB_NAME() AS DBName , parent.name AS TableName , o.name AS Defaults , o.[Type] , o.Create_date FROM sys.objects o INNER JOIN sys.objects parent ON o.parent_object_id = parent.object_id WHERE o.[Type] = 'D' -- Defaults ORDER BY parent.name , o.NAME --OR -- Column Defaults SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , OBJECT_SCHEMA_NAME(parent_object_id) AS SchemaName , OBJECT_NAME(parent_object_id) AS TableName , parent_column_id AS Column_NBR , Name AS DefaultName , [type] , type_desc , create_date , OBJECT_DEFINITION(object_id) AS Defaults FROM sys.default_constraints ORDER BY TableName , Column_NBR --OR -- Column Defaults SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , OBJECT_SCHEMA_NAME(t.object_id) AS SchemaName , t.Name AS TableName , c.Column_ID AS Ord , c.Name AS Column_Name , OBJECT_NAME(default_object_id) AS DefaultName , OBJECT_DEFINITION(default_object_id) AS Defaults FROM sys.Tables t INNER JOIN sys.columns c ON t.object_id = c.object_id WHERE default_object_id <> 0 ORDER BY TableName , SchemaName , c.Column_ID GO |
Listing 24: Exploring column default values
Computed columns
Computed columns are columns where the values determined by an equation, usually referencing other columns in the table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- Computed columns SELECT @@Servername AS ServerName , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(object_id) AS SchemaName , OBJECT_NAME(object_id) AS Tablename , Column_id , Name AS Computed_Column , [Definition] , is_persisted FROM sys.computed_columns ORDER BY SchemaName , Tablename , [Definition]; --Or -- Computed Columns SELECT @@Servername AS ServerName , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(t.object_id) AS SchemaName, t.Name AS TableName , c.Column_ID AS Ord , c.Name AS Computed_Column FROM sys.Tables t INNER JOIN sys.Columns c ON t.object_id = c.object_id WHERE is_computed = 1 ORDER BY t.Name , SchemaName , c.Column_ID GO |
Listing 25: Exploring computed columns
Identity Columns
IDENTITY columns are populated with unique system controlled numbers. A common example is an order number, where each time an order is entered into the system, SQL Server assigns to the IDENTITY column the next sequential number.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT @@Servername AS ServerName , DB_NAME() AS DBName , OBJECT_SCHEMA_NAME(object_id) AS SchemaName , OBJECT_NAME(object_id) AS TableName , Column_id , Name AS IdentityColumn , Seed_Value , Last_Value FROM sys.identity_columns ORDER BY SchemaName , TableName , Column_id; GO |
Listing 26: Exploring IDENTITY columns
Keys and Indexes
As discussed earlier, a general best practice all tables should have a primary key clustered index. As a second general best practice, foreign keys should have a supporting index on the same columns as the foreign key. Foreign key indexes provide the most likely way that tables be joined together in multi-table queries. Foreign key indexes are also important for performance when deleting records.
What indexes exist?
To see which indexes exist on all tables in the current database.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , o.Name AS TableName , i.Name AS IndexName FROM sys.objects o INNER JOIN sys.indexes i ON o.object_id = i.object_id WHERE o.Type = 'U' -- User table AND LEFT(i.Name, 1) <> '_' -- Remove hypothetical indexes ORDER BY o.NAME , i.name; GO |
Listing 27: Exploring existing indexes
Which indexes are missing?
The indexing related DMVs store statistics that SQL Server uses recommend indexes that could offer performance benefits, based on previously executed queries.
Do not add these indexes blindly. I would review and question each index suggested. Included column my come with a high cost of maintaining duplicate data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
-- Missing Indexes DMV Suggestions SELECT @@ServerName AS ServerName , DB_NAME() AS DBName , t.name AS 'Affected_table' , ( LEN(ISNULL(ddmid.equality_columns, N'') + CASE WHEN ddmid.equality_columns IS NOT NULL AND ddmid.inequality_columns IS NOT NULL THEN ',' ELSE '' END) - LEN(REPLACE(ISNULL(ddmid.equality_columns, N'') + CASE WHEN ddmid.equality_columns IS NOT NULL AND ddmid.inequality_columns IS NOT NULL THEN ',' ELSE '' END, ',', '')) ) + 1 AS K , COALESCE(ddmid.equality_columns, '') + CASE WHEN ddmid.equality_columns IS NOT NULL AND ddmid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + COALESCE(ddmid.inequality_columns, '') AS Keys , COALESCE(ddmid.included_columns, '') AS [include] , 'Create NonClustered Index IX_' + t.name + '_missing_' + CAST(ddmid.index_handle AS VARCHAR(20)) + ' On ' + ddmid.[statement] COLLATE database_default + ' (' + ISNULL(ddmid.equality_columns, '') + CASE WHEN ddmid.equality_columns IS NOT NULL AND ddmid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(ddmid.inequality_columns, '') + ')' + ISNULL(' Include (' + ddmid.included_columns + ');', ';') AS sql_statement , ddmigs.user_seeks , ddmigs.user_scans , CAST(( ddmigs.user_seeks + ddmigs.user_scans ) * ddmigs.avg_user_impact AS BIGINT) AS 'est_impact' , avg_user_impact , ddmigs.last_user_seek , ( SELECT DATEDIFF(Second, create_date, GETDATE()) Seconds FROM sys.databases WHERE name = 'tempdb' ) SecondsUptime -- Select * FROM sys.dm_db_missing_index_groups ddmig INNER JOIN sys.dm_db_missing_index_group_stats ddmigs ON ddmigs.group_handle = ddmig.index_group_handle INNER JOIN sys.dm_db_missing_index_details ddmid ON ddmig.index_handle = ddmid.index_handle INNER JOIN sys.tables t ON ddmid.OBJECT_ID = t.OBJECT_ID WHERE ddmid.database_id = DB_ID() ORDER BY est_impact DESC; GO |
Listing 28: Finding missing indexes
Foreign Keys
Foreign Keys define table dependencies and control referential integrity between multiple tables. In an Entity Relationship Diagram (ERD), the lines between the tables indicate the foreign keys.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- Foreign Keys SELECT @@Servername AS ServerName , DB_NAME() AS DB_Name , parent.name AS 'TableName' , o.name AS 'ForeignKey' , o.[Type] , o.Create_date FROM sys.objects o INNER JOIN sys.objects parent ON o.parent_object_id = parent.object_id WHERE o.[Type] = 'F' -- Foreign Keys ORDER BY parent.name , o.name --OR SELECT f.name AS ForeignKey , SCHEMA_NAME(f.SCHEMA_ID) AS SchemaName , OBJECT_NAME(f.parent_object_id) AS TableName , COL_NAME(fc.parent_object_id, fc.parent_column_id) AS ColumnName , SCHEMA_NAME(o.SCHEMA_ID) ReferenceSchemaName , OBJECT_NAME(f.referenced_object_id) AS ReferenceTableName , COL_NAME(fc.referenced_object_id, fc.referenced_column_id) AS ReferenceColumnName FROM sys.foreign_keys AS f INNER JOIN sys.foreign_key_columns AS fc ON f.OBJECT_ID = fc.constraint_object_id INNER JOIN sys.objects AS o ON o.OBJECT_ID = fc.referenced_object_id ORDER BY TableName , ReferenceTableName; GO |
Listing 29: Exploring Foreign keys
It will produce output similar to the following:
|
ForeignKey |
TableName |
ColumnName |
Reference TableName |
Reference ColumnName |
|
FK__discounts__stor___286302EC |
discounts |
stor_id |
stores |
stor_id |
|
FK__employee__job_id__34C8D9D1 |
employee |
job_id |
jobs |
job_id |
|
FK__employee__pub_id__37A5467C |
employee |
pub_id |
publishers |
pub_id |
|
FK__pub_info__pub_id__300424B4 |
pub_info |
pub_id |
publishers |
pub_id |
|
FK__roysched__title___267ABA7A |
roysched |
title_id |
titles |
title_id |
|
FK__sales__stor_id__239E4DCF |
sales |
stor_id |
stores |
stor_id |
|
FK__sales__title_id__24927208 |
sales |
title_id |
titles |
title_id |
|
FK__titleauth__au_id__1DE57479 |
titleauthor |
au_id |
authors |
au_id |
|
FK__titleauth__title__1ED998B2 |
titleauthor |
title_id |
titles |
title_id |
|
FK__titles__pub_id__1A14E395 |
titles |
pub_id |
publishers |
pub_id |
Missing Indexes that support Foreign Keys.
As a general best practice, it is recommended to have an index associated with each foreign key. This facilitates faster table joins, which are typically joined on foreign key columns anyway. Indexes on foreign keys also facilitate faster deletes. If these supporting indexes are missing, SQL will perform a table scale on the related table each time a record in the first table is deleted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
-- Foreign Keys missing indexes -- Note this script only works for creating single column indexes. -- Multiple FK columns are out of scope for this script. SELECT DB_NAME() AS DBName , rc.Constraint_Name AS FK_Constraint , -- rc.Constraint_Catalog AS FK_Database, -- rc.Constraint_Schema AS FKSch, ccu.Table_Name AS FK_Table , ccu.Column_Name AS FK_Column , ccu2.Table_Name AS ParentTable , ccu2.Column_Name AS ParentColumn , I.Name AS IndexName , CASE WHEN I.Name IS NULL THEN 'IF NOT EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N''' + RC.Constraint_Schema + '.' + ccu.Table_Name + ''') AND name = N''IX_' + ccu.Table_Name + '_' + ccu.Column_Name + ''') ' + 'CREATE NONCLUSTERED INDEX IX_' + ccu.Table_Name + '_' + ccu.Column_Name + ' ON ' + rc.Constraint_Schema + '.' + ccu.Table_Name + '( ' + ccu.Column_Name + ' ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = ON, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = ON);' ELSE '' END AS SQL FROM information_schema.referential_constraints RC JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE ccu ON rc.CONSTRAINT_NAME = ccu.CONSTRAINT_NAME JOIN INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE ccu2 ON rc.UNIQUE_CONSTRAINT_NAME = ccu2.CONSTRAINT_NAME LEFT JOIN sys.columns c ON ccu.Column_Name = C.name AND ccu.Table_Name = OBJECT_NAME(C.OBJECT_ID) LEFT JOIN sys.index_columns ic ON C.OBJECT_ID = IC.OBJECT_ID AND c.column_id = ic.column_id AND index_column_id = 1 -- index found has the foreign key -- as the first column LEFT JOIN sys.indexes i ON IC.OBJECT_ID = i.OBJECT_ID AND ic.index_Id = i.index_Id WHERE I.name IS NULL ORDER BY FK_table , ParentTable , ParentColumn; GO |
Listing 30: Finding missing Foreign Key indexes
Object Dependencies
It depends…I’m sure you have heard that before. I will review three different methods to ‘reverse engineer’ database dependencies. The first method use the stored procedure sp_msdependencies. The second method uses the foreign key systems tables. The third method uses a CTE.
sp_msdependencies
sp_msdependencies is a SQL Server undocumented stored procedure that can be helpful in navigating complex table interdependencies.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
EXEC sp_msdependencies '?' -- Displays Help sp_MSobject_dependencies name = NULL, type = NULL, flags = 0x01fd name: name or null (all objects of type) type: type number (see below) or null if both null, get all objects in database flags is a bitmask of the following values: 0x10000 = return multiple parent/child rows per object 0x20000 = descending return order 0x40000 = return children instead of parents 0x80000 = Include input object in output result set 0x100000 = return only firstlevel (immediate) parents/children 0x200000 = return only DRI dependencies power(2, object type number(s)) to return in results set: 0 (1 - 0x0001) - UDF 1 (2 - 0x0002) - system tables or MS-internal objects 2 (4 - 0x0004) - view 3 (8 - 0x0008) - user table 4 (16 - 0x0010) - procedure 5 (32 - 0x0020) - log 6 (64 - 0x0040) - default 7 (128 - 0x0080) - rule 8 (256 - 0x0100) - trigger 12 (1024 - 0x0400) - uddt shortcuts: 29 (0x011c) - trig, view, user table, procedure 448 (0x00c1) - rule, default, datatype 4606 (0x11fd) - all but systables/objects 4607 (0x11ff) - all |
Listing 31: sp_msdependencies help
If we list all dependencies using sp_msdependencies, it will return four columns: Type, ObjName, Owner (Schema) and Sequence.
Make special note of the Sequence number, this will start at 1 and will grow in sequential order. The Sequence is the number of layers, or rows, of dependencies.
I have used this method several times when asked to perform archiving or deleting of data on some large database models. If you know the table dependencies, you have a road map of the order in which you need to archive or delete records. Start with the table with the largest sequence number first, then work backward from the largest number to the smallest number. Tables with the same sequence number can be removed at the same time. This method does not violate any of the foreign key constraints, and thus allows you to move/delete records without temporarily dropping and rebuilding constraints.
|
1 2 |
EXEC sp_msdependencies NULL -- List all database dependencies EXEC sp_msdependencies NULL, 3 -- List table dependencies |
Listing 32: using sp_msdependencies to view all dependencies
In SSMS, if you right click on a table name you can click on ‘View Dependencies’ and ‘Objects that depend on tablename’.
We can see similar information from sp_msdependencies as follows:
|
1 2 3 |
-- sp_MSdependencies sp_MSdependencies - First level only -- Objects that are dependent on the specified object EXEC sp_msdependencies N'Sales.Customer',null, 1315327 -- Change Table Name |
Listing 33: using sp_msdependencies to view objects that depend on a table (first level only)
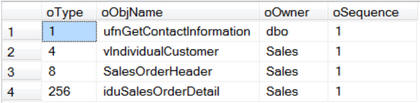
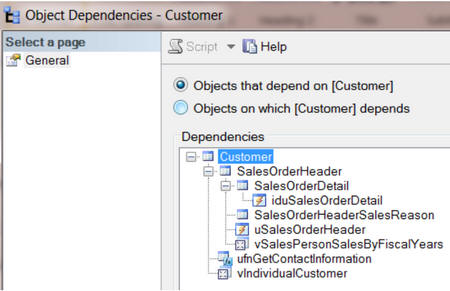
In SSMS if you right click on a table name you can click on ‘View Dependencies’ and ‘Objects that depend on tablename’, and then expand all the ‘+’ signs to see all the levels it looks like this.
The following msdependencies report would provide similar information.
|
1 2 3 |
-- sp_MSdependencies - All levels -- Objects that are dependent on the specified object EXEC sp_MSdependencies N'Sales.Customer', NULL, 266751 -- Change Table Name |
Listing 34: using sp_msdependencies to view objects that depend on a table (all levels)
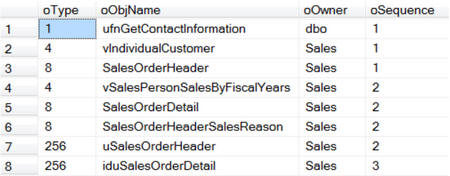
Similarly, in SSMS, we can see the objects on which a given table depends.
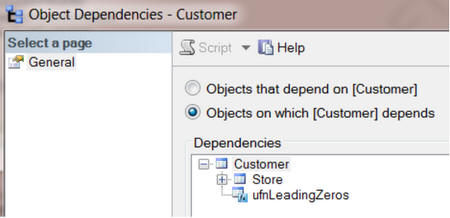
The following msdependencies report would provide similar information.
|
1 2 |
-- Objects that the specified object is dependent on EXEC sp_MSdependencies N'Sales.Customer', null, 1053183 -- Change Table |
Listing 35: Using sp_msdependencies to view objects on which a table depends
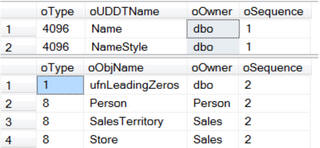
If you want a list of just table dependencies you could use a temp table to filter the dependency types.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE #TempTable1 ( Type INT , ObjName VARCHAR(256) , Owner VARCHAR(25) , Sequence INT ); INSERT INTO #TempTable1 EXEC sp_MSdependencies NULL SELECT * FROM #TempTable1 WHERE Type = 8 --Tables ORDER BY Sequence , ObjName DROP TABLE #TempTable1; |
Listing 36: Using sp_msdependencies to view only table dependencies
Query the system catalog views
The second method to reverse engineer your database dependencies is to query the foreign key relationships system tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
--Independent tables SELECT Name AS InDependentTables FROM sys.tables WHERE object_id NOT IN ( SELECT referenced_object_id FROM sys.foreign_key_columns ) -- Check for parents AND object_id NOT IN ( SELECT parent_object_id FROM sys.foreign_key_columns ) -- Check for Dependents ORDER BY Name -- Tables with dependencies. SELECT DISTINCT OBJECT_NAME(referenced_object_id) AS ParentTable , OBJECT_NAME(parent_object_id) AS DependentTable , OBJECT_NAME(constraint_object_id) AS ForeignKeyName FROM sys.foreign_key_columns ORDER BY ParentTable , DependentTable -- Top level of the pyramid tables. Tables with no parents. SELECT DISTINCT OBJECT_NAME(referenced_object_id) AS TablesWithNoParent FROM sys.foreign_key_columns WHERE referenced_object_id NOT IN ( SELECT parent_object_id FROM sys.foreign_key_columns ) ORDER BY 1 -- Bottom level of the pyramid tables. -- Tables with no dependents. (These are the leaves on a tree.) SELECT DISTINCT OBJECT_NAME(parent_object_id) AS TablesWithNoDependents FROM sys.foreign_key_columns WHERE parent_object_id NOT IN ( SELECT referenced_object_id FROM sys.foreign_key_columns ) ORDER BY 1 -- Tables with both parents and dependents. -- Tables in the middle of the hierarchy SELECT DISTINCT OBJECT_NAME(referenced_object_id) AS MiddleTables FROM sys.foreign_key_columns WHERE referenced_object_id IN ( SELECT parent_object_id FROM sys.foreign_key_columns ) AND parent_object_id NOT IN ( SELECT referenced_object_id FROM sys.foreign_key_columns ) ORDER BY 1; -- in rare cases, you might find a self-referencing dependent table. -- Recursive (self) referencing table dependencies. SELECT DISTINCT OBJECT_NAME(referenced_object_id) AS ParentTable , OBJECT_NAME(parent_object_id) AS ChildTable , OBJECT_NAME(constraint_object_id) AS ForeignKeyName FROM sys.foreign_key_columns WHERE referenced_object_id = parent_object_id ORDER BY 1 , 2; |
Listing 37: Using catalog views to view dependencies
Using a Common Table Expression (CTE)
The third method to reverse engineer your database hierarchical dependencies is to solve a recursive query using a Common Table Expression (CTE).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
-- How to find the hierarchical dependencies -- Solve recursive queries using Common Table Expressions (CTE) WITH TableHierarchy ( ParentTable, DependentTable, Level ) AS ( -- Anchor member definition (First level group to start the process) SELECT DISTINCT CAST(NULL AS INT) AS ParentTable , e.referenced_object_id AS DependentTable , 0 AS Level FROM sys.foreign_key_columns AS e WHERE e.referenced_object_id NOT IN ( SELECT parent_object_id FROM sys.foreign_key_columns ) -- Add filter dependents of only one parent table -- AND Object_Name(e.referenced_object_id) = 'User' UNION ALL -- Recursive member definition (Find all the layers of dependents) SELECT --Distinct e.referenced_object_id AS ParentTable , e.parent_object_id AS DependentTable , Level + 1 FROM sys.foreign_key_columns AS e INNER JOIN TableHierarchy AS d ON ( e.referenced_object_id ) = d.DependentTable ) -- Statement that executes the CTE SELECT DISTINCT OBJECT_NAME(ParentTable) AS ParentTable , OBJECT_NAME(DependentTable) AS DependentTable , Level FROM TableHierarchy ORDER BY Level , ParentTable , DependentTable; |
Listing 38: Using catalog views and a CTE to view dependencies
Summary
Within an hour or two, I can usually gain a good understanding of any database design, using the ‘reverse engineering’ methods described in this article.
My intention has been to provide a set of sample scripts that you can run immediately on the server and databases you are currently supporting. Microsoft Excel is a great tool to use to help analyze and document your database data. I recommend copying some of the following tables and column query results to excel, so you can filter and sort in a variety of ways. It also is a great way to share the results of your reverse engineering analysis with your managers and peers.
Load comments