
This article was originally published on mikesmithers.wordpress.com.
“You can’t have your cake and eat it!” This seems to be a regular refrain from the EU in the ongoing Brexit negotiations. They also seem to be a bit intolerant of “cherry picking”. I’ve never really understood the saying, “You can’t have your cake and eat it” – What’s the point in having the cake unless you are going to eat it ? Fortunately, I’m not alone in my perplexity – just ask any Brexiteer member of the British Cabinet. For those who want to make sense of it ( the saying, not Brexit), there is a handy Wikipedia page that explains all.
When it comes to Unit Testing frameworks for PL/SQL, compromise between cake ownership and consumption is usually required. Both utPLSQL 2.0 and ruby-plsql-spec have their good points, as well as some shortcomings. Of course, if you want a more declarative approach to writing Unit Tests, you can always use TOAD or SQLDeveloper’s built-in tools.
Recently, a new player has arrived on the PL/SQL testing scene. Despite it’s name, utPLSQL 3.0 appears to be less an evolution of utPLSQL 2.0 as a new framework all of it’s own. What I’m going to do here, is put utPLSQL 3.0 through it’s paces and see how it measures up to the other solutions I’ve looked at previously. Be warned, there may be crumbs…
Installation and Setup
If you’re comfortable on the command line, you can follow the instructions in the utPLSQL 3.0 documentation. On the other hand, if you’re feeling old-fashioned, you can just head over to the Project’s GitHub page and download the latest version. At the time of writing this is 3.0.4.
The downloaded file is utPLSQL.zip.
Now to unzip it. In my case, on Ubuntu, things look like this…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
unzip utPLSQL.zip Archive: utPLSQL.zip 980af88b62c3c75b11a8f81d6ad96d1c835021b8 creating: utPLSQL/ inflating: utPLSQL/CONTRIBUTING.md inflating: utPLSQL/LICENSE extracting: utPLSQL/VERSION creating: utPLSQL/docs/ ... ***snip*** ... creating: utPLSQL/test/ut_suite_manager/ inflating: utPLSQL/test/ut_suite_manager/test_suite_manager.pkb inflating: utPLSQL/test/ut_suite_manager/test_suite_manager.pks creating: utPLSQL/test/ut_utils/ inflating: utPLSQL/test/ut_utils/test_ut_utils.pkb inflating: utPLSQL/test/ut_utils/test_ut_utils.pks |
The archive will have unzipped into a directory called utPLSQL.
We now have some decisions to make in terms of how we want to install the framework. To save a bit of time, I’m going to go with the default.
Essentially this is :
- all of the framework objects are created in a schema called UT3
- if they do not already exist, DBMS_PROFILER tables will also be created in the schema
- the framework is made accessible via public synonyms
DBMS_PROFILER is used by the framework to provide testing coverage statistics, more of which later.
Note that the documentation includes setup steps that provide you with a bit more control. However, if you’re happy to go with the default then you simply need to run the appropriate script as a user connected as SYSDBA…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
cd utPLSQL/source sqlplus berrym@bakeoff_tent as sysdba SQL*Plus: Release 12.2.0.1.0 Production on Tue Mar 6 17:26:37 2018 Copyright (c) 1982, 2016, Oracle. All rights reserved. Enter password: Connected to: Oracle Database 11g Express Edition Release 11.2.0.2.0 - 64bit Production SQL> @install_headless.sql no rows selected Creating utPLSQL user UT3 -------------------------------------------------------------- Installing utPLSQL v3 framework into UT3 schema -------------------------------------------------------------- Switching current schema to UT3 -------------------------------------------------------------- Installing component UT_DBMS_OUTPUT_CACHE Installing component UT_EXPECTATION_PROCESSOR -------------------------------------------------------------- ... ***snip*** ... Installing PLSQL profiler objects into UT3 schema PLSQL_PROFILER_RUNS table created PLSQL_PROFILER_UNITS table created PLSQL_PROFILER_DATA table created Sequence PLSQL_PROFILER_RUNNUMBER created Installing component UT_FILE_MAPPER -------------------------------------------------------------- ... ***snip*** ... Synonym created. Synonym created. Synonym created. |
We should now have a schema called UT3 which owns lots of database objects…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
select object_type, count(*) from dba_objects where owner = 'UT3' group by object_type order by object_type / OBJECT_TYPE COUNT(*) ----------- --------- INDEX 13 LOB 1 PACKAGE 16 PACKAGE BODY 16 SEQUENCE 3 SYNONYM 13 TABLE 9 TYPE 71 TYPE BODY 53 VIEW 2 10 rows selected. |
One subtle difference that you may notice between utPLSQL 3.0 and its predecessor is the fact that the default application owner schema has a fairly “modest” set of privileges:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
select privilege from dba_sys_privs where grantee = 'UT3' / PRIVILEGE --------- CREATE SESSION CREATE TYPE CREATE VIEW CREATE SYNONYM CREATE SEQUENCE CREATE PROCEDURE CREATE TABLE ALTER SESSION 8 rows selected. |
However, the default password for this account is known…
|
1 2 3 4 5 |
SQL> connect ut3/XNtxj8eEgA6X6b6f@centos_xe Connected. SQL> show user USER is "UT3" SQL> |
Whilst it’s true that, as a testing framework, utPLSQL should be deployed only in non-production environments you may nevertheless find it prudent to lock the account immediately after installation…
|
1 2 |
alter user ut3 account lock / |
…and possibly even change the password for good measure.
Annotations and Matchers
There are two main component types in a utPLSQL 3.0 unit test – Annotations and Matchers. Annotations allow the framework to identify packaged procedures as tests and (if required), group them into suites. This obviates the need for separate storage of configuration information. Matchers are used to validate the results from a test execution.
This explanation would probably benefit from an example…
|
1 2 3 4 5 6 7 8 9 10 11 12 |
create or replace package ut3_demo as -- %suite(Demonstrate Framework) -- %test(Will always pass) procedure perfect_cake; -- %test( Will always fail) procedure dontlike_cake; end ut3_demo; / |
The package begins with the suite annotation to identify it as a package that contains unit tests.
|
1 |
-- %suite(Demonstrate Framework) |
The text in brackets displays when the test suite is executed. The positioning of this annotation is important. It needs to be the first thing in the package after the CREATE OR REPLACE statement.
Also, as it’s a package level annotation, it needs to have one or more blank lines between it and any procedure level annotations.
Each of the procedures in the package is identified as an individual test:
|
1 2 |
-- %test(Will always pass) -- %test( Will always fail) |
Once again the text will display when the test is executed. In the package body, we can see the matchers come into play:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
create or replace package body ut3_demo as procedure perfect_cake is begin ut.expect( 1).to_( equal(1) ); end; procedure dontlike_cake is begin ut.expect(1, 'Oops').to_( equal(0) ); end; end ut3_demo; / |
First impressions are that the code seems to have more in common with ruby-plsql-spec than it does with utPLSQL 2.0. This impression is reinforced when we execute the tests…
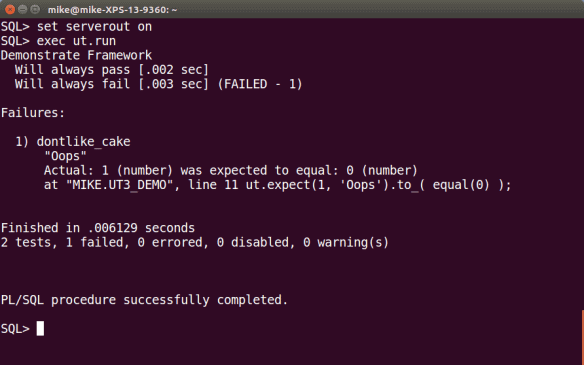
I was going to re-introduce the Footie app at this point as I’ve used it to demonstrate all of the other PL/SQL testing frameworks I’ve looked at so far. However, in these unprecedented times, I feel that an unprecedented (and very British) example is called for. Therefore, I humbly present…
The Great Brexit Bake-Off Application
The application owner is one hollywoodp (the observant among you will have already noticed that Mary Berry is the DBA)…
The application consists of some tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
alter session set current_schema = hollywoodp / create table brexit_bake_off ( id number primary key, contestant varchar2(100), show_stopper varchar2(100), notes varchar2(4000) ) / -- -- Create an error table for bulk loads - ERR$_BREXIT_BAKE_OFF -- exec dbms_errlog.create_error_log('brexit_bake_off'); -- -- External table for ETL process to upload records to the application -- create table contestants_xt ( id number, contestant varchar2(100), show_stopper varchar2(100), notes varchar2(4000) ) organization external ( type oracle_loader default directory my_files access parameters ( records delimited by newline badfile 'contestants.bad' logfile 'contestants.log' skip 1 fields terminated by '|' ( id integer external, contestant char(100), show_stopper char(100), notes char(4000) ) ) location ( 'contestants.csv') ) reject limit unlimited / |
…and a package:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
create or replace package bake_off as procedure add_contestant( i_id number, i_contestant varchar2, i_show_stopper varchar2, i_notes varchar2 default null); function get_contestant_id( i_contestant varchar2) return number; function get_show_stopper( i_id number) return varchar2; procedure list_contestants( io_contestant_list in out sys_refcursor); procedure upload_contestants; end bake_off; / create or replace package body bake_off as procedure add_contestant( i_id number, i_contestant varchar2, i_show_stopper varchar2, i_notes varchar2 default null) is begin insert into brexit_bake_off( id, contestant, show_stopper, notes) values( i_id, i_contestant, i_show_stopper, i_notes); end add_contestant; function get_contestant_id( i_contestant varchar2) return number is l_rtn number; begin select id into l_rtn from brexit_bake_off where upper(contestant) = upper(i_contestant); return l_rtn; exception when no_data_found then raise_application_error(-20900, 'This contestant is not in The Tent at the moment.'); end get_contestant_id; function get_show_stopper( i_id number) return varchar2 is l_rtn varchar2(100); begin select show_stopper into l_rtn from brexit_bake_off where id = i_id; return l_rtn; exception when no_data_found then raise_application_error(-20901, 'Soggy Bottom Error !'); end get_show_stopper; procedure list_contestants( io_contestant_list in out sys_refcursor) is begin open io_contestant_list for select id, contestant, show_stopper, notes from brexit_bake_off order by id; end list_contestants; procedure upload_contestants is begin insert into brexit_bake_off( id, contestant, show_stopper, notes) select id, contestant, show_stopper, notes from contestants_xt log errors reject limit unlimited; end upload_contestants; end bake_off; / |
Now, while Mr Hollywood is a renowned TV Chef, his PL/SQL coding skills do leave a little to be desired. Also, the application in it’s current state is just about the minimum he could come up with to demonstrate the framework, which is, after all, why we’re here. Therefore, I’d ask you to overlook the lack of anchored declarations etc. because, before we put the oven on, we need to make a fairly important design decision.
Where should I put my tests?
According to the documentation, the default for utPLSQL is to have the tests located in the same schema as the code they are to run against. However, you may well have good reasons for wanting to keep the tests in a separate schema.
For one thing, you may want to ensure that the process to promote your codebase through to Test and Production environments remains consistent and that you don’t have to worry about taking specific steps to ensure that your test code ends up somewhere it shouldn’t. Additionally, you may find it useful to create “helper” packages for your unit tests. These packages won’t themselves contain tests but will need to be treated as part of your test codebase rather than the application codebase.
If you decide to go down this route with utPLSQL, then you will have to ensure that the schema that owns your tests has the CREATE ANY PROCEDURE privilege if you want to avail yourself of the code coverage reporting provided by the framework. This privilege does not need to be granted if the application owning schema also holds the tests.
I really would prefer to have my tests in an entirely separate schema. So, I’ve created this schema as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
set verify off accept passwd prompt 'Enter password for UTP_BAKEOFF : ' hide create user utp_bakeoff identified by &passwd default tablespace users temporary tablespace temp / grant create session, create view, create sequence, create table, create any procedure to utp_bakeoff / alter user utp_bakeoff quota unlimited on users / -- -- Application specific grants required to generate test file for data load to -- external table grant read, write on directory my_files to utp_bakeoff / grant execute on utl_file to utp_bakeoff / |
The test schema also requires privileges on all of the Application’s database objects :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
set serveroutput on size unlimited declare l_priv varchar2(30); begin for r_object in ( select object_name, object_type from dba_objects where owner = 'HOLLYWOODP' and object_type in ('PACKAGE', 'PROCEDURE', 'SEQUENCE', 'TABLE', 'VIEW') ) loop l_priv := case r_object.object_type when 'PACKAGE' then 'EXECUTE' when 'PROCEDURE' then 'EXECUTE' when 'TABLE' then 'ALL' else 'SELECT' end; dbms_output.put_line('Granting '||l_priv||' on '||r_object.object_name); execute immediate 'grant '||l_priv||' on hollywoodp.'||r_object.object_name||' to UTP_BAKEOFF'; end loop; end; / |
Run this and we get …
|
1 2 3 4 |
Granting ALL on BREXIT_BAKE_OFF Granting EXECUTE on BAKE_OFF Granting ALL on ERR$_BREXIT_BAKE_OFF Granting ALL on CONTESTANTS_XT |
Finally, we’re ready to start testing our application…
Testing Single Row Operations
First, we’re going to write some tests for the BAKE_OFF.ADD_CONTESTANT procedure. So, in the utp_bakeoff schema, we create a package
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
create or replace package add_contestant_ut as -- %suite(add_contestant) -- %suitepath(brexit_bake_off.bake_off) -- helper function to generate a single contestant record function setup_contestant return hollywoodp.brexit_bake_off%rowtype; -- %test(Add a new contestant) procedure add_contestant; -- %test( Add existing contestant) procedure add_duplicate_contestant; end add_contestant_ut; / |
Before we take a look at the package body, it’s worth pausing to take note of the %suitepath annotation.
This Annotation allows separate test packages to be grouped together. In this instance, I’ve defined the path as Application Name/Package Name. Note that if you want to use this annotation then it must be on the line directly after the %suite annotation in the package header. Otherwise utPLSQL won’t pick it up.
Now for the test package body…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
create or replace package body add_contestant_ut as function setup_contestant return hollywoodp.brexit_bake_off%rowtype is rec_contestant hollywoodp.brexit_bake_off%rowtype; begin select nvl(max(id), 0) + 1 as id, 'David Davis' as contestant, 'Black Forest Gateaux' as show_stopper, 'Full of cherries to pick' as notes into rec_contestant from hollywoodp.brexit_bake_off; return rec_contestant; end setup_contestant; function contestant_exists( i_id in number) return boolean is dummy pls_integer; begin select 1 into dummy from hollywoodp.brexit_bake_off where id = i_id; return true; exception when no_data_found then return false; end contestant_exists; -- %test(Add a new contestant) procedure add_contestant is rec_contestant hollywoodp.brexit_bake_off%rowtype; begin -- Test setup phase rec_contestant := setup_contestant; -- Test execution hollywoodp.bake_off.add_contestant( i_id => rec_contestant.id, i_contestant => rec_contestant.contestant, i_show_stopper => rec_contestant.show_stopper, i_notes => rec_contestant.notes); -- Verify result ut.expect( contestant_exists(rec_contestant.id)).to_( be_true() ); end add_contestant; -- %test( Add existing contestant) procedure add_duplicate_contestant is rec_contestant hollywoodp.brexit_bake_off%rowtype; begin -- Test setup phase rec_contestant := setup_contestant; insert into hollywoodp.brexit_bake_off( id, contestant, show_stopper, notes) values( rec_contestant.id, rec_contestant.contestant, rec_contestant.show_stopper, rec_contestant.notes); -- Test execution - use a nested block as we're expecting an error... begin hollywoodp.bake_off.add_contestant( i_id => rec_contestant.id, i_contestant => rec_contestant.contestant, i_show_stopper => rec_contestant.show_stopper, i_notes => rec_contestant.notes); -- Validation ut.fail('Expected unique key violation error but none raised'); exception when others then ut.expect( sqlcode).to_( equal( -1)); end; end add_duplicate_contestant; end add_contestant_ut; / |
The structure of the tests is quite familiar in that there are four distinct phases, the first three of which are explicit :
- Setup – prepare the system for the test
- Execute – run the code to be tested
- Verify – check the result
- Teardown – reset the system to the state it was in prior to the test being run
Note that, in this instance, we are using the default behaviour of the framework for the teardown. This involves a savepoint being automatically created prior to each test being run and a rollback to that savepoint once the test completes. Later on, we’ll have a look at circumstances where we need to handle the Teardown phase ourselves.
The first test – add_contestant – uses a helper function and a boolean matcher :
|
1 |
ut.expect( contestant_exists(rec_contestant.id)).to_( be_true() ); |
The second test is checking both that we get an error when we try to add a duplicate record and that the error returned is the one we expect, namely :
|
1 |
ORA-00001: unique constraint (constraint_name) violated |
As we’re expecting the call to the application code to error, we’re using a nested block :
|
1 2 3 4 5 6 7 8 9 10 11 |
begin hollywoodp.bake_off.add_contestant( i_id => rec_contestant.id, i_contestant => rec_contestant.contestant, i_show_stopper => rec_contestant.show_stopper, i_notes => rec_contestant.notes); -- Validation ut.fail('Expected unique key violation error but none raised'); exception when others then ut.expect( sqlcode).to_( equal( -1)); end; |
If we now run the test, we can see that our code works as expected.
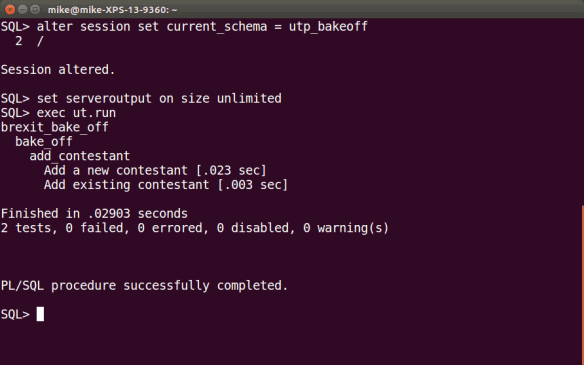
Incidentally, we can also see how utPLSQL recognises the hierarchy we’ve defined in the suitepath. While this approach works just fine for single-row operations, what happens when the framework is confronted with the need for…
Testing Ref Cursor values
This is always something of an ordeal in PL/SQL test frameworks – at least all of the ones I’ve looked at up until now. Fortunately utPLSQL’s equality matcher makes testing Ref Cursors as simple as you feel it really should be…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
create or replace package list_contestants_ut as -- %suite(list_contestants) -- %suitepath(brexit_bake_off.bake_off) -- %test( List all the contestants) procedure list_contestants; end list_contestants_ut; / create or replace package body list_contestants_ut as procedure list_contestants is l_rc_expected sys_refcursor; l_rc_actual sys_refcursor; begin -- setup insert into hollywoodp.brexit_bake_off with recs as ( select nvl(max(id), 0) + 1 as id, 'David Davis' as contestant, 'Black Forest Gateau' as show_stopper, 'Lots of cherries' as notes from hollywoodp.brexit_bake_off union all select nvl(max(id), 0) + 2, 'Michel Barnier', 'Chocolate Eclair', 'No cherries to pick' from hollywoodp.brexit_bake_off union all select nvl(max(id), 0) + 3, 'Jacob Rees-Mogg', 'Victoria Sponge', 'Traditional and no need for cherries' from hollywoodp.brexit_bake_off union all select nvl(max(id), 0) + 4, 'Tony Blair', 'Jaffa Cake', 'Definitely not a biscuit and a new referendum is required to settle this' from hollywoodp.brexit_bake_off ) select * from recs; -- Get expected results open l_rc_expected for select id, contestant, show_stopper, notes from hollywoodp.brexit_bake_off order by 1; -- execute hollywoodp.bake_off.list_contestants(l_rc_actual); -- Verify ut.expect( l_rc_actual).to_equal( l_rc_expected); close l_rc_actual; close l_rc_expected; end list_contestants; end list_contestants_ut; / |
Run this and we get :
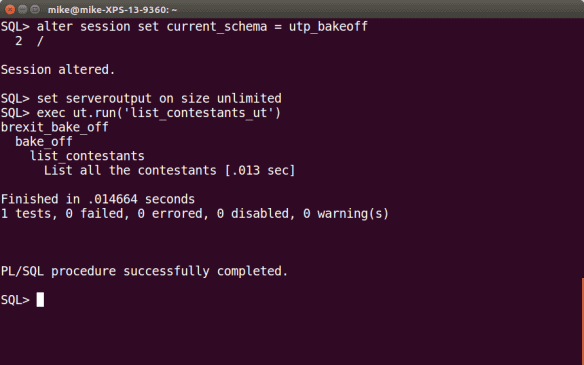
Incidentally, you may notice that the call to ut.run in this instance is a little different to what I was using previously. There are a number of ways to execute one or more utPLSQL tests through the ut.run procedure and we’ll be taking a look at some of these in a little while.
Testing across Transaction Boundaries
In this case, we’re testing the bulk upload of records from a file into the application tables via an external table. The load itself makes use of the LOG ERRORS clause which initiates an Autonomous Transaction in the background. This means we’re going to need to handle the teardown phase of the tests ourselves as utPLSQL’s default rollback-to-savepoint operation will not do the job.
First of all, here’s a quick reminder of the BAKE_OFF.UPLOAD_CONTESTANTS procedure that we want to test:
|
1 2 3 4 5 6 7 8 9 10 |
... procedure upload_contestants is begin insert into brexit_bake_off( id, contestant, show_stopper, notes) select id, contestant, show_stopper, notes from contestants_xt log errors reject limit unlimited; end upload_contestants; ... |
As part of the setup and teardown for the test, we’ll need to do a number of file operations – i.e.
- backup the existing data file
- create a test file for the external table
- remove the test file
- move the original file (if any) back into place
As we may have other loads we want to test this way in the future, then it would seem sensible to separate the code for these file operations into a helper package:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
create or replace package test_file_utils as function file_exists( i_dir all_directories.directory_name%type, i_fname varchar2) return boolean; procedure backup_file( i_dir all_directories.directory_name%type, i_fname varchar2, o_backup_fname out varchar2); procedure revert_file( i_dir all_directories.directory_name%type, i_fname varchar2, i_backup_fname varchar2); end test_file_utils; / create or replace package body test_file_utils as function file_exists( i_dir all_directories.directory_name%type, i_fname varchar2) return boolean is fh utl_file.file_type; e_no_file exception; -- ORA-29283 is returned if file does not exist or is not accessible. -- If the latter then the whole thing will fall over when we try to overwrite it. -- For now then, we can assume that this error means "file does not exist" pragma exception_init(e_no_file, -29283); begin fh := utl_file.fopen( i_dir, i_fname, 'r'); utl_file.fclose(fh); return true; exception when e_no_file then return false; end file_exists; procedure backup_file( i_dir all_directories.directory_name%type, i_fname varchar2, o_backup_fname out varchar2) is backup_fname varchar2(100); begin backup_fname := i_fname||systimestamp||'.bak'; utl_file.frename( i_dir, i_fname, i_dir, backup_fname); o_backup_fname := backup_fname; end backup_file; procedure revert_file( i_dir all_directories.directory_name%type, i_fname varchar2, i_backup_fname varchar2) is begin -- delete i_fname - the file created for the test utl_file.fremove(i_dir, i_fname); -- if a backup filename exists then put it back if i_backup_fname is not null then utl_file.frename( i_dir, i_backup_fname, i_dir, i_fname); end if; end revert_file; end test_file_utils; / |
Remember, as we’ve decided to hold all of our test code in a separate schema, we don’t have to worry about distinguishing this package from the application codebase itself.
Now for the test. In the package header, we’re using the rollback annotation to let utPLSQL know that we’ll look after the teardown phase manually for any test in this package :
|
1 2 3 4 5 6 7 8 9 10 |
create or replace package upload_contestants_ut as -- %suite(upload_contestants) -- %rollback(manual) -- %suitepath(brexit_bake_off.bake_off) -- %test( bulk_upload_contestants) procedure upload_contestants; end upload_contestants_ut; / |
Now for the test code itself. There’s quite a bit going on here. In the setup phase we:
- back up the target application table and it’s associated error table
- generate the file to be uploaded
- populate ref cursors with the expected results
In the verification phase, we use the to_equal matcher to compare the expected results refcursors with the actual results ( also ref cursors). Finally, we re-set the application to it’s state prior to the test being executed by :
- removing test records from the application and error tables
- dropping the backup tables
- tidying up the data files
All of which looks something like this :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 |
create or replace package body upload_contestants_ut as -- -- Private helper procedures -- procedure backup_tables is pragma autonomous_transaction; begin execute immediate 'create table brexit_bake_off_bu as select rowid as bu_rowid, tab.* from hollywoodp.brexit_bake_off tab'; execute immediate 'create table err$_brexit_bake_off_bu as select rowid as bu_rowid, tab.* from hollywoodp.err$_brexit_bake_off tab'; end backup_tables; procedure create_contestant_file( i_dir all_directories.directory_name%type, i_fname varchar2) is fh utl_file.file_type; begin fh := utl_file.fopen(i_dir, i_fname, 'w'); utl_file.put_line(fh, 'id|contestant|show_stopper|notes'); for r_contestant in ( select nvl(max(id), 0) + 1||chr(124)||'David Davis' ||chr(124)||'Black Forest Gateau'||chr(124)||null||chr(124) as rec from hollywoodp.brexit_bake_off union all select nvl(max(id), 0) + 2||chr(124)||'Michel Barnier' ||chr(124)||'Chocolate Eclair'||chr(124)||'Leave my cherries alone !'||chr(124) from hollywoodp.brexit_bake_off union all -- Duplicate records (by ID) select nvl(max(id), 0) + 1||chr(124)||'Jacob Rees-Mogg' ||chr(124)||'Victoria Sponge'||chr(124)||null||chr(124) from hollywoodp.brexit_bake_off union all select nvl(max(id), 0) + 2||chr(124)||'Tony Blair' ||chr(124)||'Jaffa Cakes'||chr(124)||'Tough on brexit, tough on the causes of Brexit'||chr(124) from hollywoodp.brexit_bake_off ) loop utl_file.put_line(fh, r_contestant.rec); end loop; utl_file.fflush(fh); utl_file.fclose(fh); end create_contestant_file; procedure cleardown_test_records is pragma autonomous_transaction; begin execute immediate 'delete from hollywoodp.brexit_bake_off where rowid not in (select bu_rowid from brexit_bake_off_bu)'; execute immediate 'delete from hollywoodp.err$_brexit_bake_off where rowid not in (select bu_rowid from err$_brexit_bake_off_bu)'; commit; end cleardown_test_records; procedure drop_backup_tables is pragma autonomous_transaction; begin execute immediate 'drop table brexit_bake_off_bu'; execute immediate 'drop table err$_brexit_bake_off_bu'; end drop_backup_tables; -- The test itself procedure upload_contestants is target_dir constant all_directories.directory_name%type := 'MY_FILES'; fname constant varchar2(100) := 'contestants.csv'; backup_fname varchar2(100); expected_load sys_refcursor; expected_err sys_refcursor; actual_load sys_refcursor; actual_err sys_refcursor; begin -- -- Setup Phase -- backup_tables; -- Backup the external table file if test_file_utils.file_exists( target_dir, fname) then test_file_utils.backup_file( target_dir, fname, backup_fname); end if; -- Create a load file create_contestant_file( target_dir, fname); -- Populate the expected results open expected_load for select * from hollywoodp.contestants_xt where upper(contestant) in ('DAVID DAVIS', 'MICHEL BARNIER') order by id; open expected_err for select 1 as ora_err_number$, id, contestant, show_stopper, notes from hollywoodp.contestants_xt where upper( contestant) in ('JACOB REES-MOGG', 'TONY BLAIR') order by id; -- -- Execute -- hollywoodp.bake_off.upload_contestants; -- -- Verify -- open actual_load for select * from hollywoodp.brexit_bake_off order by id; open actual_err for select ora_err_number$, id, contestant, show_stopper, notes from hollywoodp.err$_brexit_bake_off order by id; ut.expect( expected_load).to_equal( actual_load); ut.expect( expected_err).to_equal( actual_err); -- -- Teardown -- cleardown_test_records; drop_backup_tables; test_file_utils.revert_file( target_dir, fname, backup_fname); end upload_contestants; end upload_contestants_ut; / |
Running tests and reporting results
The framework does offer an API for use to execute tests programatically. However, whilst you’re writing the tests themselves, you’ll probably want something a bit more interactive.
You can simply run all of the tests in the current schema as follows :
|
1 2 |
set serveroutput on size unlimited exec ut.run |
However, there are times when you’ll probably need to be a bit more selective. Therefore, it’s good to know that utPLSQL will let you execute tests interactively in a number of different ways:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
set serveroutput on size unlimited alter session set current_schema = utp_bakeoff / -- single test passing in (package name.procedure name) exec ut.run('add_contestant_ut.add_contestant') -- all tests in a package (package name) exec ut.run('add_contestant_ut') -- all suites in a suitepath (owning schema:suitepath) exec ut.run('utp_bakeoff:brexit_bake_off.bake_off') |
If we run this for the application tests we’ve written, the output looks like this:
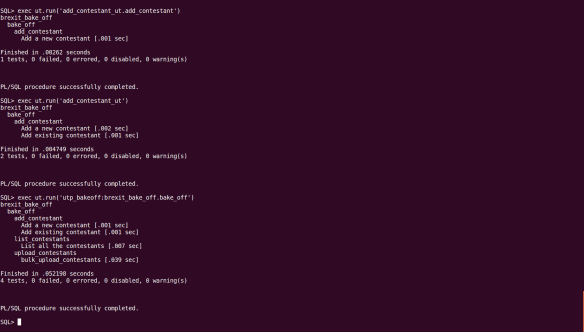
By default ut_run uses the ut_document_reporter to format the output from the tests. However, there are other possible formats, which you can invoke with a second argument to UT_RUN.
For example…
|
1 |
exec ut_run('add_contestant_ut', ut_xunit_reporter()); |
…outputs…
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<testsuites tests="2" skipped="0" error="0" failure="0" name="" time=".002972" > <testsuite tests="2" id="1" package="brexit_bake_off" skipped="0" error="0" failure="0" name="brexit_bake_off" time=".002894" > <testsuite tests="2" id="2" package="brexit_bake_off.bake_off" skipped="0" error="0" failure="0" name="bake_off" time=".002859" > <testsuite tests="2" id="3" package="brexit_bake_off.bake_off.add_contestant_ut" skipped="0" error="0" failure="0" name="add_contestant" time=".00279" > <testcase classname="brexit_bake_off.bake_off" assertions="1" skipped="0" error="0" failure="0" name="Add a new contestant" time=".001087" > </testcase> <testcase classname="brexit_bake_off.bake_off.add_contestant_ut" assertions="1" skipped="0" error="0" failure="0" name="Add existing contestant" time=".001175" > </testcase> </testsuite> </testsuite> </testsuite> </testsuites> |
By contrast, if you want something slightly more colourful…
|
1 2 |
set serveroutput on size unlimited exec ut.run('add_contestant_ut', a_color_console => true) |
…or even…
|
1 2 |
set serveroutput on size unlimited exec ut.run(a_color_console => true) |
Note that, unlike the previous executions, the a_color_console parameter is being passed by reference rather than position. Provided your command line supports ANSICONSOLE, you are rewarded with…
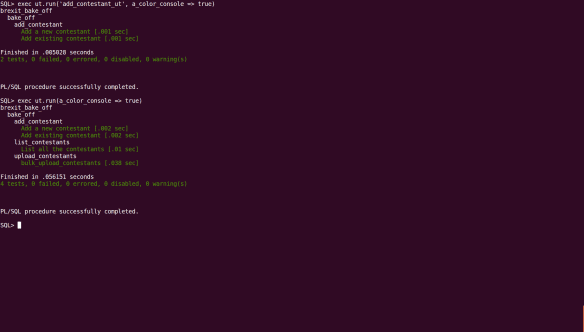
Test Coverage reporting
As mentioned a couple of times already, utPLSQL does also provide coverage reporting functionality. In this case, we’re going to look at the HTML report.
|
1 2 3 4 5 6 |
set serveroutput on size unlimited alter session set current_schema = utp_bakeoff; set feedback off spool add_contestant_coverage.html exec ut.run('add_contestant_ut', ut_coverage_html_reporter(), a_coverage_schemes => ut_varchar2_list('hollywoodp')) spool off |
Opening the file in a web browser we can see some summary information :
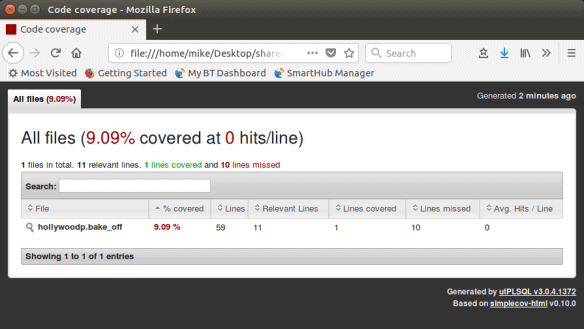
Clicking on the magnifying glass allows us to drill-down into individual program units:
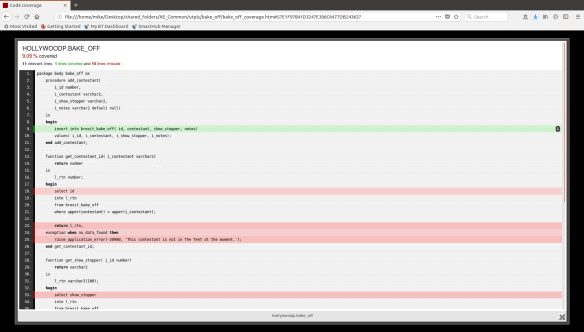
Of course, you’ll probably want to get an overall picture of coverage in terms of all tests for the application code. In this case you can simply run:
|
1 2 3 4 5 6 |
set serveroutput on size unlimited alter session set current_schema = utp_bakeoff; set feedback off spool brexit_bake_off_coverage.html exec ut.run(ut_coverage_html_reporter(), a_coverage_schemes => ut_varchar2_list('hollywoodp')) spool off |
When we look at this file in the browser, we can see that at least we’ve made a start:
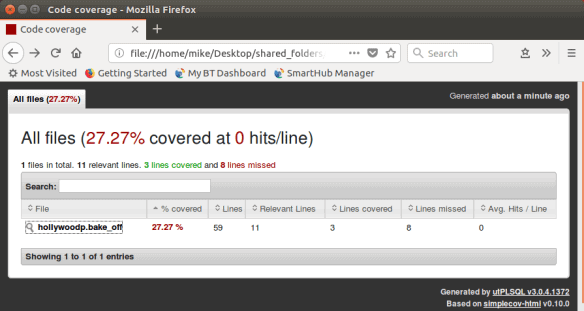
Keeping track of your Annotations
Whilst annotations provide a method of identifying and organising tests in a way that avoids the need for storing large amounts of metadata, it can be easy to “lose” tests as a result. For example, if you have a fat-finger moment and mis-type a suitepath value, that test will not execute when you expect it to ( i.e. when you run that suitepath).
Fortunately, utPLSQL does keep track of the annotations under the covers, using the UT_ANNOTATION_CACHE_INFO and UT_ANNOTATION_CACHE tables. Despite their names, these are permanent tables:
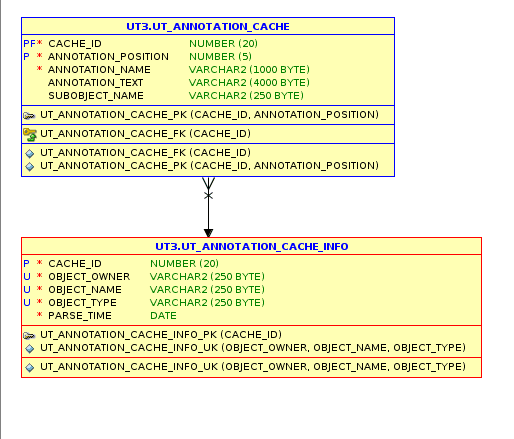
So, if I want to make sure that I haven’t leaned on the keyboard at an inopportune moment, I can run a query like:
|
1 2 3 4 5 6 7 8 |
select aci.object_name, ac.annotation_text from ut3.ut_annotation_cache_info aci inner join ut3.ut_annotation_cache ac on ac.cache_id = aci.cache_id and ac.annotation_name = 'suitepath' and aci.object_owner = 'UTP_BAKEOFF' order by 1 / |
…which in my case returns…
|
1 2 3 4 5 |
OBJECT_NAME ANNOTATION_TEXT ------------------------------ ---------------------------------------- ADD_CONTESTANT_UT brexit_bake_off.bake_off LIST_CONTESTANTS_UT brexit_bake_off.bake_off UPLOAD_CONTESTANTS_UT brexit_bake_off.bake_off |
Final Thoughts
I’ve tried to give some flavour of what the framework is capable of, but I’ve really just scratched the surface.
For more information, I’d suggest you take a look at the framework’s excellent documentation.
Also, Jacek Gebal, one of the authors of the framework has shared a presentation which you may find useful.
The utPLSQL 3.0 framework is a very different beast from it’s predecessor. The ground up re-write of the framework has brought it bang up to date in terms of both functionality and ease of use. If you’re looking for a PL/SQL testing framework that’s contained entirely within the database then look no further… unless you’re allergic to cherries.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments