
In the first part of this series I introduced you to the analytic functions family, outlined its close relationship to aggregate functions, and illustrated my points with a few examples. I demonstrated how, by clever use of the analytic function clauses – partition by, order by, and the windowing clause – you could tune your functions to wring even more information from your data.
That’s great and all that, but there’s more. In this second article we’ll look at the various types of analytic functions that are available to us, and we’ll get our hands dirty with a few more examples. After all, no one ever became a great footballer just by talking about football; you’ve got to go out there and kick a few balls.
So let’s kick balls.
Types of Analytic Functions
You probably don’t need me to tell you this, but I’ll tell you anyway; analytic functions have the following syntax:
|
1 |
FUNCTION (params) OVER ([PARTITION BY <…>] [ORDER BY <…>][window_clause]) |
The clauses – partition by, order by, and the window clause – are optional; or, to put it more accurately, might be optional. It depends on the function. There are a few dozen different analytic functions in Oracle, and you could split them into two camps – those for which the ORDER BY clause is mandatory and those where it is optional.
Alternatively, you could split them into those that have equivalent aggregate functions, and those that are purely analytic functions with no aggregate little brother.
Or, perhaps more sensibly, you can group analytic functions by what they do.
- There are the Arithmetic analytic functions, such as MAX, MIN, COUNT, AVG, MEDIAN and SUM.
- There are the Statistical analytic functions: STDVAR, CORR, COVAR_POP, VARIANCE, CUME_DIST and a few others.
- There are the Ranking – or Positional – analytic functions: DENSE_RANK, FIRST_VALUE, LAST_VALUE, NTH_VALUE, NTILE, PERCENT_RANK, RANK, ROW_NUMBER and a few others.
- There are the Relative analytic functions: LEAD, LAG.
- Since 12c, there are the data mining analytic functions: CLUSTER_DETAILS, FEATURE_DETAILS, PREDICTION_DETAILS and a few others.
- And finally, there are others that do not fit neatly into a larger group, such as RATIO_TO_REPORT and LISTAGG.
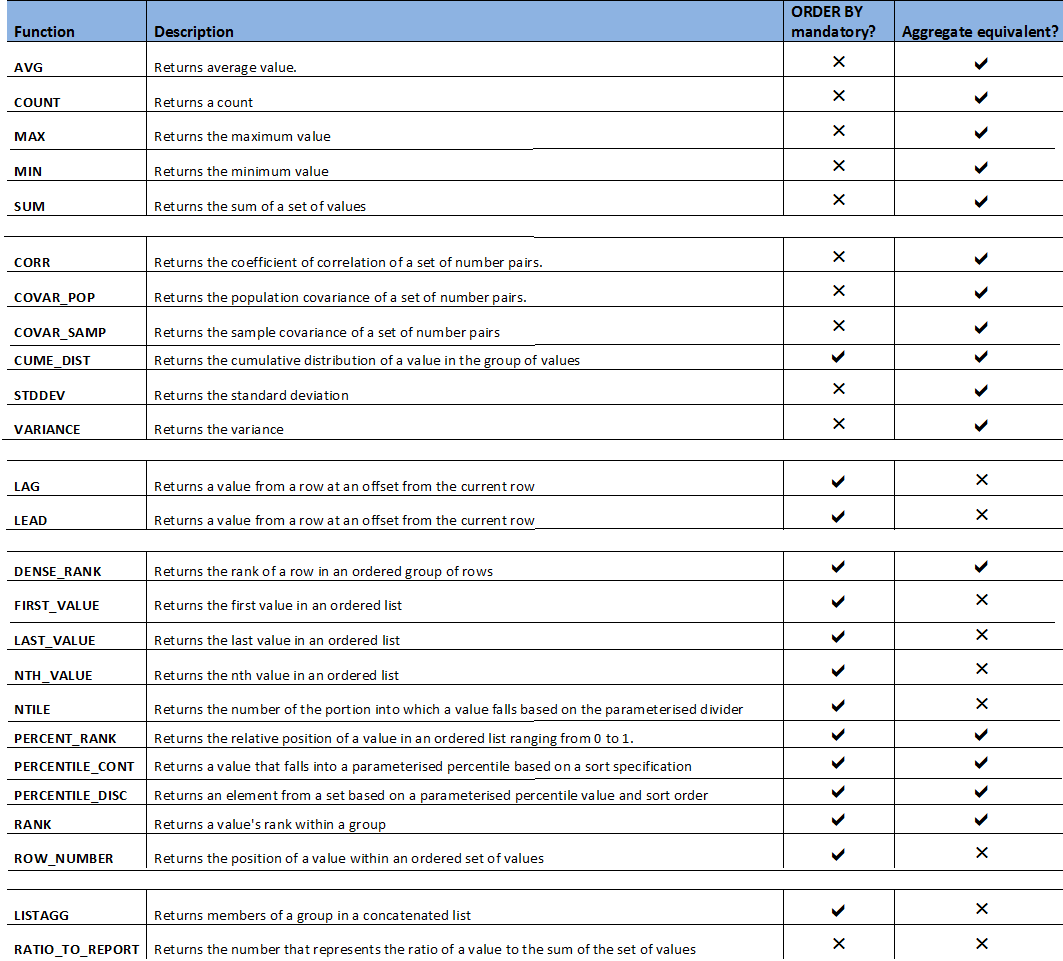
Obviously, we can’t discuss every single different analytic function; it’d take too long – and, if I’m being honest, I haven’t used every one of them in my career. But if we pick a representative few, it’ll give you a good sense of how and when to use analytic functions.
MAX, MIN, AVG
These functions are pretty straightforward, and don’t need much introduction, so let’s jump straight into an example. Say you wanted to produce a report of every employee, their salary, and a comparison of that salary to others within their departments.
|
1 2 3 4 5 6 |
SELECT ename, deptno, sal, AVG(sal) OVER (PARTITION BY deptno) "Average Dept Salary", MIN(sal) OVER (PARTITION BY deptno) "Minimum Dept Salary", MAX(sal) OVER (PARTITION BY deptno) "Maximum Dept Salary" FROM emp ORDER BY ename; |
| ENAME | DEPTNO | SAL | Average Dept Salary | Minimum Dept Salary | Maximum Dept Salary |
| ADAMS | 20 | 1100 | 2175 | 800 | 3000 |
| ALLEN | 30 | 1600 | 1566.67 | 950 | 2850 |
| BLAKE | 30 | 2850 | 1566.67 | 950 | 2850 |
| CLARK | 10 | 2450 | 2916.67 | 1300 | 5000 |
| FORD | 20 | 3000 | 2175 | 800 | 3000 |
| JAMES | 30 | 950 | 1566.67 | 950 | 2850 |
| JONES | 20 | 2975 | 2175 | 800 | 3000 |
| KING | 10 | 5000 | 2916.67 | 1300 | 5000 |
| MARTIN | 30 | 1250 | 1566.67 | 950 | 2850 |
| MILLER | 10 | 1300 | 2916.67 | 1300 | 5000 |
| SCOTT | 20 | 3000 | 2175 | 800 | 3000 |
| SMITH | 20 | 800 | 2175 | 800 | 3000 |
| TURNER | 30 | 1500 | 1566.67 | 950 | 2850 |
| WARD | 30 | 1250 | 1566.67 | 950 | 2850 |
LISTAGG
Outside of the set of arithmetic analytic functions, this is probably the one that I find myself using the most. LISTAGG concatenates the contents of a column into a VARCHAR2 string; basically, it takes vertical data and allows you display it horizontally.
The LISTAGG syntax is worth a look, as it is a little different.
|
1 |
LISTAGG (expr [, delimiter]) WITHIN GROUP (ORDER BY expr) [OVER (PARTITION BY)] |
Here’s an example. Say we wanted to obtain a list of all our employees and all the colleagues that share a department with them, we’d turn to LISTAGG.
|
1 2 3 4 |
SELECT ename, deptno, LISTAGG (ename, ',') WITHIN GROUP (ORDER BY ename) OVER (PARTITION BY deptno) AS "Colleagues" FROM emp ORDER BY ename; |
| ENAME | DEPTNO | Colleagues |
| ADAMS | 20 | ADAMS,FORD,JONES,SCOTT,SMITH |
| ALLEN | 30 | ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD |
| BLAKE | 30 | ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD |
| CLARK | 10 | CLARK,KING,MILLER |
| FORD | 20 | ADAMS,FORD,JONES,SCOTT,SMITH |
| JAMES | 30 | ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD |
| JONES | 20 | ADAMS,FORD,JONES,SCOTT,SMITH |
| KING | 10 | CLARK,KING,MILLER |
| MARTIN | 30 | ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD |
| MILLER | 10 | CLARK,KING,MILLER |
| SCOTT | 20 | ADAMS,FORD,JONES,SCOTT,SMITH |
| SMITH | 20 | ADAMS,FORD,JONES,SCOTT,SMITH |
| TURNER | 30 | ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD |
| WARD | 30 | ALLEN,BLAKE,JAMES,MARTIN,TURNER,WARD |
RANK, DENSE_RANK
RANK and DENSE_RANK are very closely related; they do pretty much the same thing, with one small – significant – difference. They both return the position – the rank – of the row in an ordered group. The only difference is that DENSE_RANK determines that position based on a count of the unique values in the list; RANK, on the other hand, gives rows with an equal value an equal rank, which can result in gaps in the ranking. If two rows have an equal value and rank as Position 1, the next available position using RANK will be Position 3; using DENSE_RANK, it will be Position 2.
Here’s the syntax:
|
1 |
DENSE_RANK|RANK () OVER ([PARTITION BY <…>] ORDER BY expr) |
|
1 2 3 4 5 |
SELECT ename, sal, RANK () OVER (ORDER BY sal) AS "Rank", DENSE_RANK () OVER (ORDER BY sal) AS "Dense Rank" FROM emp ORDER BY sal; |
| ENAME | SAL | Rank | Dense_Rank |
| SMITH | 800 | 1 | 1 |
| JAMES | 950 | 2 | 2 |
| ADAMS | 1100 | 3 | 3 |
| MARTIN | 1250 | 4 | 4 |
| WARD | 1250 | 4 | 4 |
| MILLER | 1300 | 6 | 5 |
| TURNER | 1500 | 7 | 6 |
| ALLEN | 1600 | 8 | 7 |
| CLARK | 2450 | 9 | 8 |
| BLAKE | 2850 | 10 | 9 |
| JONES | 2975 | 11 | 10 |
| FORD | 3000 | 12 | 11 |
| SCOTT | 3000 | 12 | 11 |
| KING | 5000 | 14 | 12 |
The way that the RANK and the DENSE_RANK values fork at the Miller record demonstrates their subtle difference.
Finally, even though this is an article on analytic functions, I think it’s worth spending a little time looking at the aggregate function equivalents for RANK and DENSE_RANK. They return a (dense) rank for a hypothetical value in the ordered list. Imagine you were planning to take on a new member of staff at a salary of $2650, and you wondered where that would place her within the company hierarchy.
The syntax for the RANK and DENSE_RANK aggregate functions are a little different from that of their analytic cousins.
|
1 |
DENSE_RANK|RANK (expr) WITHIN GROUP (ORDER BY expr) |
|
1 2 3 |
SELECT DENSE_RANK (2650) WITHIN GROUP (ORDER BY sal) AS "Dense_rank", RANK (2650) WITHIN GROUP (ORDER BY sal) AS "Rank" FROM emp; |
| Dense_rank | Rank |
| 9 | 10 |
ROW_NUMBER
A good corollary following on from RANK and DENSE_RANK is ROW_NUMBER. Unlike the other two, ROW_NUMBER returns a sequential ranking of a row within an ordered list, making no special allowance for rows of equal value.
And if you’re wondering why we need ROW_NUMBER when we’ve got the perfectly good rownum pseudocolumn, then you’re forgetting the importance of the analytic function clauses. Firstly, using PARTITION BY, we can get the row number within a group.
|
1 2 3 4 |
SELECT ename, deptno, sal, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY deptno, sal desc) AS "Position in Dept" FROM emp ORDER BY deptno, sal desc; |
| ENAME | DEPTNO | SAL | Position in Dept |
| KING | 10 | 5000 | 1 |
| CLARK | 10 | 2450 | 2 |
| MILLER | 10 | 1300 | 3 |
| SCOTT | 20 | 3000 | 1 |
| FORD | 20 | 3000 | 2 |
| JONES | 20 | 2975 | 3 |
| ADAMS | 20 | 1100 | 4 |
| SMITH | 20 | 800 | 5 |
| BLAKE | 30 | 2850 | 1 |
| ALLEN | 30 | 1600 | 2 |
| TURNER | 30 | 1500 | 3 |
| WARD | 30 | 1250 | 4 |
| MARTIN | 30 | 1250 | 5 |
| JAMES | 30 | 950 | 6 |
Secondly, if you’ve ever got weird results using rownum in a query that also has an order by statement, you’ll know that rownum is determined before the order is applied to the resultset. However, using row_number along with the analytic order by clause, you can ensure that your results respect your imposed order.
|
1 2 3 4 |
SELECT ename, sal, rownum, ROW_NUMBER() OVER (ORDER BY sal) AS "Row_number" FROM emp ORDER BY sal; |
| ENAME | SAL | ROWNUM | Row_number |
| SMITH | 800 | 7 | 1 |
| JAMES | 950 | 13 | 2 |
| ADAMS | 1100 | 12 | 3 |
| MARTIN | 1250 | 10 | 4 |
| WARD | 1250 | 9 | 5 |
| MILLER | 1300 | 14 | 6 |
| TURNER | 1500 | 11 | 7 |
| ALLEN | 1600 | 8 | 8 |
| CLARK | 2450 | 3 | 9 |
| BLAKE | 2850 | 2 | 10 |
| JONES | 2975 | 4 | 11 |
| FORD | 3000 | 6 | 12 |
| SCOTT | 3000 | 5 | 13 |
| KING | 5000 | 1 | 14 |
Conclusion
There are, as I said, dozens of analytic functions and I’ve been pleased to watch Oracle add to their number with each major release. These articles were never going to fully dissect every possible function, but I hope that they’ve demonstrated the strengths of the functionality and its amazing flexibility.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments