
Before we jump into the Big Data world and Spark specifically, let’s take a step back to the relational database sphere and see what all the fuss around partitioning relational data tables is about.
First things first
There a few important reasons why partitioning was introduced in RDBMS. However, all of them stem from the fact that, at some point, a database table may grow in a size to the hundreds of gigabytes or more and this makes difficult to:
- load new data
- remove old data
- maintain indexes
- query the data
The table partitioning should make such operations much more manageable by dividing the table and its indexes into smaller partitions based on selected attributes (columns). As a result, maintenance operations can be applied on a partition-by-partition basis, rather than the entire table. What’s more, a SQL Server optimizer can generate an execution plan that will read data only from the requested partitions if a proper filtered query is invoked; this dramatically improves the query execution performance. This operation is called ‘partition pruning’.
There are well known strategies and best practices for partitioning in the RDBMS world, which I will not cover here (you can read Partitioned Table and Index Strategies Using SQL Server 2008 whitepaper if you’re interested). Instead, I will focus on generic day-to-day data flow such as loading new data into a system to better understand the problem and see whether we can do the same kind of optimizations in Spark world. I will assume, in this article, that you know a few things about Spark at least, if not then I strongly recommend Srini Penchikala – Big Data Processing with Apache Spark, Spark Essentials with Adam Breindel, Learning Spark book or Apache Spark Documentation.
Load’em all, but how?
The most common day-to-day activity in any data pipeline is loading a new data into any sort of storage system. Based on what I have already said, we could imagine two approaches here:
- always load data into the same container, whether it’s a single table file or folder
- structure (partition) the data where data will be physically distributed across different table files or folders, while at the same time logically visible as a single entity (table)
While the first approach is very tempting, it carries quite a big burden. By this I mean that you’re making a single big pile of data and, the more it grows, the less control you have over it. Immediately, it turns out that in order to do any sort of operations, such as duplicate checks, you will need to read the entire existing data. I’m sure you don’t want to load the same data twice.
You can introduce indexes in order to overcome those issues: However with a very large scale, indexes become a problem as well, in the exact same way as the table itself. Additionally, you have to rebuild those big indexes for the whole table each time the data has been loaded.
And what if you want to re-load the data that has been loaded two weeks ago because, at that time, the data was of poor quality? You need to locate the old data subset, delete it & finally load a new one. This can potentially take a tremendous time if you are operating on a very large scale of data.
So how does partitioning solve that? Let’s take a look.
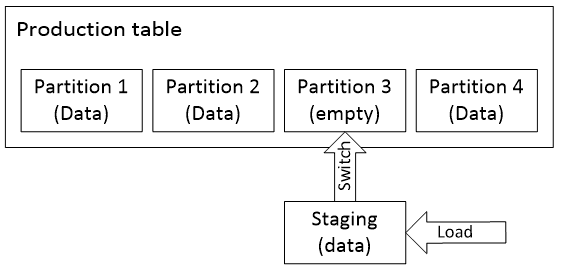
In a nutshell, firstly, an empty Partition 3 is created in a production table; then new data is loaded into a staging table with only one partition. Finally a meta-switch exchanges partitions. The old partition can be deleted now. The only operation that really takes time is loading a new data into a staging partition. However, keep in mind it’s loading data into an empty table with one partition rather than into the entire production table.
Such approach also enables an immutable data pipeline where you can easily reload any snapshot data, on any partition basis, anytime. Such an immutable data pipeline removes the headache of managing the existing state (merges).
How about Spark then? Do we have the same problems with raw data there? Can we use the same concepts there?
Let’s partition a table, oops, I meant folder, does it really matter?
The story about loading data is a bit different in the Big Data world because raw data is stored directly on a distributed file system. However, even though we don’t have to really care about indexes, we would still appreciate partitioning here for the same exact reasons, especially because we have to deal with a very large scale data.
First of all, since these are just files on a file system, we need an efficient file format that supports file schema, partitioning, compression and ideally columnar storage. Luckily, there are a few in the Big Data ecosystem but the most promising and natively integrated by Spark is Apache Parquet that was originally invented by Twitter.
Parquet makes it possible to make the transition from having just files on a file system to having more files-as-tables on a file system with very efficient columnar storage. That brings us more closely to the RDBMS world rather than working with just files.
In terms of tables, columnar storage brings two important advantages:
- very efficient compression of homogeneous columnar values over heterogeneous row values
- . For example, if you have a ‘Time’ column that ticks every 3 seconds, then it’s much more efficient to store initial value and fixed interval, rather than storing all data as ‘Time’ type, we will save significant amount of size in the resulting file size, as well as reduce I/O operations on the hard drive.
- column pruning – reading only requested columns
Spark leverages Parquet and give us a mechanism for partition discovery. Let’s take a look at an example of a partitioned folder structure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
path └── to └── my_table ├── Year=2016 │ ├── ... │ │ │ ├── Month=4 │ │ ├── Day=15 │ │ │ └── data.parquet │ │ └── ... │ ├── Month=5 │ │ ├── Day=12 │ │ │ └── data.parquet │ │ └── ... └── Year=2015 ├── ... |
As we can see data in a partitioned table is distributed across different directories where the values of partitioned columns are encoded in the name of each partition directory, such as Year=2016, Month=04, Day=15 etc. In other words, by having that structure we can be sure that data from April 2016 can be found only in /path/to/my_table/Year=2016/Month=4 directory. A table is just a root folder, /path/to/my_table.
There’s nothing really special about it, there’s no hidden magic or code adding some partition schema metadata, it’s only about keeping the file structure right. That means, you could prepare such structure offline, out of Spark awareness and then load the table with Spark. It’s also in line with the Hive partition layout, that means you can load existing Hive data and Spark integrates with Hive metastore anyway, while it keeps using its own Parquet reader & writer instead of Hive SerDe.
Shall we read something?
Whenever we read such a directory structure using Spark SQL, it will automatically discover the partition layout in the given directory for us by inferring the partition columns together with their values. They will be added to the resulting DataFrame in some sort of pseudo columns (similarly what Hive does underneath), see below example:
|
1 2 3 4 5 6 7 8 9 10 |
val df = sqlContext.read.parquet("/path/to/my_table") // load data df.printSchema() // print inferred schema root |-- column1: string (nullable = true) |-- column2: string (nullable = true) |-- ... |-- Day: long (nullable = true) |-- Month: long (nullable = true) |-- Year: long (nullable = true) |
If we now try to query the underlying data with a filter predicate on any of those partition columns, SparkSQL engine will optimize the query and read only the data that matches this filter predicate.
For example, if we run a following query:
|
1 |
df.filter("Year = 2016").show() |
then Spark will only read data from /path/to/my_table/Year=2016 directory, and the rest will be skipped (pruned).
Now I wanna load some data
Once we got such a partitioned directory structure, it is quite easy to load new data on a partition-by-partition basis (immutable data pipeline).
It usually happens that any sort of batch processing is done on a schedule, such as daily, weekly or monthly. If we have our data partitioned also by any of those attributes, then it’s really only about replacing a proper directory with new data.
Unfortunately, we have to handle this on our own, since Spark does not yet provide an easy way of overwriting only selected partitions. If we take a look at DataFrameWriter scala API we can see following methods (there’s more but we want to focus on these ones):
- partitionBy(colNames: String*): DataFrameWriter – partitions the output by the given columns on the file system, in exactly the same way as we already described
- mode(saveMode: SaveMode): DataFrameWriter – specifies the saving behavior when data or table already exists
and options we got for SaveMode are:
- Overwrite – overwrite the existing data,
- Append – append the data,
- Ignore – ignore the operation,
- ErrorIfExists – default option, throws an exception at runtime if it already exists
At first glance, it may look as if we got all we need, because partitionBy will do the trick and we don’t have to take care of anything. However, it turns out that we can’t rely on it and replace only selected partitions. What I mean by that is that, if you load new not-yet-partitioned data into DataFrame for a given batch window, you have literally two options when you try to save it into your existing production table by calling the partitionBy method:
- Overwrite your existing table with Overwrite option – watch out, it will delete or your existing data permanently!
- Append the new data to the existing table with Append option – watch out, it will create duplicates if you are trying to re-load an existing partition! To overcome that, you would need to load existing data for those partitions, merge with new data, remove existing data from existing table and finally append merged data to that table. It’s quite complicated, isn’t it? but it more or less follows the way we do it in RDBMS with partitions in place.
Anyway, for our immutable data pipeline, it looks as if neither option does the right job for us. What we really want is sort of OverwritePartition option that would only replace the selected partition data. Hopefully, in the future Spark will provide such option, but for the time being we have to handle this on our own.
It literally means we have to write new data on a partition-by-partition basis, directly to a proper partition directory. For example, if we got new data for 2016/1/1, we need to save it to /path/to/my_table/Year=2016/Month=1/Day=1. That also requires implementing some sort of utility code that will be responsible for building proper partition file paths.
In some systems, it may be the case that your batch window date (technical date) has really nothing to do with the actual business date which describes the real events. These dates along with events data are in the ingested file. For example, on a daily basis, you may get data from different business dates, such as sales that happened for few past days.
Luckily, we can still apply the same concept, which is to decouple those two dates and add them individually to our partition schema hierarchy, where the batch window date would be at the very bottom of our partition schema hierarchy. Having had this technical batch window date we will be able to keep our data pipeline immutable and replace the partitions in the same way we described above.
Apart from being able to reload snapshot data on a partition basis very easily, such an approach also allows you to do some analysis on a partition basis as well. For example, if your business requires you to validate daily whether you have any duplicates, then you just have to run your analytics with daily partition data iteratively, which requires way less memory than your all existing data in the table. Can you imagine a hash algorithm removing duplicates on a set with petabytes; that will grow up in the course of time even more? Additionally, just by looking at your structure directly from your partition schema, you can immediately say what kind of data you have at the moment. I’m also sure you don’t want to put all your data into a single container.
Conclusions
Hopefully, I’ve shed some light on the importance of partitioning your data even in Big Data ecosystem. Some may disagree, saying that you can scale your cluster & storage to mitigate performance issues, but hey, shouldn’t we solve software issues firstly? Making your software right has the potential to sky-rocket your performance; which is often not possible throwing hardware at a performance problem. We’re also obliged to do things right, maybe not perfect, but definitely wisely, using our craftsmanship. Apart from the performance gains, it also allows you to keep your data in a structured manner that make some things simpler.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments