
Data Pipelines can orchestrate many activities, creating a flow for data ingestion. One of these activities is the notebook execution activity.
However, every time a data pipelines executes a notebook, it creates a completely new session and spark pool.
This makes the Data Pipeline very slow and expensive.
How bad it can be
Imagine your pipeline will run a notebook inside a loop. The loop executes the notebook many times.
Each execution means a completely new spark pool. This is expensive.
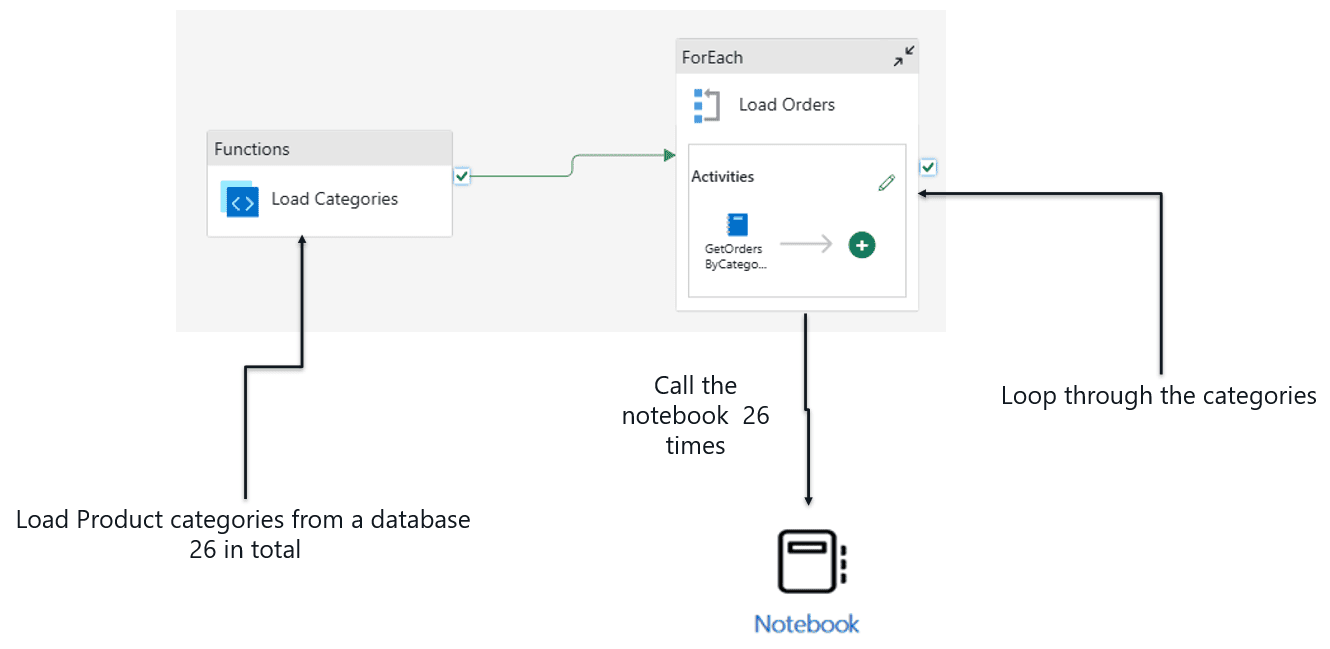
Besides being expensive, the default configurations for a spark session and a capacity will not support this running in parallel. You will need to limit the number of parallel notebook executions, using the ForEach activity, like in the image below
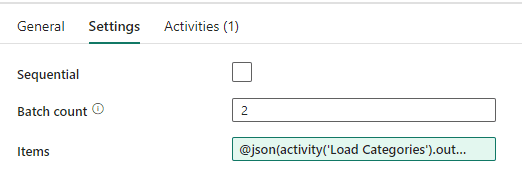
High Concurrency to the Rescue
The solution is to enable High Concurrency for Data Pipelines running notebooks. This can be done in two steps:
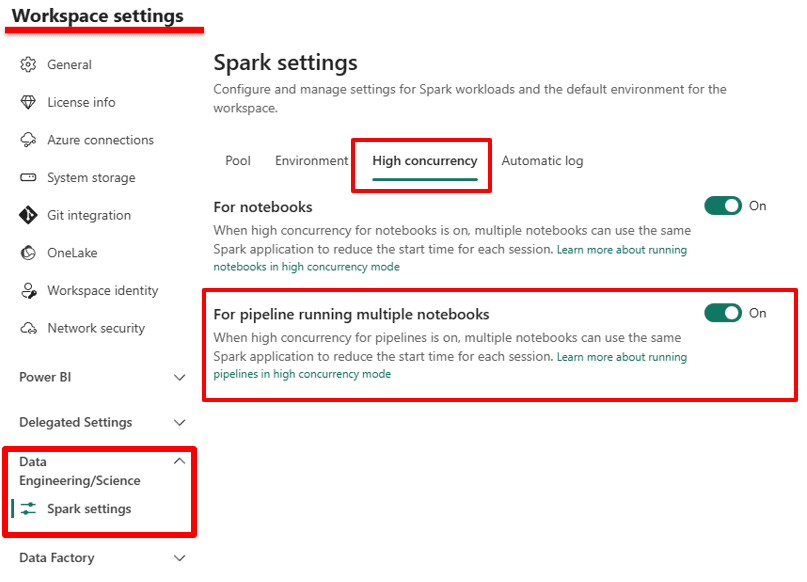
- Enable this configuration in the workspace settings
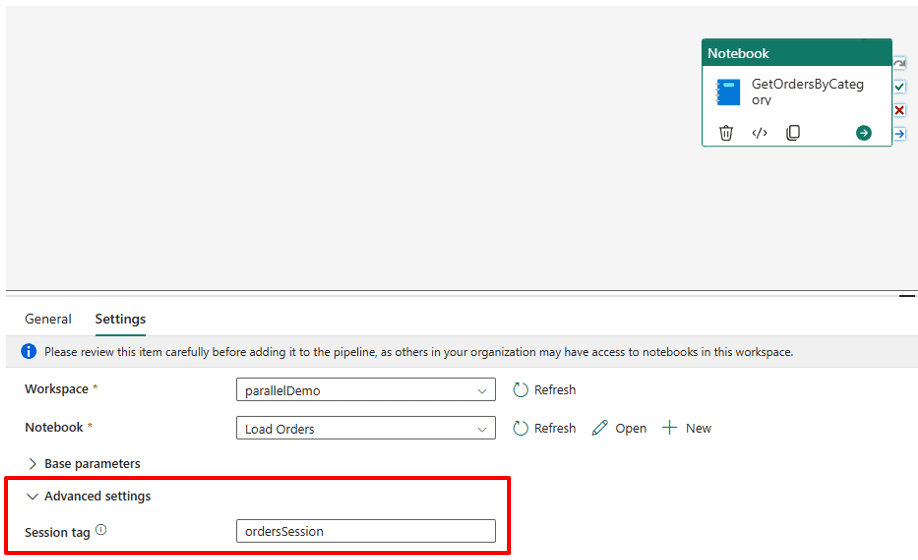
- Configure the session tag in the notebook activity
In the workspace settings, you find this option to be enabled in Spark Settings, like in the image below:
After that, the Session Tag configuration defines which notebook activities will use this feature or not. You can create groups of notebook activities running each group in a different session. You can use any string as “Session Tag”
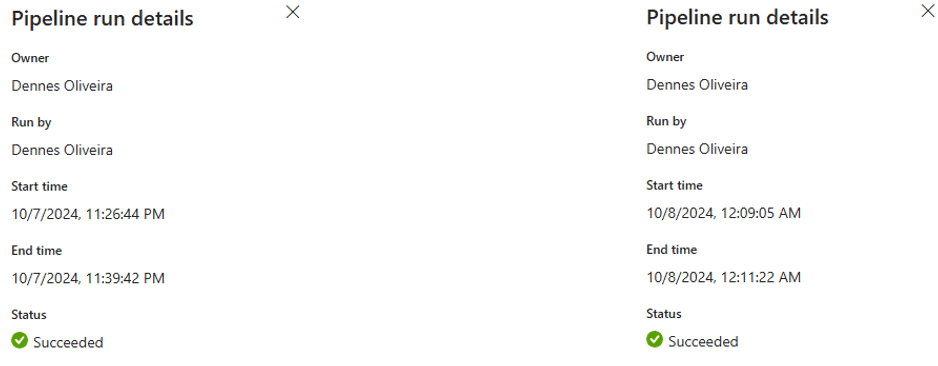
The High Concurrency Results
The image below shows a comparison between the execution without high concurrency and with high concurrency.
The execution time dropped from almost 13 minutes to less than 3.
References
Fabric Monday 55: Pipelines High Concurrency to Save Yout Time and Money
Summary
If you plan to orchestrate notebooks using Data Pipelines, the High Concurrency configuration is essential for you
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments