

Introduction
Like any other modern-day application, our website was expected to provide a low response time for requests even at peak loads. With millions of users, we process large amounts of data rows from Google Datastore, and not having a server cache was leading to additional latency and cost from datastore reads. To solve this issue, we decided to cache the processed data in Redis and avoid frequent hits to Datastore. GCP provides managed Redis, so we decided to use Memorystore. We were expecting this to be a simple caching solution that will solve all our issues. Everything worked fine during testing (as always), but during peak loads on production, the website crashed and was down for a few minutes till we figured out the real culprit. It took us a couple of months to identify all the issues, fix them at various levels, and stabilize the system.
This paper will list down all the challenges we faced and solutions we implemented while working with GCP Memorystore.
Memorystore Overview
Before we deep dive into the incidents and solutions, let us understand how we used Memorystore Redis in our application. In the below section, we will look at the following:
1. Different parameters for Memorystore Redis used in our application
2. What are the limitations of Google Memorystore Redis over Open Source Redis?
3. Integrating Memorystore to Serverless/PaaS
1. Different parameters for Memorystore Redis used in our application.
One of the significant differences in GCP Memorystore is that we do not have full control over some of the parameters like Opensource Redis. Redis Memorystore comes in two-tiers, Basic and Standard. The Basic Tier generally fits for applications that use Redis as a store and can withstand a restart and flush. Standard Tier gives High-Availability using replication and automatic failover.
For our Application, initially we went ahead with the below configuration.
a. Version: Standard
b. Size: 5GB
c. Network Bandwidth for Redis: Depends on the size of the Redis (ours 750 MBps)
d. VPC network that hosts Redis system
Parameters which we have utilized in our application are as follows:
a. activedefrag – If enabled it can alleviate memory fragmentation which comes with some amount of CPU trade-off
b. maxmemory policy – It helps us enable Redis behavior when data reaches a certain memory limit. Default policy is volatile-lru
c. maxmemory-gb – Eviction policy [6] i.e which keys-evicting algorithm like LRU, LFU etc would takes place, once it exceeds the threshold of configured maxmemory-gb
There are many other parameters in Memorystore Redis like notify-keyspace-events, timeout, stream-node-max-bytes etc. and some parameter which cannot be modified like luatime-limit, hash-max-ziplist-entries, hash-maxziplist-value, activerehashing etc. [7]
2. Limitation of Google Memorystore Redis over Open Source Redis.
Here, we will examine in detail how Opensource Redis differ from GCP Memorystore Redis
1. Most parameters in Memorystore are preConfigured, which means we don’t have control over these parameters which makes Memorystore more restricted than Opensource Redis.
2. No support for Redis Clustering or Redis Sentinel.
3. Most of the commands like BGSAVE, LASTSAVE, and many more are managed with Memorystore service and are blocked for external configuration.
4. No support for AOF persistence.
5. The standard version of Redis does not allow reading of slave replica
3. Integrating Memorystore to Serverless/PaaS
The solution mainly consists of four components.
a. Serverless/PaaS services
b. Memorystore Redis
c. Serverless VPC connector
d. Google VPC.
a. Serverless services/PaaS.
Any serverless/PaaS service can be used to connect the Memorystore Redis
In our application, we have used Google AppEngine (GAE). A PaaS, managed and scalable solution which uses the Standard version of AppEngine, with F4_1G instance type and Python 3.7 in our case as a runtime. GAE is by default has its own network configured (unchangeable)
b. Memorystore Redis
As mentioned in the overview section, It is a fully managed memory datastore with submillion seconds access. Which stores lot of our application data
c. Serverless VPC connector.
Serverless VPC connector is used to connect AppEngine to VPC, which will handle the traffic flow between GAE and VPC environments. Additionally, you can configure the throughput capacity of the VPC connector.

Min. throughput: Minimum bandwidth allocated to the connector.
Max. throughput: Maximum bandwidth allocated to the connector (upto 1000 MBps).
d. Google VPC. To connect GAE with Redis, Redis must be inside a Google VPC, as GAE doesn’t reside on any of the project VPC by default we need a VPC serverless connector to connect it. As shown in Fig 2.1
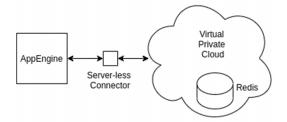
Fig 2.1
Data flows between AppEngine, serverless connector, VPC and then inside VPC, Redis.
Incidents and Solutions
Below are challenges we faced based on the series of events.
Incident 1. Memorystore Redis running out of memory
Incident Overview:
We did analysis to have a much smaller Redis instance of 5 GB. During heavy load, Redis exhausted sooner than expected. As part of the backoff mechanism, the default eviction policy i.e. volatile-lru should have kicked in, which could have saved our Redis from getting exhausted. It looked like volatile-lru doesn’t seem to work for our use case because some of the keys didn’t have TTL.
As a result, it slowed down requests coming out of cache and finally impacting the performance.
As an impact of slowness, it also increased the AppEngine instances (up to 3000 Instances) incurring the high cost for some duration of time.
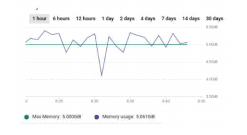
Fig 1. Redis memory getting maxed out
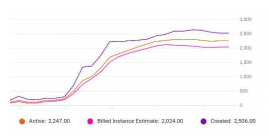
Fig 2. App Engine instances during the breakdown
Solution:
As a part of a solution, we increased Redis size and there was no max-memory set in our use case, so the eviction policy was triggered only if the memory was full. This time with maxmemory-GB configured to 60% of the total increased Redis instance size and eviction policy changed from default volatile-lru to allkeys-lru(could evict keys with no TTL); it stabilized our environment for a while.
Incident 2. Increased number of Redis socket timeout errors.
Incident overview:
After stabilizing the Redis infra, the problem with slowness and spinning up of huge instances persisted. Sooner this resulted in the choking of all web requests bringing the entire application down.
This time Redis was healthy, Infra was underutilized; still response time for the cache was relatively slow.
Upon analysis, we have found Redis client[3] (not an official client) doesn’t have the default timeout for the request. If the cache takes too long to complete; the client will be waiting infinitely to complete the request. AppEngine on the other side will keep spinning up the instances to serve more requests like this until AppEngine kills the hanged request after 60 seconds.
Solution:
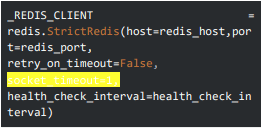
To overcome the problem of requests not being timed out, we configured the `socket_timeout`. If the cache is not responsive, the cache request should get a timeout, and the application fetches data from the primary database.
This solution ensures that our system doesn’t end up in a series of timeouts and hangs our application.
A sample code snippet with Redis client socket timeout.
Also, to reduce the load in the Redis cache, we increased the TTL for the most used data. This will make sure we don’t do unnecessary writing to the Redis cache, and the load is reduced to some extent.
This solution helps us to avoid breakdown mode, but the mystery behind slowness continues.
Incident 3. The Increased latency.
Even after adding the socket timeout to the client, we were still facing the problem with increased latency. One of the phenomena we observed that might be the reason behind the slowness was the series of timeout inception. Let’s consider an example if an API has 4 cache calls to the Redis and each of them is timing out after 1 second the total time API took just for timeout will be 4 seconds, this would unnecessarily add lots of second to latency.
Solution:
To solve this problem we added a backoff mechanism that could overcome this cascading effect of timeouts. In the following solution, we have made sure, if any of the cache requests are timed out, then all the other following requests in an API should go to the primary DB rather than requesting from hanged instance of cache. This will save our API to add unnecessary timeouts if the Redis instance is not responding for a while.
Incident 4. Not good enough latency and Real Culprit.
Even after adding a backoff mechanism that improved the latency of the application a lot, the response time during the high traffic scenario was not satisfactory enough and it was eventually increasing the cost to the environment.
Till this moment, we were always blaming the Redis Infra as the cause, but one of the components we forgot to look into; which connects our application to the Redis DB was the VPC connector.
We found that the bandwidth of the VPC tunnel was set to the maximum limit of 300 MBps which eventually became a choking point for our application, which was then discovered as a real culprit behind slowness.
This one thing increased latency, instances, and cost in our application.
Solution:
The obvious solution is to go ahead and increase the bandwidth of the connector but Before increasing the bandwidth of the VPC connector, the thing we have to keep in mind is a VPC connector once created cannot be edited, so you have to create a fairly new connector to increase the bandwidth.
This time we changed the maximum throughput bandwidth to 1000 MBps which is also the limit for the VPC connector.
For a bigger use case than us, 1000 MBps bandwidth won’t be enough; that is something the Google Cloud team is working on. Soon they will be upgrading their instances to give their customer more bandwidth.
This solution has stabilized our environment, improved our latency, and redis timeouts were mitigated.
Incident 5. Continuous alert raised by Google monitoring for Redis memory and calls. A cost optimization approach.
After stabilizing the environment we were getting lots of hits on the Redis which were raising a lot of alerts in the system, sometimes network out bandwidth used to exceed 10 GBPS of speed, though newer changes in the VPC supported this amount of request we were in constant fear that our environment might break; also the cost of our environment was not satisfactory.
We wanted a solution that would reduce the dependency on Redis, improve the latency, and optimize the cost of the environment further.
Solution:
To overcome this challenge, we have written a 2 layer caching mechanism; which consists of the first layer as Local system cache and the second layer as Redis cache.
The Local cache layer is subdivided into Python memory stack and file system cache.
The idea behind this technique was, we will store user-specific information in the Python memory stack and common information which is used by most of the users in File System Cache inside the instance memory.
The illustration of the cache mechanism looks something like this.
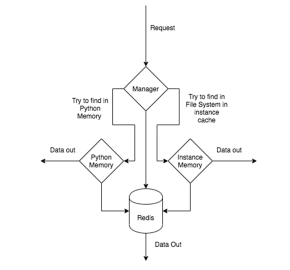
Fig 3. Two-Layer Caching Mechanism
When a request hits our application cache, the manager knows if the information is common to the user and or the information is user-specific.
Also to limit the memory utilization for the File system cache we have restricted the file system cache to use 100 MB of the instance RAM.
The following solution has reduced dependency on Redis by 85 %. The below graph shows the load before and after this change
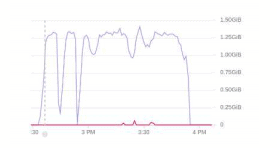
Fig 4. 1 Before Local cache changes.
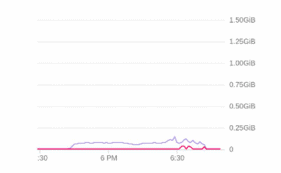
Fig 4.2 After Local cache change
With the mentioned solution, we can serve a load which is 4x times greater than the current load in the AppEngine.
As most of the data is being fetched from the local instance, the performance of the APIs was also improved.
Conclusion
A fully managed Memorystore option is a default choice when we have preference for serverless technologies. It is in the serverless solution, we must be more careful about the reliability of the application as the service comes with limitations. Till the time Google provides higher bandwidth for the VPC connector, the responsibility of ensuring the reliability will be with the Application team. The options provided in this paper should give a head start.
References
[1]. https://cloud.google.com/memorystore/docs/redis/r edis-overview
[2]. https://cloud.google.com/memorystore/docs/redis/c onfiguring-redis
[3]. https://github.com/andymccurdy/redis-py
[4]. https://cloud.google.com/vpc/docs/configure-serverless-vpc-access
[5]. https://cloud.google.com/appengine/docs
[6]. https://docs.redislabs.com/latest/rs/administering/d atabase-operations/eviction-policy
[7]. https://cloud.google.com/memorystore/docs/redis/r edis-config
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved

Load comments