

This continues and finishes my two-part series on warehouse load patterns. There are many methods to transfer rows between systems from a basic design perspective. This isn’t specific to any ETL tool but rather the basic patterns for moving data. The most difficult part in designing a pattern is efficiency. It has to be accurate and not adversely impact the source system, but this is all intertwined and dependent on efficiency. You only want to move the rows that have changed or been added since the previous ETL execution, deltas. This reduces the network load, the source system load (I/O, CPU, locking, etc.), the destination system load. Being efficient also improves the speed and as a direct result it increases the potential frequency for each ETL run, which has a direct impact on business value.
The pattern you select depends on many things. The previous part of the series covers generic design patterns and considerations for warehouse loads that can be applied to most of the ETL designs presented below. This section covers patterns I have used in various projects. I’m sure there are some patterns I have missed, but these cover the most used types that I have seen. These are not specific to any data engine or ETL tool, but the examples use SQL Server as a base for functionality considerations. Design considerations, columns available, administrative support, DevOps practices, reliability of systems, and cleanliness of data all come into consideration when choosing your actual ETL pattern.
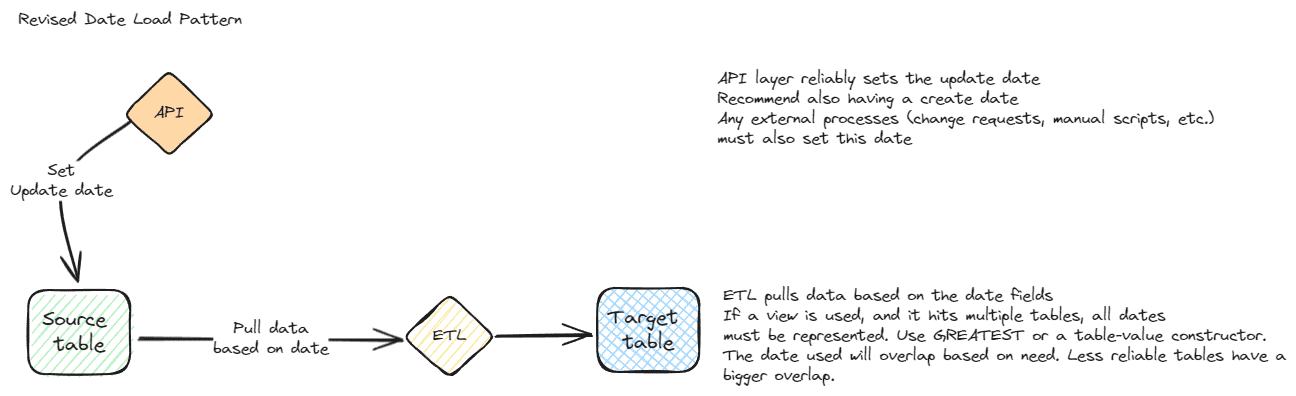
Revised date
Referencing a reliable revised date is one of the easiest methods to determine which records to transfer between systems. The flow for a revised date pattern starts with a reliable revised date. When using this pattern, you will generally want to add a revised date to every table, even if it isn’t currently being targeted by an ETL process. The revised date must be set every time a record is created or modified. Each ETL process uses the revised date to determine which rows to pull from the source system. No additional changes are required on the source system, but the ETL must know the last revised date that was pulled or use a sliding window. It is up to the receiving system / ETL system to establish the correct date.
A sliding window often works well for a revised date as it provides some redundancy and is a partial self-healing pattern. A sliding window just means that you overlap a specified number of days (or hours) to process data based on the revised date. So even if you have processed the rows in the table, they will be processed again when they are still in the frame of the sliding window. This is what makes the pattern self-healing, which is a goal for all ETL when possible. This redundancy is useful to retrieve missed records and is especially useful with unreliable sources. It may not be practical for very large datasets that change frequently as it is very redundant and can stress systems. Using an EXCEPT operator in the destination query can significantly reduce I/O and load times if you do overlap dates.
If a sliding window is used, it is a good idea to make it parameterized. This allows a reset or reprocessing of all the data, or a larger window, on a nightly, weekly, or monthly cadence. It’s better to anticipate problems like this and plan for the reset during the design phase.
The key to the revised date pattern working correctly is making sure the revised date is always updated when rows are modified. This must happen during API / application updates and direct updates via ETL or change requests running scripts directly against the data. If updates happen in an undisciplined manner, this pattern will have gaps. Applications and any other modifying items must always set the revised date. If ETL uses a view that accesses multiple tables, the update must happen for each base table. The revised date needs to be set in all tables, or you must make the assumption that if the date is updated in one table, it applies to all related tables. This makes the logic more complicated, especially if different ETL packages access the same tables or subsets of tables. Business logic will dictate how these rules can be applied. You may be able to use the primary table for determining when to move rows, but this could exclude important child rows. A better alternative is to add a revised date to the related tables.
The SQL Server function GREATEST can be used to select the maximum value from multiple tables. This requires Azure SQL or SQL Server 2022 or greater. If you are using an older version, a table-value-constructor can be used for the same functionality. Refer to the links at the end for details.
The self-healing pattern for this method is to reload data. As mentioned, the sliding window should be parameterized. The general method for the pattern is to have a separate schedule (job, trigger, etc.) that sets the date parameter back a reasonable time period and reload all data in that period. What is reasonable for one system may not be reasonable for another, Work with the business to understand how this should work. It might be 1 month, 6 months, or 10 years depending on how and when data can get updated. It also depends on the size and quality of the data.
The same pattern can be used with status columns or other columns that are set in a consistent pattern via application workflow. There is no difference between a status or workflow column and a revised date other than understanding the logic. A date column is very easy to understand and can be found using metadata and standard, easy data analysis. A status column requires a deeper understanding of the data and business logic.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
--Example showing GREATEST --Can be used for multiple columns and multiple tables --New syntax starting with SQL 2022 --Example uses WideWorldImporters SELECT TOP 10 I.InvoiceID ,GREATEST(I.ConfirmedDeliveryTime, I.LastEditedWhen, IL.LastEditedWhen) DeltaDate FROM Sales.Invoices I INNER JOIN Sales.InvoiceLines IL ON I.InvoiceID = IL.InvoiceID ORDER BY I.InvoiceID ,IL.InvoiceLineID GO --Equivalent to Greatest in SQL 2022 --Works with most database systems --table-value-constructor SELECT TOP 10 I.InvoiceID ,(SELECT MAX(D) FROM (VALUES(I.ConfirmedDeliveryTime),(I.LastEditedWhen),(IL.LastEditedWhen)) AS VALUE(D)) DeltaDate FROM Sales.Invoices I INNER JOIN Sales.InvoiceLines IL ON I.InvoiceID = IL.InvoiceID ORDER BY I.InvoiceID ,IL.InvoiceLineID GO |
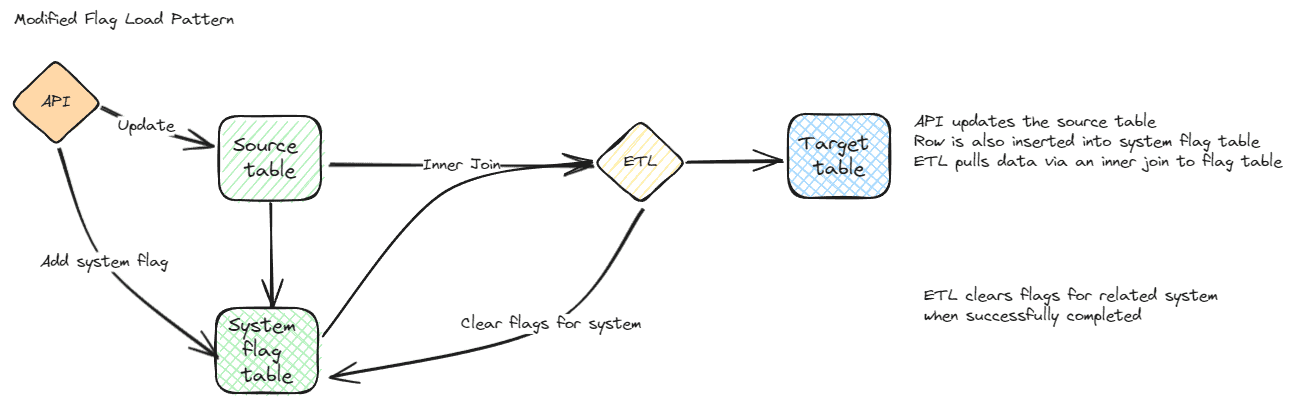
Modified flag
The flow for a modified flag starts with the table and application design. It must contain a column in your source table (or a separate table if working with multiple destinations) that indicates that the row has been modified. When a row is modified, by any mechanism, the modified flag must be updated. ETL processes then simply have to look at the modified flag to determine which rows should be transferred. When the transfer is complete, the modified flag is cleared for successfully transferred rows. In a system with multiple ETL hitting a table, the modified rows specific to that that external system are deleted in the modified table.
This differs from the revised date pattern in a few ways. It can have a lower impact to both the source and destination system when implemented correctly. You are only transferring rows that have changed. The flag lets your ETL target specific rows without a need for a sliding window or overlap. The development team needs to be diligent about setting the flag, but it works very well. It is also very simple for anyone looking at the tables to determine which rows will be sent during the next ETL execution. The major disadvantage is that the self-healing patterns are more difficult to implement.
A column that is set when data is changed, a modified flag, is simple for receiving systems to query. This can be a single flag column indicating that the row needs to be loaded or it can show which rows need to be INSERTED, UPDATED, or DELETED. It can also be a separate table showing the columns that were modified since each system last ran an ETL process against the source table.
This is similar to the revised date in that it requires the source system to consistently update the column, or modified table. If there is a gap in this process, updates will be missed. No matter how the data is updated, this flag, or all flags, must be set. This sounds simple, but it is easy to miss this flag if change requests, ETL, ad-hoc procedures, service tickets or bulk logged operations are run against the data. All team members must know the proper procedure and follow it assiduously. Even a single gap in your procedures will require a reload of the data for your destination systems. A trigger can be used to maintain the data, but there are scenarios that bypass triggers and they must be taken into consideration.
A single flag for all systems is the easiest to implement from a source perspective and is easier to maintain but complicates ETL. A single column in the source table also makes it more likely developers will remember to modify it if they are writing an ad-hoc script. It’s harder to ignore a column in the table you are currently working on rather than a separate table. If more than one system receives data from this table, it can get complicated. All of the ETL packages need to be run at the same time or a date must be added to the table that shows when the modified flag was last updated. Each destination system then can grab records changed since the last time it was run. But this quickly becomes an analog to a revised date and I would use the next pattern instead.
The multi-system modified flag is harder to maintain, but makes the ETL process much simpler when there are multiple targets. This should be kept in a separate table, even though it may be tempting to add multiple flags to the source table. This is a separate table that records the primary key and each destination system on separate rows. Using a separate table reduces the impact to the source system design, it keeps the source table as small as possible while following normalization patterns, and it allows additional destination systems without coding changes to the source. A cross join to a domain table containing all of the destination systems makes the process very simple. I would also put all modified tables in a separate schema to maintain clarity of purpose. This also allows easy differentiation of security, which can be useful depending on your design.
Deleted data can be handled with a separate flag, a deleted flag. A deleted flag is as simple as it sounds. When a row is deleted, the deleted flag is set. This clearly won’t work if the modified flag is maintained in the actual table and requires a separate table. The regular modified flag in the modified table can also be set as long as the ETL and the receiving applications understand that the flag must be compared against the source system, and records marked as modified without a corresponding source record have been deleted. If that sounds too fragile, use a deleted flag or the next technique. The sure method to find deleted records was described in the first part of this series. To briefly summarize, all primary keys, and only the primary key columns, are transferred to the destination system. An anti-join is used to find records that have been deleted. This can also be used for a particular date range or record range, but more care must be taken to ensure extra rows aren’t accidentally deleted.
Potential gaps were mentioned above in the requirements, but if any process does not set the modified flag, there will be missed rows. Be especially careful of change requests, ad-hoc processes, and bulk logged operations.
The self-healing pattern for a modified flag is to simply set the update flag for all rows or all reasonable rows if you are able to limit them. The next time the ETL runs, rows will be picked up again. This can be quite expensive, from a resource perspective, if the table is large. As mentioned in the revised date section, an EXCEPT operator in the destination merge can be useful here too.
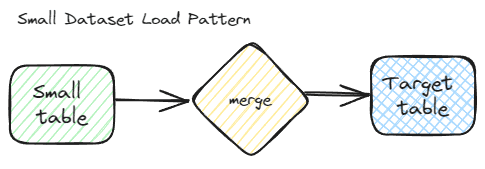
Small dataset
A small dataset is often best handled by reloading the entire dataset every time the ETL runs. Considering development time, troubleshooting, testing, and other factors for a more complicated ETL process, a simple full reload is often the best choice for this scenario.
When the ETL pipeline runs, all rows are transferred, every time. This also means that you don’t need a separate table or logic for the delete logic. If the data isn’t available in the source, the delete logic is applied to the destination. I say delete logic since this can differ by system and include actually deleting rows, flagging them, or archiving those rows. You also don’t need a date or any workflow logic. When the ETL runs, a full merge with insert, update, and deletes, are executed against the destination.
The self-healing pattern for this is obvious – you just need to wait for the next execution of the ETL pipeline. Nothing else is needed to fix any issues with missing data, barring logic bugs. You may need to run a pipeline earlier, but that is the extent of the self-healing required for this simple pattern.
There are also very few gaps with this pattern. If the source query is correct and you get no errors during the ETL, it should be a smooth process. There may be standard issues that are managed via data integrity constraints. They may be defaults, primary keys or unique constraints. These constraints aren’t as common in reporting systems though, and are likely not necessary.
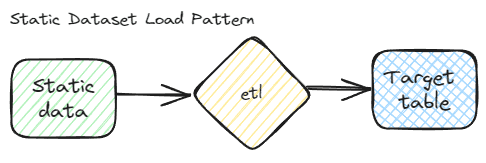
Static dataset
A static dataset can be loaded via a few methods, but the best way will often depend on the size of the dataset. This is often accomplished in the same way an initial load would be managed but it is usually a good idea to have an automated method to load this data. It can be a full ETL package, a simple BCP script, or a post-deployment script in your DevOps pipeline. Even datasets that are defined as static by the business have a tendency to change over time. The changes just happen very slowly or with large time gaps between changes.
Technically, no delta pattern is needed for this method, but the natural key still needs to be defined. This will assist with future needs and is also required to match the data to other tables in your reporting system. Even without deltas, you may need to break the data into multiple pieces to facilitate the load process. This will also help with reloads later if they become necessary.
The self-healing pattern for this method is to reload all of the data. This will usually only be necessary if there is a system error.
There also aren’t many gaps possible with static datasets. The primary gap is when the business decides that the data isn’t static and needs to be updated. At that time, you will need to reload everything, including the new data, or a standard ETL process will need to be created. Often, the business does not realize how changes happen or the actual frequency of data modifications. This is where you will need to analyze the data and also evaluate the rigor of business processes. If there is less rigor than is acceptable, you probably don’t want to assume the data is static and will instead want to create an actual ETL process.
History table
There are several types of history tables available natively in SQL Server, including system-versioned temporal tables (temporal tables) and Change Data Capture (CDC). Other database engines may have similar functionality. For instance, Sybase has functionality called a Transfer Table, which extracts rows modified since the last time an extract was run. Generic history tables are available in SQL Server via triggers. This is also possible in most modern database engines with triggers. A third option for maintaining a history table is via the application or existing ETL process. This requires programming and is more prone to gaps in the data, but it may fit your scenario.
The initial part of the flow for using a history table for ETL is administrative. The history table, whichever kind is available and chosen, is setup first. The ETL then simply pulls changed rows since the last time it was run. This can be a direct query against the history table or it may involve specific syntax, as in the case of temporal tables and CDC. The syntax will differ based on the type of history table. A sliding window can be used if the environment is unreliable. This can be based on the date or by an ID column in the history table. Again – the method depends on your implementation. Consistency and reliability should be your major considerations. The remainder of the ETL is similar to any other delta based ETL pattern. History tables such as temporal tables also record deletes and the regular flow can be used to delete rows as well as update and insert new rows.
The self-healing pattern for history tables is to set the date or ID back to an earlier date and re-run. If there are additional gaps or the history table was disabled for a period of time you may need to perform a complete reload. This would be similar to your first load. Think about potential gaps in your implementation and try to account for these possibilities in your ETL design.
There are several gaps that are possible when using a history table. Temporal tables and CDC can be disabled. This can happen during a failed DevOps pipeline or even an extended deployment when the tables are modified. Modifying the parent table of a temporal table requires disabling the temporal table to make schema changes. During this deployment window, especially if there is an error, can result in missed history rows can be missed. If using triggers, they can also be disabled or bypassed with bulk-logged operations. If using a custom solution that depends on the application, the normal gaps mentioned in other sections can happen such as change requests or ad-hoc updates not correctly updating the history table.
History tables can be very easy to implement as an ETL pattern but care must be taken. It isn’t bulletproof, but there are methods that can be used to make it more reliable. If your processes are rigorous and your DevOps patterns are well established, it is reliable and easy to implement.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
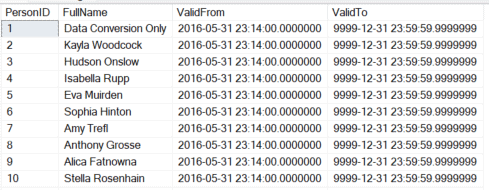
--New rows since last ETL --In temporal tables, the ValidTo date of '9999-12-31' indicates a current record DECLARE @DateStart datetime2 = '2016-05-30 23:14:00.0000000' SELECT PersonID ,FullName ,ValidFrom ,ValidTo FROM Application.People FOR SYSTEM_TIME ALL WHERE ValidFrom > @DateStart AND ValidTo = '9999-12-31 23:59:59.9999999' ORDER BY PersonID GO |
|
1 2 3 4 5 6 7 8 9 10 11 |
--Deleted rows since last ETL DECLARE @DateStart datetime2 = '2016-05-30 23:14:00.0000000' SELECT * FROM Application.People FOR SYSTEM_TIME ALL DelRows LEFT JOIN Application.People CurrentRows ON DelRows.PersonID = CurrentRows.PersonID WHERE DelRows.ValidFrom > @DateStart AND DelRows.ValidTo < '9999-12-31 23:59:59.9999999' AND CurrentRows.PersonID IS NULL ORDER BY DelRows.PersonID GO |
Data without updates – INSERT / DELETE only
An insert only ETL pattern is a specialized pattern that I’ve seen used by some vendors with very large, quickly changing, unreliable datasets. This pattern also works very well for moving binary values, XML columns, images, geospatial data and other large data types when it is insert only. You don’t want to transfer large data of this type more than absolutely necessary, so if data is only added and is large, this is a good method. To use this pattern, the source system maintains a list of rows sent to each destination system. The ETL then just needs to perform deletes and inserts. The primary reason I have seen vendors use this pattern is when the natural key is unreliable or changes frequently, such as large public datasets for property assessments. This also works when the GUI submits data changes to the back end without a good natural key. All records for a subset of the multi-column natural key are deleted and the new rows from the front-end application are inserted.
This pattern relies on the source system knowing which records should be sent to the destination. If a sequential, numeric, artificial key (identity column) is used, the maximum key sent to each destination can be maintained. If it is a non-sequential key, something like a GUID, a different pattern is required. Usually, the keys need to be recorded between pipeline executions. The burden for recording IDs is usually with the source system. The target system should still check for matching records to be sure there are no duplicates.
Deletes can be managed separately if needed. Use the standard delete pattern for your warehouse, but I will once again refer you to the delete pattern in the previous part of this series. This ensures all deletes are captured and is a relatively lightweight from a data perspective.
Gaps for this pattern happen when rows are deleted and inserted on the source without getting recorded. An insert date can be used as a secondary indicator that the base table has changed. Additional safeguards can be put in place, such as a history table, that will help ensure all changes are captured. If an identity column is used, the previous ID used for ETL can be used instead of a full reload. If you maintain the complete list of records sent to each destination, gaps will automatically be filled in during the next ETL execution.
The self-healing pattern for this ETL scenario is executing the ETL again. Rows that were missed previously should be recorded for each destination. If rows have been missed, and there is a major issue, a full reload is the only choice. A secondary indicator, such as an insert date can allow a more pointed healing pattern. The scenario I’ve seen involving very large datasets and full loads put a lot of demands on the system and took many hours to reload, so you will want to avoid them if possible, or limit how frequently you do a reload.
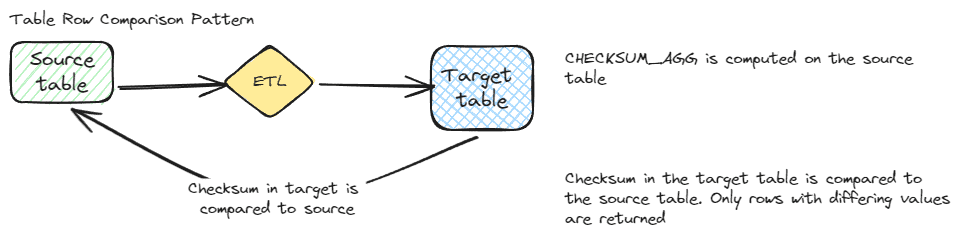
Table row hash comparison
SQL Server has several methods to create a hash over a row or only certain columns in a row. This hash can be checked against the destination system to determine which rows should be transferred for each ETL run. The basic flow for a row comparison requires a hash to first be created on the source row using CHECKSUM(), BINARY_CHECKSUM(), or CONCAT() combined with HASHBYTES(). The hash is compared against the current hash for the destination system and only rows without matching hashes are transferred. No extra comparisons need to be done and it is a robust pattern with fewer gaps than most patterns. Deletes can be sent via a separate flow or they can be managed as part of a complete comparison.
The major advantages to this pattern is that changes can’t be missed if the hash is set, it runs quickly, there are multiple options for implementation, including creating the hash as a default or a computed column. The hash can also target specific columns rather than the whole row depending on what is needed for the destination systems.
The big disadvantage of this pattern is the need to compare all rows each time the ETL is run. This is still a very fast comparison since you are only comparing two hash columns against each other. This pattern can also be combined with a date pattern to limit the possible rows updated. The other disadvantage of this pattern is that there are limitations on the data types supported with some of the hash functions. The CHECKSUM() and BINARY_CHECKSUM() don’t support images, ntext, text or XML types. This may not be a concern for your database, but be sure this won’t impact your implementation.
There aren’t many gaps to the pattern. If a hash is set incorrectly, that row will be transferred during the next transfer. If a row is missed, it should get caught during the next transfer. If there are major issues with the hash for the destination system, the self-healing pattern is to reset or delete the hash for the destination system. When the next comparison happens, all rows should transfer due to missing or mismatched hashes.
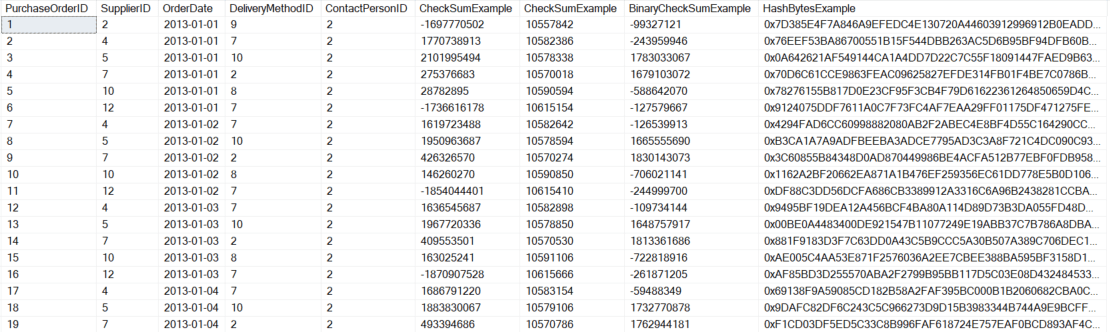
The following example shows a few different ways to generate a hash. Note that they are all deterministic (return the same result if identical inputs are given) and useful for row comparisons.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT TOP 100 PurchaseOrderID ,SupplierID ,OrderDate ,DeliveryMethodID ,ContactPersonID ,CHECKSUM(*) CheckSumExample ,CHECKSUM(SupplierID,OrderDate,DeliveryMethodID,ContactPersonID) CheckSumExample ,BINARY_CHECKSUM(*) BinaryCheckSumExample ,HASHBYTES('SHA2_256',CONCAT(SupplierID,OrderDate,DeliveryMethodID,ContactPersonID)) HashBytesExample FROM Purchasing.PurchaseOrders ORDER BY PurchaseOrderID |
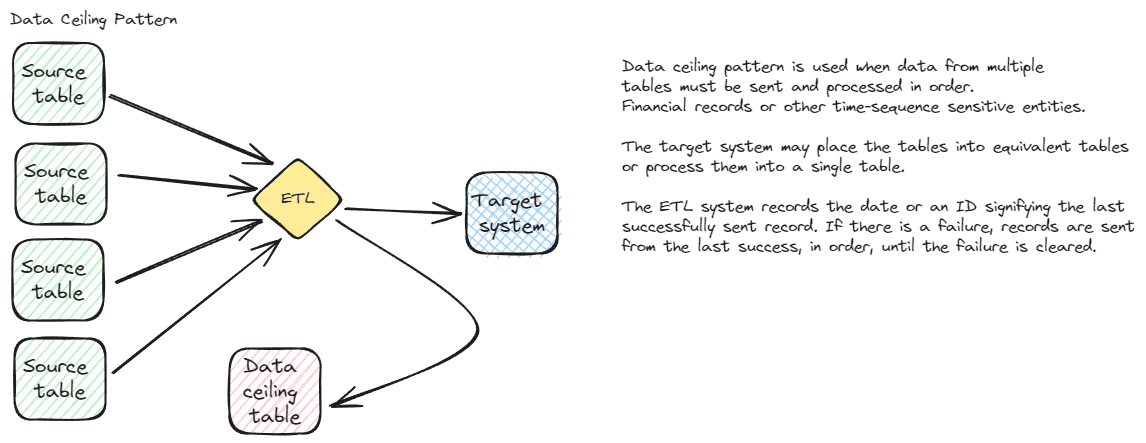
Data ceiling
A data ceiling, also called a high-water mark, can be used to process data with interdependencies that must be processed in a particular order. The flow for this pattern is simple in concept, but the logic can be complicated depending on the interdependencies. A date or primary key column is recorded for each set of data to be transferred. The data is transferred, using whatever logic is needed for your application or the destination system logic. When the transfer is confirmed as successfully finishing, the date or primary key is recorded in the source system. If there is an issue with the transfer, the key field isn’t updated, so the next time the transfer runs, rows are reprocessed. The reprocessing is automatic, but usually will require data getting fixed in either the source or destination depending on the particular error.
This is clearly a more complicated pattern and will only be selected if this type of intricate logic is needed to transfer data. It might be needed to move data to your payment processing system or another transactional system with data shaped differently and with different dependencies. The gaps in this pattern will generally be bad data. That data needs to be fixed in the live system. The next time the ETL runs, everything should process successfully. If there is a bigger issue, the date or ID can be set backwards to an earlier starting point. Since this is very logic dependent, setting the key field back may or may not work. You don’t want to reprocess payments or cause other duplications, so each system using this pattern will have a different method for fixing issues.
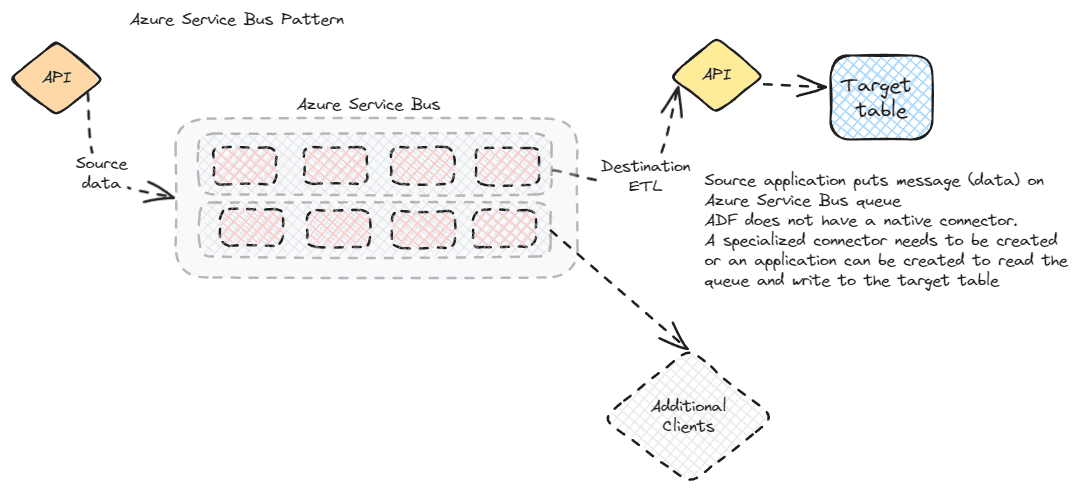
Service bus / message broker
Data that needs to be pushed to multiple systems, in near-real time, may be a candidate for a message broker. The Azure Service Bus is a message broker that follows the AMPQ (Advanced Message Queueing Protocol) standard and allows messages to be placed on a queue and picked up by any authorized system.
This is a more complicated flow for traditional reporting or warehouse systems. You will want to carefully examine if this fits your needs before you build a message broker system specifically for reporting. This is a more likely candidate if you already have service bus implemented and need the same data for your reporting system. It also requires developers with a different skillset than might be found with traditional ETL developers.
For this flow, the source system places a record (message) on the queue via the API layer of the application. Any authorized consumer can then pick up the message from the queue and write it to their system. In a SQL Database with ADF scenario, your choices are limited. ADF doesn’t have a native connector. Refer to the Microsoft article in the references section, but you have a few options. You can create a custom consumer, use the ADF Web Activity, or you can route the messages to blob storage, then pick them up in ADF via a Blob Event Trigger. Other ETL systems will have different patterns, but as long as they can read from a message queue, they will be able to use this mechanism.
This isn’t great for warehouses or standard reporting systems. You are consuming data a row at a time, which is not efficient for SQL systems. It has the allure of near-real time consumption of data, but it is more taxing on the system and you will need to decide how to reload the system in the event of an error or gap in processing.
There isn’t a standard mechanism for the initial load or for repopulating the destination system in the event of an issue. These scenarios need to be accounted for but will likely involve a separate ETL process. If you need the near-real time data it may be worth it to build the redundant systems.
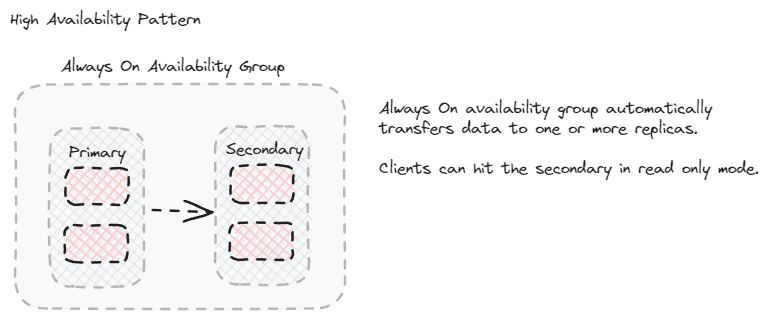
High availability options
For reporting databases that need near-real-time data and are able to efficiently query a copy of the transactional database, one of the native high-availability options may be a good choice. The flow for implementing this pattern will vary, but are primarily administrative tasks rather than development tasks. Once the high availability configuration is complete, the data can be used in a normal manner, but pointing to the read-only copy of the data. This can be a read-only replica in an always on availability group, it can be the copy in a log shipping scenario, it can be the subscriber in a replicated database, or it may be part of a Windows failover cluster.
If you aren’t the DBA or system administrator for the server, this is the simplest method to implement. Once it is setup, you just query the read-only instance(s) of your server. No additional changes are necessary and no ETL is involved. Everything is handled by the server infrastructure and SQL or Azure services.
It’s important to go into more detail about the query efficiency statement. The methods described here do not modify the shape of the data. If your tables are efficiently designed and return data quickly for reports, they may be good candidates. If the indexes support the reports you want to create, consider this option. Some scenarios allow you to modify indexes, but others are limited to what is on the primary system.
Security for this scenario is also a large part of the consideration. In a high-availability scenario, you may be limited to the users that can access the primary system. You don’t want to grant access to too many users. This is a better pattern for application created reports, taking load off the primary instance, or canned reports. This is generally not for ad-hoc queries due to the security setup. Even when you are able to change security options and allow more users, you will still want to be cautious. Excessive locking can cause issues with the data replication.
There aren’t obvious gaps with this pattern, but the data can get out of synchronization due to network or system issues. When this happens, there are built-in mechanisms to re-synchronize the data. You will likely need to get the DBA team involved in this.
API duplication
API duplication is another easy pattern to understand. When your application writes to the database layer, it also writes to a warehouse or reporting layer, using the same logic. It allows you to remove the load from the transactional system for reporting and ensures the logic is the same. The downside of this is that the data is generally not shaped in a manner that is as efficient for reporting. You can alter the table design into facts and dimensions, but it then adds even more overhead to the API layer.
This might be preferred if you have a strong development team and are understaffed in the data area. It can also be a preferred pattern if the database layer and the reporting layer use different technologies. In other words, this can be used if you can’t scale out to the reporting layer using the built-in methods listed in the previous section. It works with any database system and the systems involved can be disparate. They can be different engine versions or even different technologies. This also offers the benefit of keeping the reporting database in synchronization in real-time or near-real-time. This is similar to the high availability patterns, but it does generally incur more overhead.
The self-healing pattern for this method is to re-submit any transactions that fail. This should be automatically managed in the API layer when possible. If there is a major problem and large differences are present between the two databases a different method will need to be used. This should be the same method used to initially populate the reporting database. It could be something as simple as BCP, a more complicated ETL package, or a custom method that calls the API with all rows from the transactional database. As with most development tasks, exception handling can take a disproportionate amount of time and resources to implement. Be sure API duplication meets all of your needs before you commit to it. 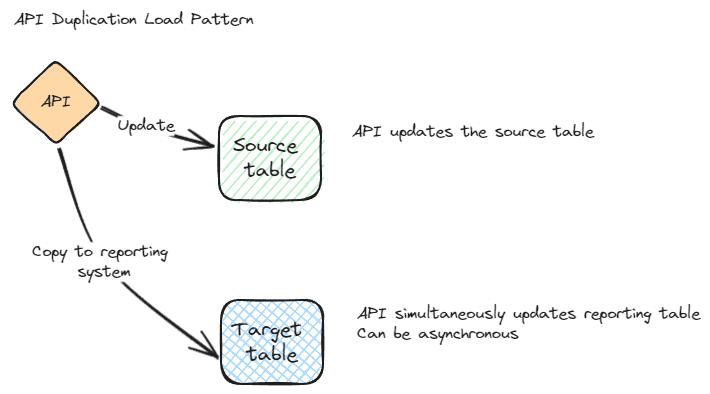
Summary
ETL processes are expensive to create from a development and resource perspective. They are less expensive than custom development, but the correct solution for your scenario needs to be carefully analysed. This presents several patterns that I have used in projects. Each has advantages and disadvantages. You will want to choose one or a small number of patterns and stick to them for each ETL process. Consider the frequency needed, technology available and approved in your enterprise, team strengths, and robustness of the methods before making a choice.
References
- https://learn.microsoft.com/en-us/sql/t-sql/queries/table-value-constructor-transact-sql?view=sql-server-ver16
- https://learn.microsoft.com/en-us/sql/t-sql/functions/logical-functions-greatest-transact-sql?view=azuresqldb-current
- https://learn.microsoft.com/en-us/sql/t-sql/functions/checksum-transact-sql?view=sql-server-ver16
- https://learn.microsoft.com/en-us/sql/database-engine/availability-groups/windows/active-secondaries-readable-secondary-replicas-always-on-availability-groups?view=sql-server-ver16
- https://learn.microsoft.com/en-us/answers/questions/111361/how-to-connect-service-bus-queue-to-azure-data-fac





Load comments