
In the last installment, I used the SQL Monitor tool to get a snapshot view of the current state of the servers at Red Gate that are giving us trouble. That snapshot suggested some areas where I should focus some time, primarily in which queries were being called most frequently or were running the longest. But, you don’t want to just run off & start tuning queries. Remember, the foundation for query tuning is the server itself. So, I want to be sure I’m not looking at some major hardware or configuration issues that I need to address first. Rather than look at the current status of the server, I’m going to look at historical data.
Clicking on the Analysis tab of SQL Monitor I get a whole list of counters that I can look at. More importantly, I can look at them over a period of time. Even more importantly, I can compare past periods with current periods to see if we’re looking at a progressive issue or not.
There are counters here that will give me an indication of load, and there are counters here that will tell me specifics about that load. First, I want to just look at the load to understand where the pain points might be. Trying to drill down before you have detailed information is just bad planning. First thing I’m going to check is the CPU, just to see what’s up there. I have two servers I’m interested in, so I’ll show you both:
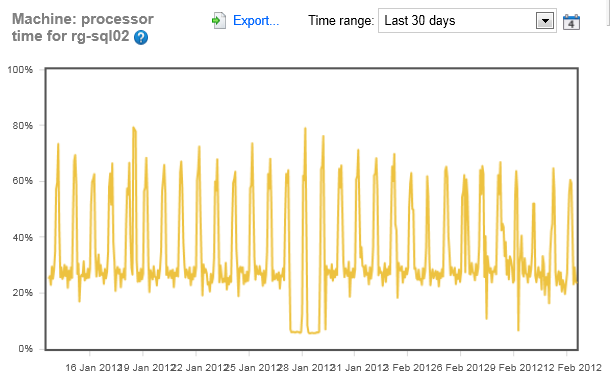
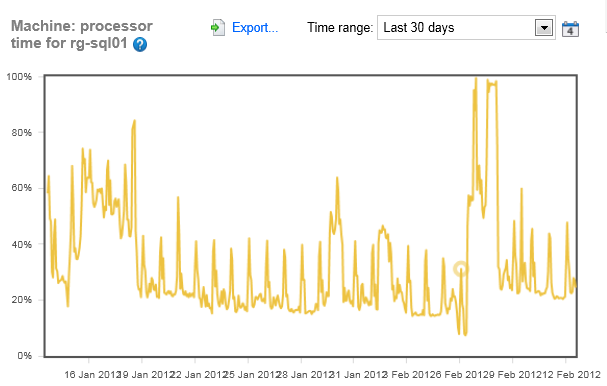
Looking at the last 30 days for both servers, well, let’s just say that the first server is about what I would expect. It has an average baseline behavior with occasional, regular, peaks. This looks like a system with a fairly steady & predictable load that probably has a nightly batch process that spikes the processor. In short, normal stuff. The points there where the CPU drops radically. that might be worth investigating further because something changed the processing on this system a lot.
But the first server. It’s all over the place. There’s no steady CPU behavior at all. It’s spike high for long periods of time. It’s up, it’s down. I’m really going to have to spend time looking at CPU issues on this server to try to figure out what’s up. It might be other processes being shared on the server, it might be something else. Either way, I’m going to have to spend time evaluating this CPU, especially those peeks about a week ago.
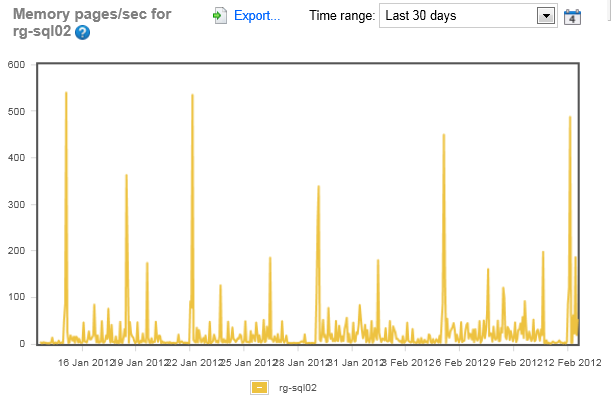
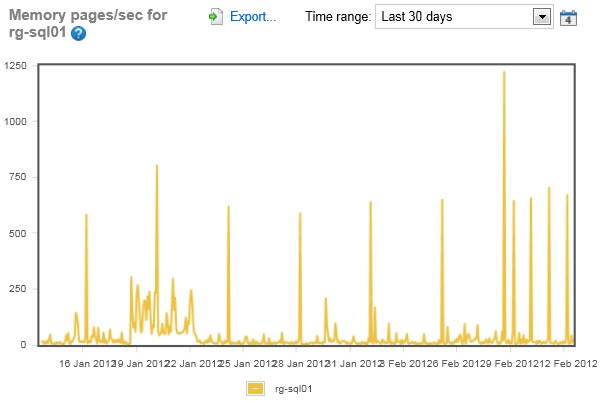
Looking at the Pages/sec, again, just a measure of load, I see that there are some peaks on the rg-sql02 server, but over all, it looks like a fairly standard load. Plus, the peaks are only up to 550 pages/sec. Remember, this isn’t a performance measure, but just a load measurement, but from this, I don’t think we’re looking at major memory issues, but I may want to correlate these counters with the CPU counters.
Again, the other server looks like there’s stuff going on. The load is not at all consistent. In fact there was a point earlier in the year that looks pretty severe. Plus the spikes here are twice the size of the other system. We’ve got a lot more load going on here and I will probably need to drill down on memory usage on this server.
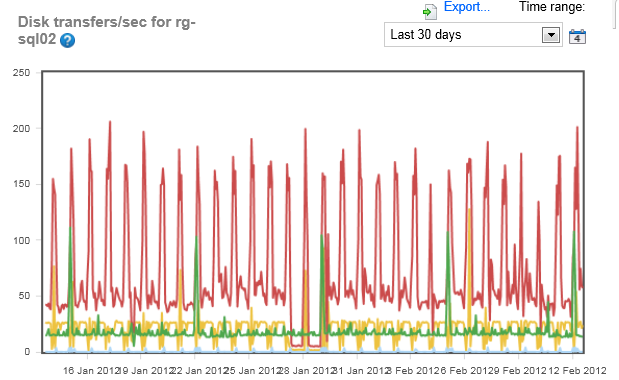
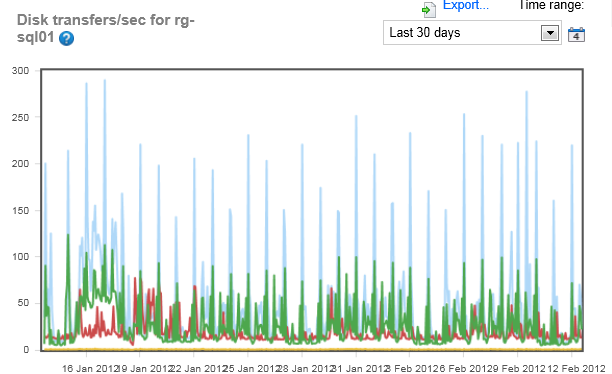
Taking a look at the disk transfers/sec the load on both systems seems to roughly correspond to the other load indicators. Notice that drop right in the middle of the graph for rg-sql02. I wonder if the office was closed over that period or a system was down for maintenance. If I saw spikes in memory or disk that corresponded to the drip in CPU, you can assume something was using those other resources and causing a drop, but when everything goes down, it just means that the system isn’t gettting used.
The disk on the rg-sql01 system isn’t spiking exactly the same way as the memory & cpu, so there’s a good chance (chance mind you) that any performance issues might not be disk related. However, notice that huge jump at the beginning of the month. Several disks were used more than they were for the rest of the month.
That’s the load on the server. What about the load on SQL Server itself? Next time.


Load comments