
To many people, System.Collections.Generic.Dictionary<TKey,TValue> is just a useful collection. In this post, I’ll be looking inside that collection and see how it really works.
Dictionary is based on a hashtable; for the rest of this post, I’ll assume you know roughly how a hashtable works. The Wikipedia article, as the source of all knowledge algorithmical, provides a good overview. It will also help if you’ve got the class open in Reflector so you can see what’s going on yourself.
The basics
The core of the Dictionary type is a standard hashtable, straight out of an algorithms book. However, it’s interesting design comes from how it deals with hash collisions, using a variant of chaining.
When you add an item to a hash table, the hash code of that item determines which slot in a backing array the item is stored. In the perfect case, every item would have a separate hash code, and so every item would have a separate slot in the array. To find an item, you simply hash it and go to that slot in the backing array.
However, two or more items can hash to the same hash code, and you get a hash collision. When this happens, and you’re using chaining, the extra item is stored in a linked list hanging off the array slot. How does the .NET Dictionary handle this?
Storing entries
To store its data, the Dictionary uses an array of Entry structs:
|
1 2 3 4 5 6 |
private struct Entry { public TKey key; public TValue value; public int hashCode; public int next; } |
key and value should be self-explanatory. hashCode provides a fast lookup to the original hash code for the functions that need it, and next is used when dealing with hash collisions.
So, the backing array is a Entry[] called entries. However, where the entries go in this array isn’t determined by the hash code. There’s actually a separate array of ints called buckets alongside entries. How is this used?
Hashing items
When adding an item, the hash code is generated modulo the current array size, and that determines the slot the item is stored in. However, that slot is not the one in entries, it is actually the one in buckets. The value in buckets at the hashed index is then the index of the slot in entries that the data is actually stored at, and that is simply assigned to the next free slot in the array.
As an example, say you’ve got a Dictionary with a capacity of 5:
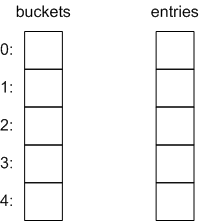
You add an item to it, that has a hash code of 3, modulo the size of the dictionary. The actual item goes in the first available slot in entries, and the slot at index 3 in buckets then stores the index at which the item is stored in entries; in this case, 0:
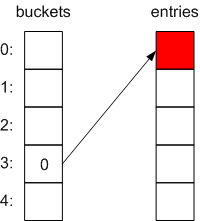
You then add two more items to it, with hash codes 0 and 2, respectively:
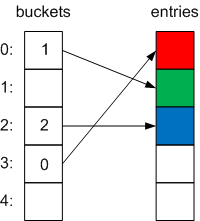
Nice and simple. But, you then add a fourth item that also hashes to 3. Now, we’ve already added an item with a hash code of 3; we’ve got a hash collision, so the Dictionary will have to chain it. However, it doesn’t create a separate linked list, it stores the index of the next item in the chain in the next value of the Entry struct like so:
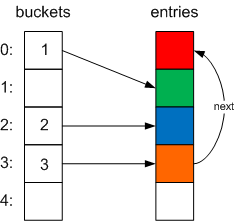
If we were to add another item, also with a hash code of 3, the chain would be extended:
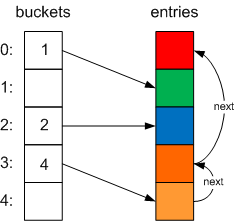
This means, that to search for an item with a particular hash code, you go to the Entry pointed to by the buckets value at that hash code, and follow the next pointers until you find the item you need, or the null pointer (signified by a next of -1; see the FindEntry method).
Removing items
So that’s adding items. What about removing items?
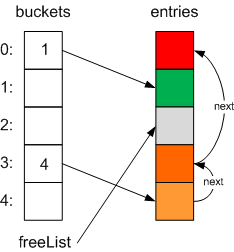
Any item in the dictionary can be removed at any time, which is different to adding items, where they simply get put on the end of the entries array. If you’ve got lots of additions and removals, this can lead to a lot of wasted space as items in the middle of the array get removed, and new items get added to the end. Well, this is where a variable called freeList comes into play.
When an item is removed, the slot it occupied gets added to the freelist chain. This is a chain of entries, indexed by a single freeList variable, which marks array slots where additional items can go. This is chain is also linked by the next pointer in the Entry structure.
So, this is what it would look like if you removed the blue item:
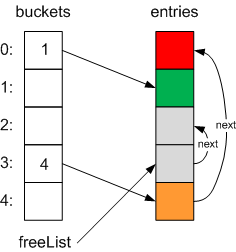
then the orange item:
Then, if another item is added, instead of adding to the end of the array (and causing a full rehash of the contents), it can simply use the slot pointed to by the freeList variable:
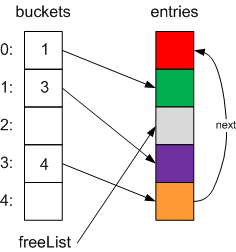
Using this indirect mechanism means that the internal arrays don’t need to be resized, and everything re-hashed, until you actually have more items than you can store in the entries array. It also doesn’t cause much performance degredation when the dictionary gets full, which the non-generic System.Collections.Hashtable had problems with.
Some more random observations…
Cleardoesn’t reset the size of the arrays; if you clear a dictionary with 100,000 items in it, the backing arrays will still be sized to store 100,000 items, potentially wasting a lot of space.-
The dictionary enumerator simply iterates down the
entriesarray. This is why, when you’re just adding items to a dictionary, they are returned in the order they were added. Only when you remove items and the freelist becomes involved are items returned in non-consecutive order.However, this is very much an implementation detail, and can change in future versions of .NET; do not rely on this behaviour in your own code! Always treat the the enumeration order of any hashtable as random.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments