

SQL Server provides security at every layer: encryption at rest (TDE), encryption in transit (TLS/SSL), encryption in use (Always Encrypted), access control (logins, roles, schemas), row-level filtering (RLS), column masking (Dynamic Data Masking), auditing (SQL Server Audit, C2 audit mode), and network protection (firewall rules, contained databases). Effective SQL Server security requires multiple overlapping layers – no single feature is sufficient on its own.
This essential SQL Server security guide introduces each feature – with when and why to use it – so architects and DBAs can build a defense-in-depth strategy appropriate for their environment. Plus, at the end, we’ll list the 12 essential SQL Server security actions you should take right now.
A brief introduction to the guide
SQL Server security structure, mechanisms and methods are very thoroughly documented in the Microsoft documentation, but it is quite daunting if you don’t already know about the functionality. I recently had a request to explain some security features of SQL Server so that internal audits could be completed. While thinking about the request and preparing for the meeting, I realized how many security features are available in SQL Server.
The purpose of this article is not to thoroughly explain how all of these items work, but to give an introduction to these features and a few recommendations. Given how many security-centered features are available, I’m sure I missed a few, and new features are added all the time, but these are the main features at the time of this writing.
I’ve tried to organize the features into logical groupings, but some certainly cross boundaries. And you could argue that some belong in different categories, but the descriptions and recommendations remain the same.
Since I don’t dig into how to configure these items, but when and why I would use them, the audience for this is less technical. But I also found this to be a useful reminder about some functionality, so architects and developers may also find utility in that aspect. Each of the topics below could have their own post or even series of post, so this just touches on each item with basic descriptions and use cases.
Before we begin: a quick note about SQL Server security
Security requires multiple layers to be effective, since there are so many possible ways for a system to be compromised. Physical server security, network security, including wireless, user training, application security, external vendor security and many other areas can impact the overall well-being of your SQL system. Work with your infrastructure and security teams to understand all areas as they impact your SQL system. It’s difficult to prepare for a risk if you aren’t aware of that potential risk.
With that said – let’s get into the guide. We’ll start with physical and network security.
Protect your data. Demonstrate compliance.
Physical/network security in SQL Server – how it works
One of the main questions that come up around SQL is how the data files are physically secured, how data is transferred over the wire and other protections outside of the data engine. This section covers those areas, which is primarily concerned with encryption at various levels.
Transparent data encryption (TDE)
Transparent data encryption (TDE), at rest database encryption, encrypts the database files when the data engine is not using the files. This would be when the service is manually stopped, the files are detached, or the database is set to auto close and it has been inactive.
TDE is very similar to encrypting your local drive. The engine has access to the decryption key and decrypts / encrypts automatically, but if you tried to read the data file with a hex editor you would only see the encrypted data. If you don’t have the encryption key you also can’t attach the database to a different server.
TDE in Azure SQL Database (cloud environment)
Starting in SQL Server 2017, TDE is on by default in Azure SQL Database. This is also an option for on-prem and managed instances, but you do have to go through the configuration process.
The attack window for accessing the raw data files is very narrow in an Azure environment. In general, the engine would need to be off and the attacker would need to have access to the file location in Azure. If someone has that level of access, they probably don’t need to grab the raw data files. But it is on by default and it makes everyone feel better about security in Azure. I tried to see if it can be turned off in the Azure dashboard without luck, but it may be accessible via deployment templates. There really is no good reason to disable TDE in Azure.
TDE in an on-premises environment
In an on-prem environment, you need to make sure certificates are configured and enable TDE manually. The attack window is bigger for on-prem environments, but you still need elevated access to grab the raw data files. If you have ever used sp_detach_db / sp_attach_db, you understand how these files could be used. Without the encryption key, you won’t be able to access the data in another instance of SQL Server, but that’s the point of using TDE. For sensitive data, it makes sense to enable TDE in on-prem servers.
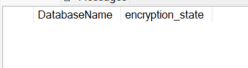
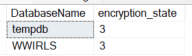
Status of TDE can be queried via sys.dm_database_encryption_keys. Refer to the documentation for a full list of encryption_state values, but a value of 3 indicates an encrypted database. If there are no values returned by the query, or a 0 is returned, no keys are created and databases are not encrypted.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* 0 = No database encryption key present, no encryption 1 = Unencrypted 2 = Encryption in progress 3 = Encrypted 4 = Key change in progress 5 = Decryption in progress 6 = Protection change in progress (The certificate or asymmetric key that is encrypting the database encryption key is being changed.) */ SELECT DB_NAME(DEK.database_id) DatabaseName ,encryption_state FROM sys.dm_database_encryption_keys DEK ORDER BY DEK.database_id |
Default on-prem state
Default Azure SQL Database state
Recommendation
Leave TDE enabled in Azure SQL and consider using TDE for on-prem servers, especially with sensitive data.
Transport layer security (TLS/SSL)
Transport layer security (TLS) is on-the-wire encryption. It is still commonly referred to as SSL encryption and this is how website data is secured during transmission and SQL data can be secured in the same way. TLS encrypts data as it travels over the network, whether that is your internal network or it is going to a client outside your network on the internet or a partner site. TLS uses public key encryption and requires a certificate be installed on the server and a secure line of intermediate certificates verifying that the certificate is trusted.
As with TDE, TLS is on by default with Azure SQL databases and must be configured for other instances. I have mixed feelings about the on-prem configuration of TLS. It increases the administrative overhead and requires certificates to be managed on a regular basis. It may be worth it depending on your security requirements, but it isn’t a point and click operation. And I have seen multiple instances where certificates have to be installed by typing in the certificate hash (fingerprint) manually in the registry.
Things have improved greatly with the Azure database implementation and it is fairly seamless. If you decide to use TLS for on-prem instances, usage can be optional, forced for all connections, or forced for a subset of connections.
Encryption status can be validated with the DMV sys.dm_exec_connections. The following shows my local server with a default configuration and the second shows a default Azure database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT SP.spid ,SP.program_name ,SP.cpu ,SP.physical_io ,SP.open_tran ,SP.net_library ,DC.net_transport ,DC.auth_scheme ,DC.encrypt_option FROM sys.sysprocesses SP INNER JOIN sys.dm_exec_connections DC ON SP.spid = DC.session_id |
ORDER BY SP.spid
On-prem default

Azure database default

Note: Even if TLS is not enabled for a server, all login packets are encrypted. Data packets are only encrypted if TLS is enabled and enforced or used by the client.
Recommendation/key takeaway (what action you should take)
TLS is configured by default in Azure SQL and it makes sense considering that you can access the database over the internet, depending on your Azure environment. Consider using TLS for on-prem servers, especially with sensitive data. It may not be worth the effort on-prem if the data is not especially sensitive or if network connections are already encrypted using a different technology such as IPsec.
Backup file encryption
Backup file encryption is easy to understand, easy to implement, and recommended. Since backup files can be moved, and in fact should be moved if on-prem (for disaster recovery scenarios), they are a viable attack target. This is done by default in Azure and is an option for on-prem backups.
Recommendation/key takeaway (what action you should take)
Encrypt your backups. Very small downside with greatly enhanced security.
Network security groups (NSG)
Network security groups (NSG) are used to isolate and secure assets within an Azure environment and between Azure environments and on-prem environments. I have seen them used to ensure only specific services are able to access specific servers on-prem, but they are very flexible. They are analogous to firewall or router rules in a traditional network environment and can be used to limit traffic to and from SQL databases or servers.
This functionality isn’t specific to SQL but it is part of the Azure ecosphere. Microsoft recommends using a Zero Trust approach. This makes it harder for an attacker that gains access to a single resource to expand their access.
Recommendation/key takeaway (what action you should take)
NSGs are very powerful and offer great flexibility in configuration. Subnets and virtual networks can be used to segment traffic with NSGs helping to secure these groupings. Work with your cloud engineering team and security team to align security expectations and protect your Azure SQL environment.
Firewall policy in Azure SQL
Azure SQL includes a firewall policy that limits the IP address(es) that can access the database by default. This can be configured automatically using Azure templates and can also be updated manually using the GUI and the system stored procedure, sp_set_database_firewall_rule (at a database level) and sp_set_firewall_rule (at a server level). Use the system view sys.database_firewall_rules (at a database level) and sys.firewall_rules (at a server level) to review the existing policies on a database.
Firewall rules can also be reviewed and set in the Azure dashboard or with PowerShell. This isn’t a foolproof method to stop outside attacks, but it is highly recommended and a good starting point for security.
Firewall rules in the enterprise
Outside of the SQL ecosphere, firewall rules and security appliances can be used to limit traffic to SQL servers and databases. Network border security is standard and highly sensitive data can be placed into more secure subnets (DMZs). Work with your DBAs and security teams on the right solution for your environment, but be sure your SQL environment is not accessible to all IPs on the internet.
Recommendation/key takeaway (what action you should take)
NSGs, firewall policies, and firewall rules and appliances should all be used to protect SQL environments. Work with your network and security teams to determine the enterprise standard and follow that. This helps ensure something isn’t missed and also helps troubleshooting if everything is done using the same methodology.
Also, severely limit the clients allowed to access Azure SQL environments. This will typically be clients in your Azure infrastructure and on-prem clients in your control. It also should be mentioned to limit physical access to local servers and network equipment. Everything should be behind locked doors with very limited access.
Authentication options
Authentication is the process of proving that the user trying to access a resource is in fact, the user they claim to be. They are authentic and verified. I have seen some documentation recently that conflates authentication and authorization. This is tempting in a world with contained user accounts that essentially act as the authentication and the authorization mechanism. I think the concepts are useful separately and will treat them as such here. They work together, but they are separate items.
Logins
Several methods for authenticating to a SQL server or database are available. They are all generally referred to as logins. The basic types of logins follow.
SQL Logins
SQL logins are contained entirely in the SQL server or database, in the case of Azure or a contained database. Names and passwords are stored by SQL, but enterprise standards can be enforced for both password complexity and frequency of password updates.
This is the standard SQL username and password. It is very easy to setup and easy to maintain for small environments. It becomes more difficult to maintain as the environment grows and the number of users increase. It is not the best method for authentication but it is simple and works well within its’ bounds.
Reminder: SQL logins are specific to the container they are created in. That means, if you have a SQL login on your production server and another SQL login on your dev server with the same name, they are not the same login. They have a different SID in the system tables, passwords are not synchronized automatically, and they only are similar in the actual name. Any synchronization of passwords or security is managed manually by the teams.
Integrated authentication
Integrated authentication is the process of using the local Windows or the Active Directory (AD) logins for authentication to SQL. This requires maintenance of these accounts at an enterprise level, but it is much more secure for several reasons. The first is that you will usually assign security at a group level rather than individual user level. Changes are managed via standard enterprise approvals and security in SQL is modified much less using this method (after initial setup). The second reason is that password complexity and changes are managed via standard methods in the enterprise. The third reason is that if an account is locked out or disabled in AD, it applies to everything, including SQL. Lastly, unlike SQL logins, integrated authentication means that an AD user on one server is identical to an AD user on another server. There are no passwords to synchronize between servers. In fact, you can’t manage the passwords at a SQL level, it is all done in AD.
Azure options
Azure SQL offers some new methods for authentication. Azure Active Directory – Universal with MFA, Azure Active Directory – Password, and Azure Active Directory – Integrated. Which method you use will depend on enterprise decisions, but they are all more secure than SQL logins for the same reasons mentioned in the Integrated Authentication section.
Note: Microsoft has recently changed the name of Azure Active Directory to Microsoft Entra ID. This is starting to get reflected in the documentation but it has not changed in SSMS yet.
Managed identities
Managed identities are a newer method for authenticating in an Azure environment. It connects a resource group to a SQL instance. From the perspective of SQL, it looks like a regular user and security is assigned in the same manner.
This is the method of choice for connecting to SQL from an Azure resource group. This connection would have previously been done with a service account of some type, but managed identities involve even less setup than an AD or Azure AD (AAD) account and require less overall management and no password management.
Server logins of all types can be queried with the following.
|
1 2 |
SELECT * FROM sys.server_principals |
Users
A user is the authentication method within a database. It previously had to be connected to a server login. With Azure, the line between logins and users has blurred. It is possible to create a contained user that serves as the previous login and is effectively a combination of the login and user. Current documentation lists 13 types of users. At a database level, this is how security is assigned and can even be the authentication level.
Recommendation/key takeaway (what action you should take)
Integrated authentication, Azure authentication, and managed identities (for service access) are considered best practices. Use these methods, when possible, rather than SQL logins. Contained users are recommended for portability and using AD or AAD facilitates administration.
Setup reminder: During the setup process, SQL Server now forces security by default. It is always possible to make bad decisions, use bad passwords, change the configuration later or do other things generally considered poor security design. The defaults are secure by design, but be sure you understand the security implications of your setup options, especially authentication choices.
Users can be viewed with the following:
|
1 2 |
SELECT * FROM sys.database_principals |
Authorization options
Authorization is the process of checking that a user has access to specific resources in SQL. Typical users won’t have server level permissions, but they are available to administrators and it is useful to know how they work. Most authorization happens in the database and usually objects are secured at an even lower level such as at a schema level.
Built-in server roles
Server roles in SQL Server are equivalent to security groups in active directory with pre-defined security assigned to them. Normal users won’t be assigned server roles, it is typically reserved for administrators of some type. Server roles, as the name implies, are also only available on server systems, not on SQL database. I wouldn’t expect server roles to be part of a regular security architecture other than for administrators.
Server-level permissions
Permissions can also be assigned directly at the server level to users in server systems. There is a case for this outside of administrators when you have power users / developers that are able to perform some troubleshooting and understand the care needed on a production system.
These users are typically architects or leads on an application team. I will typically ask for server state, create trace, view any definition, and showplan permissions when I am on a team so I can run DMVs, examine queries and troubleshoot using trace.
Built-in database roles
Database roles are similar to server roles, but are specific to each database. Granting db_datareader in one database does not grant that role in any other database. The typical database roles granted in a database are db_datareader and db_datawriter. As their name implies, they allow a user to respectively SELECT, and INSERT / UPDATE / DELETE from any object in the database.
The built-in roles fit small teams and projects but generally don’t adhere to the rule of least privilege in larger projects. Granting access to all objects in a database is excessive and may be a security gap, especially in warehouse projects. Consider your usage patterns before you rely too heavily on these roles.
User-defined roles
User defined roles are like built-in roles, but they have no assigned security when they are created. This allows them to be tied to any schema or set of objects as needed to fit the project and any security can be tied to these roles. This fits well for a more complicated project and projects with more users.
A pattern I typically follow is to create a schema for different groups of tables and assign access to these schemas via user defined roles. In addition to limiting security, it also makes it easier to track down security.
Database-level permissions
SQL also allows permissions to be assigned at a database level. This is similar to the server level permissions described above. They typically are also permissions that would be reserved for an administrator or power user. These are permissions beyond typical DDL (data definition language) and DML (data manipulation language).
These include things like ALTER ANY ROLE, ALTER ANY DATABASE SCOPED CONFIGURATION, ALTER ANY MASK, and many others. Refer to the SQL Server documentation for a full list.
Directly assigned permissions
I have described using roles to assign permissions to users. Permissions can also be assigned directly to users. I highly discourage this pattern as it makes consistency difficult and discourages the use of roles and group-based permissions.
I also discourage assigning permissions directly to security groups and prefer to assign them to roles, then assign groups to those roles. This keeps the pattern consistent and allows the same permission sets to be used for any authentication method.
Schema-based security
Security can also be assigned at a schema level rather than at a database or object level. This means that any new objects created in the schema have the same security assignments. It’s a great pattern when combined with user role security.
Row-level security (RLS)
Row level security (RLS) was described extensively in my blog series. It is a good supplement to standard security and another possible layer when it meets business requirements. RLS returns different results for queries based on the user accessing the data. This can be a powerful combination, especially with a reporting solution. Remember that RLS is an additional layer of security and does not replace standard security mechanisms.
RLS access predicates and security policies can be reviewed with the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
SET NOCOUNT ON ; WITH ACCESS_PREDICATES AS ( SELECT DISTINCT SP.object_id ,SP.target_object_id ,SS.value AccessPredicateName FROM sys.security_predicates SP CROSS APPLY string_split(SP.predicate_definition,N'(') SS WHERE SS.value <> '' AND SS.value NOT LIKE '%))' ) SELECT SS.name SchemaName ,SO.name TableName ,SSSP.name SecurityPolicySchema ,SSP.name SecurityPolicyName ,SSP.type_desc SecurityPolicyDescription ,SSP.is_enabled SecurityPolicyIsEnabled ,AP.AccessPredicateName ,SP.predicate_definition AccessPredicateDefinition ,SP.operation_desc ,SP.predicate_type_desc FROM sys.schemas SS INNER JOIN sys.objects SO ON SS.schema_id = SO.schema_id INNER JOIN sys.security_predicates SP ON SO.object_id = SP.target_object_id INNER JOIN sys.security_policies SSP ON SP.object_id = SSP.object_id INNER JOIN sys.schemas SSSP ON SSP.schema_id = SSSP.schema_id LEFT JOIN ACCESS_PREDICATES AP ON SP.object_id = AP.object_id AND SP.target_object_id = AP.target_object_id ORDER BY SS.name ,SO.name ,SSP.name GO |
Recommendation/key takeaway (what action you should take)
Authentication can become very complicated and difficult to track down, especially if consistent methods aren’t used when designing security. Define a standard for your organization and use it. When you need to deviate, make sure the developers understand the need and can justify the change to standards.
Deviations should also only happen when supporting business functionality. Built-in user roles are often sufficient for transactional applications and service accounts, but they are applied very broadly, at a database level. User-defined roles allow finer grained, and consistent controls and are more useful for warehouses and even transactional databases.
Remember the rule of least privilege and only grant the necessary level of security. The db_owner role should be extremely restricted and never allowed for application or service accounts. The server role sysadmin should be even more restricted.
Additional data security structures
Dynamic data masking
Dynamic data masking is a method to hide or obfuscate sensitive data for groups of users while allowing other users to see that sensitive data. There are many options for hiding the data, including options for what the mask looks like and how many characters in a field to mask.
Refer to my series on dynamic data masking for additional details, but this is another addition to standard security. It does not limit the rows returned or how the data can be used. It just limits what certain columns look like to end users.
Masked column details can be reviewed via the system objects, in addition to the Azure dashboard and SSMS:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
SELECT SS.name SchemaName ,SO.name TableName ,SC.name ColumnName ,SC.is_masked ColumnIsMasked ,ST.name ColumnDataType ,CASE WHEN st.max_length = -1 THEN 0 WHEN st.name IN ('nchar','nvarchar') THEN SC.max_length / 2 WHEN st2.name IN ('nchar','nvarchar') THEN SC.max_length / 2 ELSE SC.max_length END MaxLength ,st.precision ,st.scale ,M.masking_function FROM sys.objects SO INNER JOIN sys.columns SC ON so.object_id = sc.object_id INNER JOIN sys.schemas SS ON so.schema_id = ss.schema_id INNER JOIN sys.types ST ON SC.system_type_id = ST.system_type_id AND SC.user_type_id = ST.user_type_id LEFT JOIN sys.types st2 ON st.system_type_id = st2.system_type_id AND st2.system_type_id = st2.user_type_id AND st.is_user_defined = 1 LEFT JOIN sys.masked_columns M ON SC.object_id = M.object_id AND SC.column_id = M.column_id WHERE SC.is_masked = 1 ORDER BY SS.name ,SO.name ,SC.name GO |
Recommendations/key takeaways (actions you should take)
Consider dynamic data masking when it fits your business scenario. It can add complexity and has some vulnerabilities so take these into account. Refer to my series on dynamic data masking for specifics.
Protect sensitive data with Redgate Test Data Manager
Cross-database queries
In on-prem and managed instances, a user can access other databases by using the syntax of database.schema.object. They must also have authorization to these objects and have an account in those databases, but it is worth knowing that the functionality is available.
Recommendations/key takeaways (actions you should take)
Cross database queries can be very tempting since they allow data to be accessed from any database on a server. They are not supported in Azure databases, so if you are planning the move to Azure, I would avoid them. Similar functionality exists in Azure, Elastic Queries, but they are configured differently.
Ownership chaining in views / stored procedures / objects
Ownership chaining can be used in views and stored procedures to allow a user to access data they wouldn’t normally be able to access. If they have EXEC permissions on a stored procedure, and the owner of the objects in the stored procedure are the same as the stored procedure, the execution will be allowed and data returned. They don’t need permission on the object referenced by the stored procedure. The key is that the owner is the same. This isn’t something you need to configure, but it is something you can take advantage of in your design.
EXECUTE AS
The command EXECUTE AS allows a user to run statements and commands under the context of a different user, in other words it is impersonation. When running as that user, they have the permissions of the user specified. Standard users are not able to use the EXECUTE AS command by default and must be granted permission for it. The user must have IMPERSONATE permissions for the user specified in the EXECUTE AS statement.
Recommendations/key takeaways (actions you should take)
When using impersonation, be sure to specify or create a user with the minimum viable security. This is consistent with the other security mechanisms and patterns discussed. Impersonation can also be combined with stored procedures and views to temporarily allow additional permissions that the user wouldn’t normally have, making the system more secure overall. Users created without a login can be impersonated allowing for very precise control and can be useful for test scenarios.
Views as a layer
Views can be used as a security layer by limiting the data returned to users. They can limit both the columns returned and the rows. Data can also be obfuscated at this level by replacing sensitive values. This has been a common practice in database systems for a long time. Putting views into different schemas allows security to be assigned easily and automatically after initial setup.
Recommendations/key takeaways (actions you should take)
Views are an effective part of a security plan. Views can be used to limit the data returned, as a layer to simplify and decouple tables from queries, and as a method for assigning security. Use caution nesting views as it can get complicated to troubleshoot and can inhibit performance tuning due to that complexity.
Linked servers
Linked servers provide a method to run queries between one or more servers. The query is initiated on the first server and it executes on the remote server under the defined security context. Performance considerations aside, they need to be configured carefully to ensure security. Multiple methods are available to configure security but generally executing as the current user will be most predictable and secure. Note that this functionality is only available on server instances of SQL.
Linked servers can be viewed in SSMS in the “Server Objects”
Recommendations/key takeaways (actions you should take)
Linked servers are not supported in Azure SQL databases. Like cross database queries, this functionality can be simulated with Elastic Queries. Linked servers and Elastic Queries are easy to misconfigure, so use caution when implementing these solutions and be sure they are the best fit. Other virtualization technologies such as PolyBase may be more secure and perform better.
Additional data encryption
There are multiple ways to encrypt and protect data when using SQL. Built-in methods are recommended over custom-coded solutions due to the amount of testing, rigor and patching available. Several options are available in SQL to encrypt data at different levels.
Always Encrypted
Always Encrypted is a method to encrypt specific columns in the database without exposing the encryption keys to the database engine. This makes it extremely secure and suitable for the most sensitive data.
It is also possible to perform comparisons and lookups on these columns if it is configured with deterministic encryption. Deterministic encryption has specific requirements and requires additional configuration.
A secure enclave can be used to enhance Always Encrypted implementations by improving comparison operations available but this option has more environment and configuration requirements. The secure enclave sets aside memory space where operations are secure but performed with the data in an unencrypted state.
Recommendations/key takeaways (actions you should take)
Always Encrypted is a great option for extremely sensitive data and creates a true separation between the administrators and the owners of the data. It requires some configuration but is recommended for highly privileged data when even administrators shouldn’t be able to see the data. Be sure you understand the limitations and possible performance hit if you don’t use deterministic encryption.
Column level encryption
Column level encryption (symmetric key encryption) can be achieved using database keys and a certificate created in the database. It is a secure option and easy to configure but the certificate and key can be controlled by SQL administrators. This data is encrypted at rest and only decrypted when requested by authorized users.
Recommendations/key takeaways (actions you should take)
Column level encryption is easy to implement and protects data at rest and in backups, but it is vulnerable to internal bad actors. If the data absolutely can’t be exposed to administrators, consider Always Encrypted instead.
Custom encryption
Outside the scope of SQL, any encryption managed by a security appliance or an application can be saved inside SQL. This will generally be stored in binary columns and offers benefits if you already have the encryption infrastructure in place. Key management is always an issue with encryption. If that problem is already solved at an enterprise level it may make sense to use your existing processes rather than configuring encryption at a SQL level.
Monitoring options
Part of every security plan should include monitoring. There are several methods to check for security issues with your SQL environment. Some of the methods below are more automated than others but each has a potential use case.
SQL Trace / Profiler
SQL trace, or the GUI wrapper, Profiler, has been part of the SQL ecosphere for the longest compared to the other monitoring options listed in this section. It allows administrators and others with trace permissions to view all queries coming into SQL or a subset based on filters. This tool has traditionally been very useful for troubleshooting specific issues as they happen. It can also be used to capture SQL query information over time for later analysis.
Recommendations/key takeaways (actions you should take)
Trace / profiler is extremely easy to use but will be deprecated in future versions. Start getting familiar with alternatives such as extended events and audits. This has been one of the hardest transitions for me due to the ease of use and utility of SQL trace, but luckily new methods are available that provide nearly the same functionality.
Extended Events
Extended events were introduced with SQL Server 2005 and have similar functionality to trace. They continue to be available in Azure SQL. Security functions have been moved to audits, but they can be used to capture server activity.
Extended events running in a server environment can be seen with the following.
|
1 2 |
SELECT * FROM sys.dm_xe_sessions |
Azure database event sessions can be seen with a different system view.
|
1 2 |
SELECT * FROM sys.database_event_sessions |
Recommendations/key takeaways (actions you should take)
Extended events are the new utility of choice to capture submitted queries and performance related items in near-real time. As mentioned in trace, start getting familiar with extended events if you haven’t already.
Read also: Extended Events for security monitoring
Server and Database Audits
Server and database audits, or just database audits on Azure SQL, allow you to set up rules to capture specific events, including many that are also covered in extended events and trace. Results can be stored in several different types of targets, including binary files, and event logs. Events to be audited must be specified but a base set of audit events are a standard part of the configuration.
Recommendations/key takeaways (actions you should take)
Audits are lightweight, capture events, and can be used to meet regulatory requirements. They fit well in highly regulated environments.
You may also be interested in:
Auditing SQL Server environments
SQL Server data dictionary for documentation
SQL Advanced Threat Protection
Advanced Threat Protection covers all instances of SQL in Azure, including Azure on VMs and managed instances. It alerts users to suspicious database activities and can provide alerts for administrators. This feature requires additional configuration and incurs additional fees. It requires a Log Analytics Workspace for storage as well as the service, so review pricing.
Recommendations/key takeaways (actions you should take)
Threat protection can provide warnings about potential SQL injection attacks, including the query sent to the data engine. It is very easy to configure and should improve over time as Microsoft is able to find new attack patterns, so it is worth considering.
DDL Triggers
Data definition language (DDL) triggers can be created at a database level to track changes to objects, including the user that made the change. If you are using other monitoring tools this may be redundant, but it is reliable and available.
The following will show database DDL triggers.
|
1 2 3 4 5 6 |
SELECT TR.name ,TR.is_disabled FROM sys.triggers TR WHERE parent_class_desc = 'DATABASE' ORDER BY TR.name |
C2 Audit Mode / Common Criteria Compliance
C2 audit mode imposes a set of auditing standards and security behaviour on SQL server systems. It is available on server systems and records trace information for many events and Microsoft documentation warns that it stores a large amount of information.
Common criteria compliance is based on EU security standards and covers three items. First is that memory must be overwritten with a known pattern before it is reallocated. Second is the ability to view login statistics. The third is that a GRANT statement never supersedes a DENY statement. Without this, GRANT at a column level will override DENY at a table level.
Recommendations/key takeaways (actions you should take)
If you are using c2 audit mode, consider moving to common criteria compliance as c2 audits will be deprecated in a future version.
DMVs
Many data management views (DMVs) are available to monitor your environment and most are available in all versions of SQL. They allow you to get a quick view into the workings of the system and also can provide recommendations for performance tuning, show blocking processes, configuration items and most of the inner workings of the system.
Recommendations/key takeaways (actions you should take)
Even if you use an external monitoring tool it is worth your time to learn some basic DMVs. They are a lightweight method to view system status at a glance. I find them to be more convenient than the Azure GUI, especially if you need to manage multiple servers.
Monitoring data changes
SQL offers multiple methods to monitor and determine who made changes to data, what was changed and when. In most systems it isn’t necessary to capture data changes, but it has become much easier in recent versions.
System-versioned temporal tables (history tables)
System-versioned temporal tables (temporal tables / history tables), automatically capture all data changes to a table. When a base table is configured as a temporal table, another table is linked to capture all changes. This includes all INSERT, UPDATE, and DELETE operations. Queries against the base table won’t include history information by default, but special syntax will return the modified rows. This can be used to capture who made the changes if that information is included in the data modification statements.
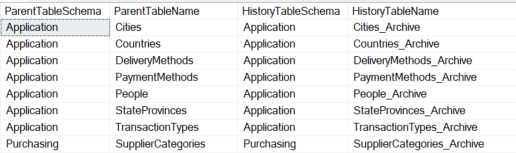
Temporal tables and their associated history tables can be viewed using system views. The following example uses the WideWorldImporters sample database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT SS.name ParentTableSchema ,ST.name ParentTableName ,SSA.name HistoryTableSchema ,STA.name HistoryTableName FROM sys.schemas SS INNER JOIN sys.tables ST ON SS.schema_id = ST.schema_id INNER JOIN sys.tables STA ON ST.history_table_id = STA.object_id INNER JOIN sys.schemas SSA ON STA.schema_id = SSA.schema_id ORDER BY SS.name ,ST.name |
Change data capture
Change data capture (CDC) is similar to temporal tables, but it doesn’t store data in a directly accessible table. Data is made available through table-valued functions. They also use SQL Agent jobs, or a scheduler in Azure, to capture and maintain changes. CDC is easier to initially implement since it requires no changes to the base table, but it does have more long-term management costs.
CDC status can be verified with the following:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT SS.name CDCSchemaName ,ST.name CDCTableName FROM sys.schemas SS INNER JOIN sys.tables ST ON SS.schema_id = ST.schema_id WHERE is_tracked_by_cdc = 1 ORDER BY SS.name ,ST.name |
Triggers
Triggers can be created to capture data modification operations to tables. This was a common method before temporal tables and CDC was available. The exact storage method and columns captured is entirely dependent on your implementation.
The following provides a comma separated list of triggers on each table in a database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
; WITH TRIGGERS_CTE AS ( SELECT SS.name SchemaName ,SO.name ObjectName ,SO.type_desc ParentObjectType ,STUFF( (SELECT ',' + SOTI.name FROM sys.objects SOTI WHERE SOTI.parent_object_id = SO.object_id AND SOTI.type = 'TR' FOR XML PATH('')),1,1,'') TriggersOnObject FROM sys.schemas SS INNER JOIN sys.objects SO ON SS.schema_id = SO.schema_id ) SELECT SchemaName ,ObjectName ,ParentObjectType ,TriggersOnObject FROM TRIGGERS_CTE WHERE TriggersOnObject IS NOT NULL |
Recommendations/key takeaways (actions you should take)
Triggers are not the preferred option for monitoring data changes due to the programming requirements. When system features are available for something, it usually makes sense to use that functionality instead of coding your own version. Temporal tables are easy to implement and query but do require table changes. CDC is easier to implement but has a much higher maintenance cost. I generally prefer using temporal tables since changes are managed via automated deployments and they are easy to query and report against. CDC may fit your need better but consider both options if you need to monitor data changes.
Future-proof database monitoring with Redgate Monitor
Recommendation summary
SQL configuration and options generally guide you to good security decisions during setup operations. Make sure you understand any options that you change from the default. Each version of SQL is more secure than the previous version, from the database engine implementation to default features. This is a direct product of the 2002 Trustworthy Computing initiative by Microsoft. It put a strong focus on security at all levels of design and that focus continues. But having a secure product is the framework for your architectural decisions and design patterns. It is up to you and your team to make good decisions and follow best practices.
When it comes to security, consistency is critical. There are many ways to design security within SQL, but consistency is extremely important. This makes administration predictable and improves the chances that new security requirements are applied consistently. This applies to all aspects of the SQL ecosystem, from physical security, to database security, and application security.
Another key objective of configuring user security in SQL is using minimum viable security. This should sound familiar and be the core tenant of all security decisions. Some things are automatically secure with SQL, but user configuration and security rely on a foundation of good enterprise architecture and sound decisions when structuring security in SQL. It can be tempting to use a broad database role for security, but be sure that is the best fit. It is very easy to create a custom role that limits access. This will make your life easier in the long run.
12 essential SQL Security recommendations: a checklist
- In Azure, TDE is the default. Consider implementing it on-prem for sensitive data.
- Encrypt your backups.
This is the default behaviour in Azure and optional for on-prem SQL. - Be sure your connection is secure.
This is another default in Azure, TLS is on for databases. In a secure building with no potential for leaks, you may not need to use TLS, but be sure you understand the risks. - SQL should be behind a firewall of some type and not exposed directly to an open internet connection.
- Use a consistent authentication and authorization pattern.
Utilize your existing security structures and use Active Directory when possible. Try to use groups and user roles rather than applying security directly to users. - Don’t allow users to hit transactional systems directly.
They should go through some kind of an additional security layer such as an application using APIs. - Consider additional security structures if they fit the business need.
This can include dynamic data masking, row level security, additional encryption, views and stored procedures as a security layer, and data change monitoring. - Employ a method to monitor security and system activity.
Third party tools are available and there are many mechanisms included in the SQL ecosphere. - Stay on top of patches for your systems.
Microsoft and third parties provide alerts for vulnerabilities and patches. - Work with your security team to understand outside risks.
Discuss and understand physical security, user training, data extracts, application interfaces, external vendors and anything else accessing your system. You likely don’t own the data on the system but it is your responsibility to be sure it is secure. - Keep your system updated.
This includes both patches and engine versions for SQL Server. This is easier in Azure database since you are always on the latest version. - If you really want to protect your data / intellectual property (IP), limit the number of exports allowed.
This can be difficult in a culture of self-service data reporting, but extracts are challenging to control once they are created.
References
Physical / Network Security References
Authentication References
Authorization References
Additional Data Security References
Additional Data Encryption References
Monitoring References
Monitoring Data Change References
Other References
Protect your data. Demonstrate compliance.
FAQs: Security in SQL Server
1. What security features does SQL Server offer?
SQL Server provides: Transparent Data Encryption (TDE) for encrypting data files at rest, Always Encrypted for column-level encryption that protects data even from DBAs, Dynamic Data Masking for hiding sensitive column values, Row-Level Security for row-level access control, SQL Server Audit for compliance logging, Windows/Azure AD authentication, certificate-based authentication, firewall rules, and contained databases for portable security.
2. How do you secure a SQL Server database?
Follow defense-in-depth: enable TDE for data at rest, enforce TLS for connections, use Windows Authentication over SQL Authentication, implement least-privilege roles (avoid using sa), enable SQL Server Audit for compliance, apply Dynamic Data Masking on sensitive columns, consider RLS for multi-tenant access, keep SQL Server patched, restrict network access with firewall rules, and regularly review login and permission inventories.
3. What is the difference between TDE and Always Encrypted?
TDE encrypts the entire database file at rest – data is decrypted automatically when SQL Server reads it, so anyone with database access sees plaintext. Always Encrypted encrypts individual columns and keeps the encryption keys outside SQL Server (in the application tier), so even DBAs cannot read the plaintext data. Use TDE for at-rest protection; use Always Encrypted when the data must be protected from privileged database users.
4. Is SQL Server secure enough for HIPAA / PCI / SOX compliance?
SQL Server provides the technical controls needed for major compliance frameworks, but compliance depends on proper configuration and organizational practices. Enable TDE, configure auditing, implement least-privilege access, encrypt connections, and maintain patch currency. Document your configuration and test your controls regularly. Consult your compliance officer for specific framework requirements.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments