
In Power BI, when importing data with Power Query, one basic performance concept is the use of native queries. The transformations will perform better if they can be converted to a native query, especially a single native query for all transformations.
However, this is just a starting point for the optimizations. Sometimes, native queries for the transformations are not enough.
Test Environment
This will be the starting point:
- An Azure SQL Database using the sample AdventureWorskLT
- You need to execute the script Make_big_adventure.SQL adapted for the AdventureWorksLT. You can find it on https://github.com/DennesTorres/BigAdventureAndQSHints/blob/main/make_big_adventureLT.sql
- Recommendation: The Azure SQL Database is recommended to have 10 DTU’s or more. Less than that and some slowness may be noticed
- In Power BI we will import the tables BigProduct, BigTransactionHistory and SalesLT.ProductModel

Transformations and a Date Dimension
A model needs a date dimension. Every fact happens on a date and the date is an important dimension to analyse the fact. In this example, the TransactionDate column is found in the TransactionHistory table.
Why is the TransactionDate field is not enough, you may ask.
When analysing the facts, it might be analysed by Year, Month, Day, Day of the week, and much more. If relying only on the TransactionDate field, you will need to create DAX measures, and this would impact the performance of your model.
Building a date dimension, you will not have the need to build so many DAX expressions and the model will have better performance.
We can build a dynamic date dimension, retrieving the minimum and maximum date from the TransactionHistory table for that. That’s where our problems start.
The Wrong way
1) On TransactionHistory table, select the column TransactionDate
2) Change the Data Type of the column to Date
If you need to handle time in your model, date and time needs to be two different dimensions and two different fields in the fact table. A time dimension will have only 24 rows if built with hour granularity, 1440 if built with minute granularity and so on. On the other hand, if Date and Time were managed as a single dimension, we would have 1440 rows for each day, or something similar. That’s why date and time needs to be different dimensions.
In our example, we don’t really have time information. We will just ignore the time by changing the data type to date.
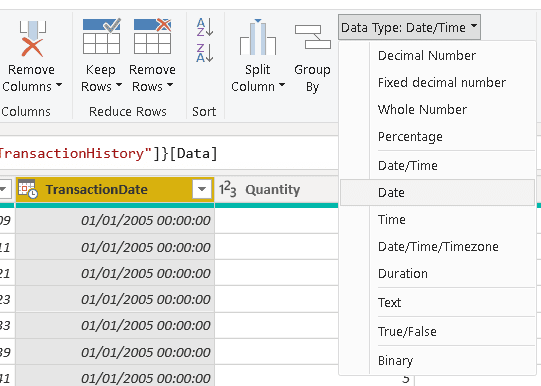
3) Righ-click the TransactionHistory table
4) Select the Reference menu item
We can duplicate the TransactionHistory query or make a reference to it. Let’s start with a reference and understand the consequences later.
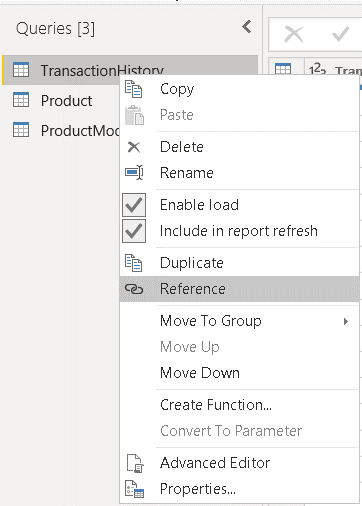
5) On the new query, select the TransactionDate column
6) Click the Remove Other Columns menu item
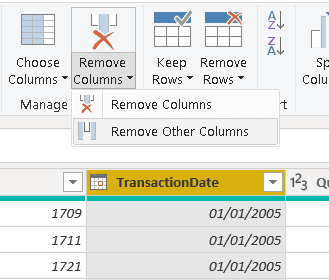
7) Click the button on the right side of the TransactionDate column header
8) Click the Sort Ascending menu item
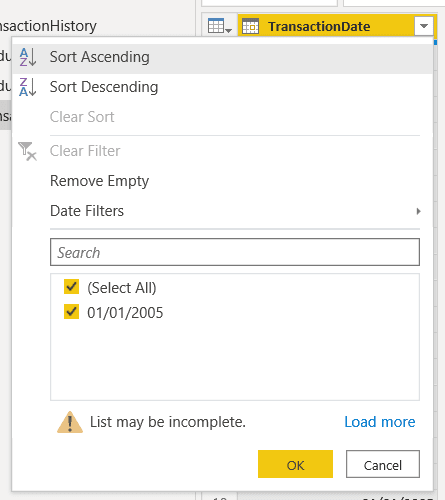
9) Click the menu option Keep Top Rows
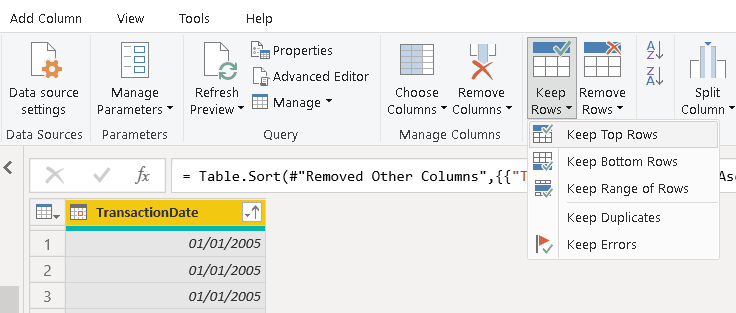
10) On the Keep Top Rows window, type “1” to keep only 1 row

11) Right click the value of the row and click the menu item Drill down
Even with a single row and field, the result of the query is still a table. We need to transform it to a single value to use it as a parameter for the function we will build next.
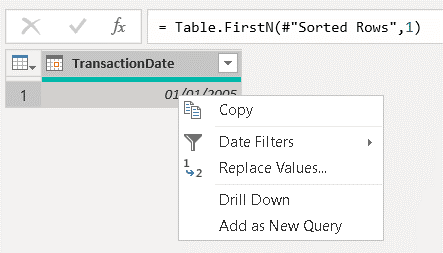
12) Right-click the “TransactionHistory (2)” table and disable the option Enable Load
We don’t need this value to be part of the model. But if we leave the load enabled, a new step will be created in the end of the query to transform it into a table, and it will end up failing.
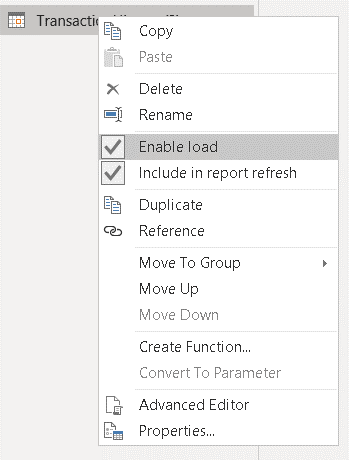
13) Rename the “TransactionHistory (2)” table to MinDate
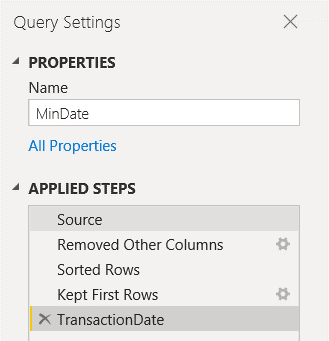
14) Repeat the steps 4-12, but now sorting in descending order
15) Rename the new table to MaxDate
Power Query: The Problem
If you right click the Keep Top Rows step of the MinDate query, you may notice the View Native Query is active. This option is only disabled on the Drill Down to the TransactionDate field.
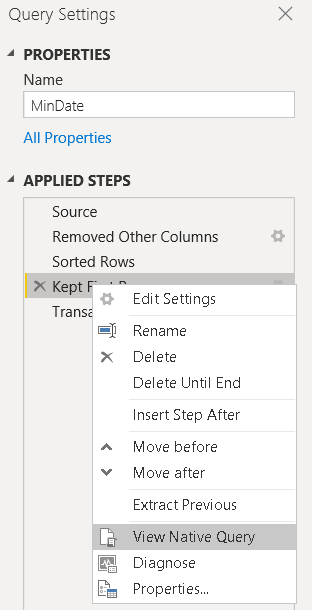
All the most expensive steps were transformed into a native query. A superficial view would make us believe the transformations are as optimized as possible, but that’s not true at all.
The query below is the native query built by Power BI.

Let’s analyse the execution plan. We can copy the query from Power BI to SSMS and check the estimated execution plan. As you may notice, this execution plan is terrible:

- It’s using a table scan, there is no index for this execution plan
- There is a Sort operation. Sort operations in execution plans are very heavy and should be avoided at all costs.
The first idea would be to create an index based on the TransactionDate, the column used in the transformations. The Create Index statement would be like this one:
ON [dbo].[bigTransactionHistory] ( [transactiondate] ASC )
go
After creating the index, this will be the new query plan:

The table scan was replaced by an Index Scan, but the Sort operation is still present, and you may notice it takes 95% of the query cost.
You may ask why the Sort was not solved by the index itself. If you check the query, you may notice the inner queries use a Convert function over the TransactionDate field to transform it to the Date type.
The Order By is executed over the result of the Convert, so it can’t use the index. The Convert function needs to be executed first and the result needs to be ordered.
In Summary: The order of the transformations is affecting the query performance. If the data type were one of the last transformations, the query plan could be better. But before reaching the solution, we will need to solve another problem.
Reference vs Duplicate
The data type transformation is located on the TransactionHistory table. The queries to calculate the MaxDate and MinDate have reference to the TransactionHistory query, so they all contain the data type conversion.
We could think about removing the data type conversion from the TransactionHistory query, but this would not work very well.
On the result, the TransactionHistory table will need to be linked with the date dimension. Both date fields will need to have the same data type, so the TransactionHistory query will need the data type transformation.
The solution for this problem is to use duplicate, instead of reference. If we duplicate the TransactitonHistory query before applying the data type transformation, we will have control of the data type transformation on the MinDate and MaxDate query and we will still be able to apply the same data type transformation on the TransactionHistory without affecting the other ones.
This is a very interesting example because we can clearly see the difference between Reference and Duplicate of a query and this example will only have good performance if we duplicate the query.
But when duplicating the query, aren’t we multiplying the execution time? If the queries are completely transformed in different native queries, the “duplication” of the execution time would happen anyway but isolating the queries with the Duplicate option we can optimize each one to make them faster.
In summary, on our example the secret is duplicate the TransactionHistory before changing the data type, implement each of the duplications, leaving the change of the data type for last and finally changing the data type of the TransactionDate field in the TransactionHistory query.
The Result
The sequence of the tasks is different, we leave the change data type and drill down for last. They will be executed over a single value and will not become part of the native query.
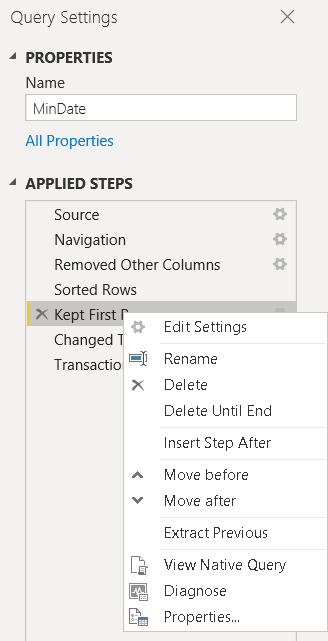
The native query is simplified, without the type conversion.

This makes a way better query plan, making a good use of the index for the transformations and making the result way faster

After Match
After analysing and solving these performance problems, let’s complete the example creating the date dimension.
We can use a function written in M by Chris Web. You can find the function on this link https://blog.crossjoin.co.uk/2013/11/19/generating-a-date-dimension-table-in-power-query/
- On the top menu, click the button New Query-> Blank Query
- Click on the menu View->Advanced Editor
- In the Advanced Editor window, paste the query copies from the Chris Webb blog

- Click the Done button
- Rename the function to BuildDateDimension
- On the top menu, click the button New Query-> Blank Query
- Click on the menu View->Advanced Editor
- Add the following Query:
|
1 2 3 4 |
let Source <span style="color: #333333">=</span> BuildDateDimension(MinDate,MaxDate) <span style="color: #000000;font-weight: bold">in</span> Source |
- Click the Done button
- Rename the query to DateDim
Lessons Learned
- It’s important to know SQL Server and query optimization to work with Power BI
- Sometimes the optimization is beyond Power BI, it’s on the source system
- In Power bi ELT’s, if you make table level transformations and filters first and leave column level transformations for last, the native queries may be easier to optimize
- You need to take care with the decision between Reference and Duplicate
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments