
One great result from PASS Summit, especially when we are close to a new SQL Server release, is to identify important technologies to study on the following year.
PASS Summit 2018 was great, with sessions about many new technologies giving us very good guidance on where to focus our study for the new year. Let’s talk about some of these new technologies.
Of course, everything here is my current knowledge and information from the event about these new technologies, let’s talk about them on the comments.
Hyperscale
The 2nd day Keynote on PASS is well known for being a mind-blowing keynote and this year was no different.
You can watch the keynote here
However, the real mind-blowing part starts on 41:36, when the speaker invited to the stage starts explaining how Microsoft created a system of infinity, yes, infinity scalability, going deep in detail about the architecture of the Hyperscale system.
This is, for sure, something to be studied and tested if possible.
By the way, you can find more free videos from PASS Summit 2018 here
Intelligent Query Processing
First and foremost, why change the name? We are barely getting used to adaptive query processing!
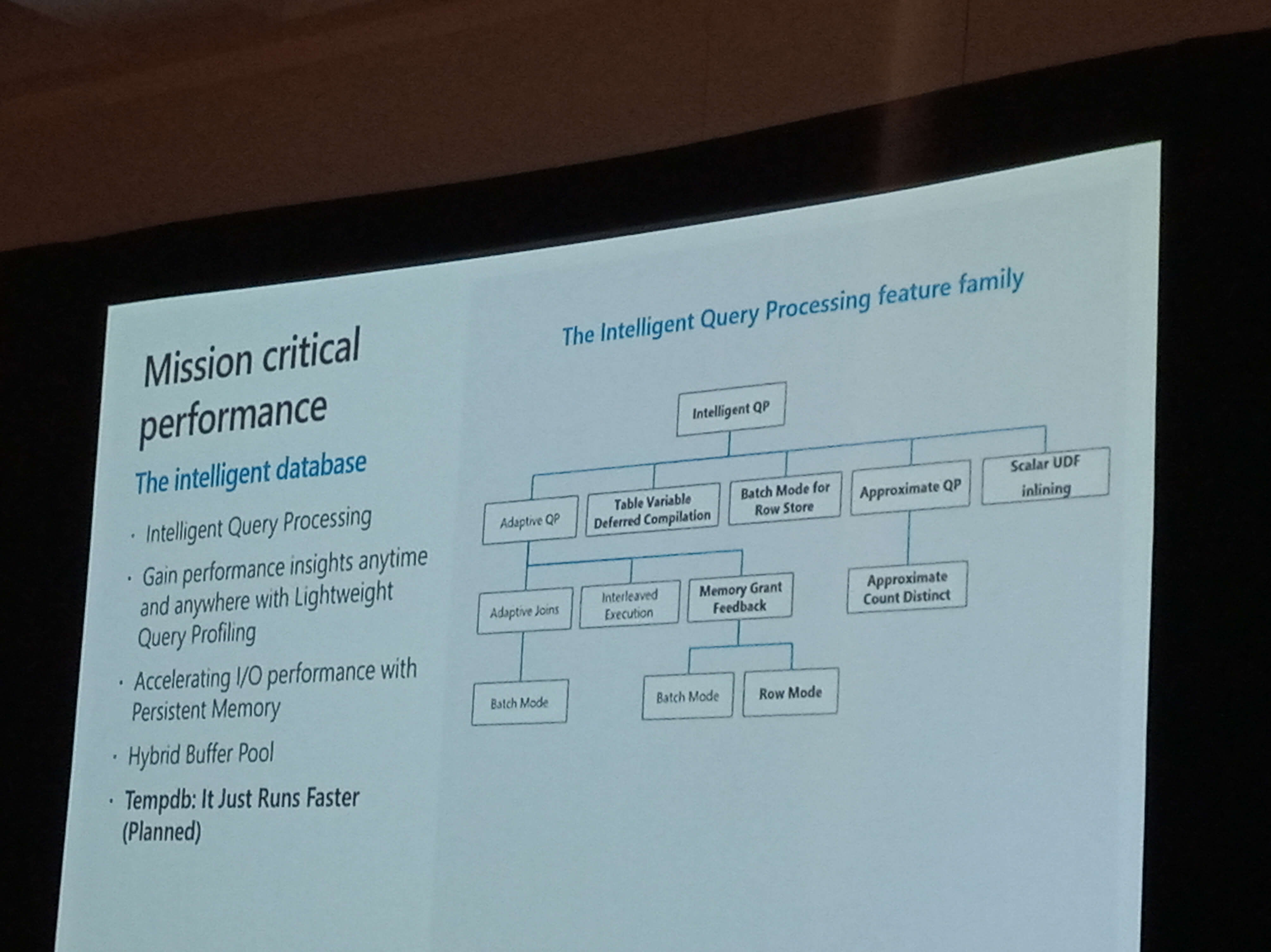
The idea of the adaptive query processing is to adapt the plan during the execution. On the other hand, the new features being included are more intelligent behaviour, don’t fit under the adaptive query processing scope. Being so, we have a new name, Intelligent Query Processing, which includes Adaptive Query Processing and other new features more.
Name explained, but what about row vs batch mode, the most expected new feature?
Well, among the three kinds of adaptive query processing, only memory grant feedback will be working with row mode, all the other remain the same.
However, there is a catch: some expensive analytic queries will be changed to batch mode even without a Columnstore Index, thus they will be able to use all batch mode features.
You can check more details about Intelligent Query Processing and also find some demo scripts on this link
Big Data Cluster
Big Data Clusters is, in summary, the SQLServer version of a Hadoop cluster, using HDFS to store data.
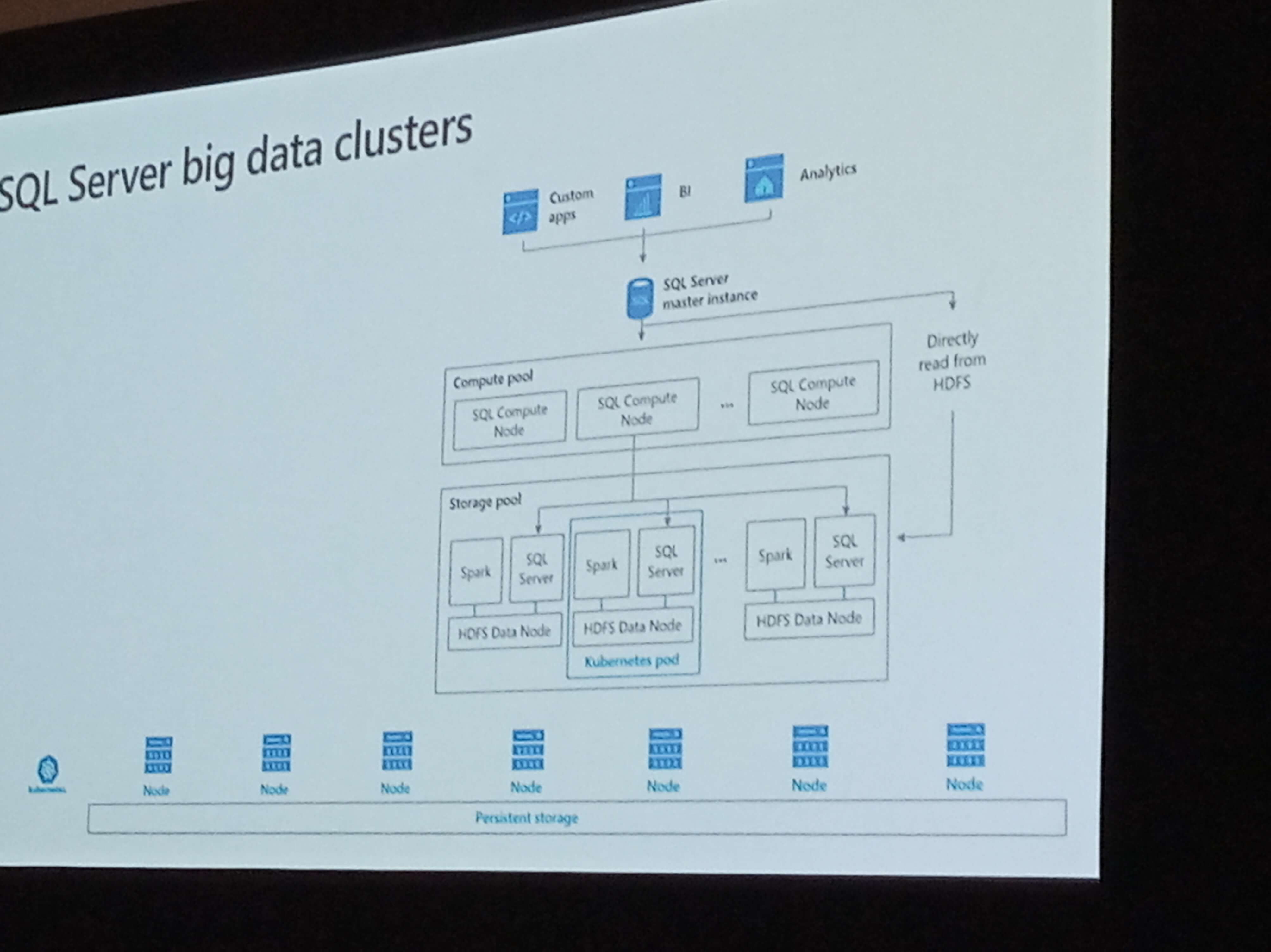
SQL Server core was redesigned as microservices and each node of a big data cluster uses Kubernetes to be executed. I’m not sure yet what kind of impact this will have on the DBA – will we need to learn about Kubernetes?
The Big Data Cluster is comparable to the PWD, but PWD is made for relational data, while the BDC uses HDFS, so it’s made for unstructured data. SQL Data Warehouse is the cloud version of PWD, it’s also made for relational data.
The best comparison is with Azure Data Lake. On one hand, Big Data Cluster is the technology to enable us to build an on-premise data lake. On the other hand, the architecture is completely different, Azure Data Lake uses U-SQL while the big data clusters will use T-SQL
So, how will all these technologies fit together? For now, no one has no idea, but my crystal ball believe these solutions will be integrated somehow in such a way they all can be managed from azure data studio
You can check more about big data clusters here
Query Performance and Tunning Improvements
Pedro Lopes and Joseph Sack did a great work introducing a lot of new features that are already in preview. Let’s do a small summary about them.
SSMS 18 includes a new graphic for Wait Stats categories. The capture of the wait stats in SQL Server 2017 was already great and now we have a new graph to show the values for us.
A lot of new information was in the execution plan:
- Active trace flags
- Statistics used during the compilation, including the modification count
- UDF CPU and elapsed time
- Grant and used memory per thread
- A lot more warning details
This will be very useful when analyzing the performance of a server. Have you read my articles about querying the plan cache (here and here)? Using all these new information we can build very interesting queries to check about many problems on the existing query plans that we couldn’t check before – and we can also query them inside query store system tables, not only on the plan cache.
You can read more about SSMS new features here
Table Variables Deferred Compilation is also a very good improvement. If we can’t convince them to use temp tables, let’s improve the table variables.
A query against a temp table already uses deferred compilation, meaning that the query will only be compiled on the first execution of the query, not together with the entire batch, so the batch will be called, create the table, fill it and only then the query against the temp table will be compiled.
On the other hand, a usual query against a temp variable is compiled together the entire batch, when the variable is not filled yet, so the query is compiled considering a total of 1 record.
The change is simple: Now queries against table variables also use deferred compilation, waiting for the execution of the statement to be compiled and improving query performance.
More details about this new feature on this link
On the entire session, however, one of the features that most impressed me was the Lightweight Query Execution Statistics Profile. The final result is simple: using SSMS 18 we can view the execution plan of an existing online session in SQL Server without the complex infrastructure that was required before.
This feature is also available from SQL Server 2016 SP 1: you only need to enable TF 4212
Power BI New Features
Power BI usually has so many new features that It’s very easy to get lost among them. Two new features caught my attention:
Support for Reporting Services files: Power BI supports the publishing of reporting services files. This is a great feature for migration of environments from reporting services to power bi, enabling the users to continue using the old reports and migrate than easily to a new format. You can check more about this on this link
Dataflows: The Dataflows are an evolution of the power query, although not exactly a replacement. The Power Query code is stored within the Power BI file, so if you need to use the same data source again, you may need to copy the M script to a new PBIX file.
The Dataflow, on the other hand, is stored and processed on power bi online. It imports the data to Azure Data Lake storage on Azure using a text format to store the data. You can re-use the data from the ADL storage and schedule the update online on the Power BI service. The process is closer to an ETL process, being able to use ADL storage either for intermediate steps for the transformations and for the final data.
As usual, new features created by Microsoft raise many questions. How will this fit together with other technologies, such as ADFv2 which enable us to execute SSIS packages on the cloud? Is Microsoft going too far on self-service BI and enabling users to create small monsters or will be this, in the end, easier to manage than the alternatives?
Matt Allington published an interesting article and video about Dataflows, you can check on this link
Azure SQL Database Managed Instances

The Managed Instances got many sessions during PASS Summit. Before this new Azure service, we need to choose: We could use PAAS with SQL Databases on database level, but if we need any instance level service we would need to use IAAS, creating our own virtual machines.
Using the new Managed Instances we can have instance level services such as SQL Server Agent, replication, SQL Audit and many more on a PAAS environment, avoiding the need to manage an entire virtual machine such as in IAAS environments.
One of the most impressive features of the Manage Instances services is the Always on Availability Groups as a PAAS service.
You can check more details about managed instances here
Conclusion
We have, for sure, a lot to study on the following year, until next PASS Summit comes to increase this list even more. You can start checking these links:
Join the early adoption program
See what’s new in SQL Server 2019
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments