

When learning something new, we always compare it with what we know. In this case, we end up comparing KQL with SQL.
In SQL, when we need to get the top rows based on a grouping, the process is not easy. For example, let’s say that in a table containing taxi rides, we want to retrieve the record of the ride with the highest fare on each day.
There are multiple ways to do this, none is too easy. One of the methods is to create a row_number based on the day. This can be achieved using what’s called in SQL as window function. In this case row_number with a stablished window in the result based on the date.
After creating the row_number, we select every row where the row_number is 1: The topmost row for each date.
Here comes the good news: In Kusto we can achieve this in a way easier way
The ARG_MAX KQL function
The documentation of this function is quite complex. In summary, this function can bring the records with the topmost value of one field.
This can be used together a Summary statement or not and it will create different combinations of result.
As an example, I will use the RIDES table from the New York taxi ride. This can be used in real time samples inside Fabric.
No Grouping
Using the ARG_MAX with no grouping means bringing the topmost record from the table based in one of the fields. Let’s consider the field FARE_AMOUNT.
The query will be like this:
|
1 2 |
rides | summarize arg_max(fare_amount,*) |
The ‘*’ means we want all the fields from the table returned. The FARE_AMOUNT specifies we want only the record with the topmost fare amount. The result will be a single record.

Single KQL Grouping
Let’s consider we want the record with the topmost fare for each day. In this scenario, we can use the “BY” clause together with the SUMMARIZE to achieve this result.
|
1 2 3 4 |
rides | extend rideDate=startofday(tpep_pickup_datetime) | summarize arg_max(fare_amount,*) by rideDate | order by rideDate |
On the image below, for each day, we get the row with the highest fare amount.

Multiple Grouping
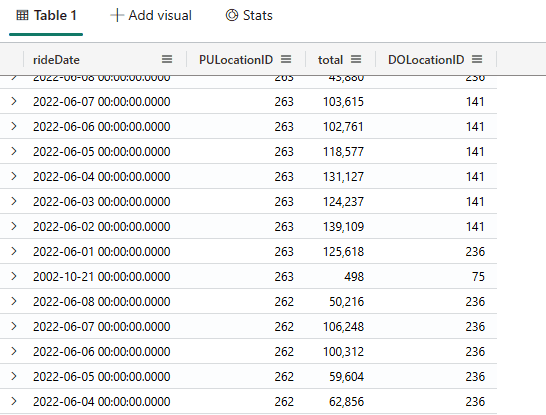
Let’s consider a more complex scenario. For each day and each pickup location, we want to discover what’s the drop off location with the highest number of rides.
In other words, on each day, from one neighborhood, what’s the destination with the highest number of rides?
In this scenario we have 3 groupings: Date, Pick Up Location and drop off location. We want to get the topmost count according to the 3 and get the Drop off location with this value for each combination of the first 2.
The query will be like this:
|
1 2 3 4 5 |
rides | extend rideDate=startofday(tpep_pickup_datetime) | summarize total=count() by rideDate, PULocationID, DOLocationID | summarize arg_max(total, DOLocationID) by rideDate, PULocationID | order by PULocationID, rideDate |
After calculating the COUNT, we use the arg_max together with the summarize to get the DOLocationID with maximum total according to the Date and Pickup location.
The image below illustrates how we get the Drop Off location with the highest number of rides for each Day and Pickup Location combination
Summary
The documentation doesn’t help too much, but this function makes complex analysis in KQL way easier than it would be in SQL.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments