
If you’ve been to a conference over the last few years, you’ve probably come across microservices. A microservice architecture consists of many highly decoupled services that are independently deployable and organized around business capabilities. This isn’t a new idea, SOA had similar ideas in the 90’s but the technology around it was clunky (it seemed to involve an awful lot of XML — never a good start!).
Individually microservices are simple — they are small and do one thing. However, imagine you’ve got a few hundred and now you need to start managing those messages, get some consistency and put some standard functionality in (think orchestration, transformation, routing, circuit breaking etc.). How do you do this consistently?
Solving the problems around service communication
The first option is a message queue. Instead of point-to-point communication use a central store (Enterprise Service Bus) and everything communicate through that broker. A broker service like RabbitMQ can support multiple protocols/transport and do all this out of the box. Message buses also help with scalability, but this comes at a cost. The centralised bus is a single point of failure (SPOF). To address this, message buses are typically clustered for reliability and resilience. This therefore has a high operational cost.
Another option for managing microservice communications is an API gateway. An API gateway can make client code (that consumes microservices) easier to write by effectively bundling APIs together to present a uniform interface for clients. Imagine a reverse proxy on steroids. API Gateways run on the edge (the boundary between services and clients) and give consistency through API management (versioning etc), security and SLA management. Examples of this include APIGee (acquired by Google) and Apiary (acquired by Oracle). One anti-pattern around API Gateways (as noted by Thoughtworks) is a tendency for the API gateway to grow in functionality to the point that’s it’s complexity outweighs the benefits. It’s still a SPOF and requires specialist skills to maintain.
Lately, and quickly, a new breed of technology has been developed that offers another choice. A service-mesh offers consistent discovery, security, tracing, monitoring and failure handling without the need for a shared asset like an API gateway or message bus.
Deriving a Mesh
That sounds like a desirable solution, but how’d you achieve that? Let’s try and walk through a very simplified example. We’ve got three services A, B, C and they work together to build ACME’s first web based service (it probably sells Anvils on Demand). Here’s our “architecture”
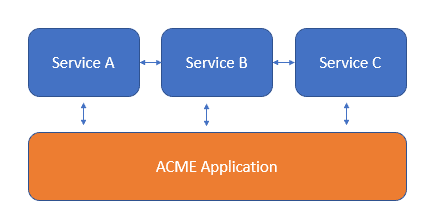
ACME. Inc Architecture
We’ve got a few problems with this. Services A, B and C and the ACME application all have some common code to communicate with each other. This is starting to get complicated — how do the servers find each other? What does Service B do when Service C goes down? And how do we get the metrics in a sensible way?
One option would be to build a library that encapsulates all this functionality. That’s an option but then we get into the dreaded world of versioning. That library is going to either be very good at versioning (can anyone do semantic-versioning right?) or it’s going to be set in stone and never updated. Any bugs or crashes in this library are going to cause service outage and building it into the application will compromise the single purpose principle of services.
As David Wheeler says, “All problems can be solved with another layer of indirection”. The answer is to factor this logic out and run it as a separate process. Let’s look at our architecture now.
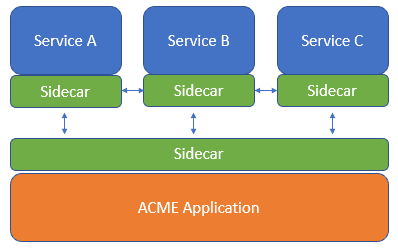
Another layer of indirection!
This is known as the Sidecar pattern. This pattern allows us to deploy more of our components as separate process/containers and reduces the amount of business logic needed in each service.
This is still a complicated set up — what does this indirection really give us? We’ve still got to write the same amount of code we did before. But do we?
What if we didn’t have to write these sidecars? What if we developed a common sidecar at a higher-level of abstraction that provided this common functionality like service discovery, authentication and diagnostics. That’s exactly what a service mesh, such as Consul, LinkerD and Istio is!

Meshes are resilient!
So, what is a service mesh?
A service mesh is logically split into two different types. The data plane mediates and controls network communication between services. The control plane is the meta level that manages and configures the sidecars themselves.
Typically the control plane is managed using a decentralised peer-to-peer approach (typically implemented by a distributed consensus protocol, such as Raft or the wickedly complicated Paxos algorithm). For the data plane, events are often distributed using a Gossip Protocol.
So in summary, you’d use the Service Mesh pattern when you’ve got cross-cutting concerns (configuration, service discovery, monitoring etc.) that you want to centralise. You solve these by using a service mesh that mediates all communication in and out of each service.
If you’ve noticed any errors in the description above, please let me know and I’ll update!
In the meantime, if you’ve read this far I should mention we are hiring for engineers in our Cambridge office. Feel free to reach out to me if you’d like to know more.
This post was first published on Redgate’s product development blog, Ingeniously Simple.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments