
For any number of reasons, from simple auditing, to change tracking, to automated deployment, to integration with application development processes, you’re going to want to place your database into source control. Using Red Gate SQL Source Control this process is extremely simple.
SQL Source Control works within your SQL Server Management Studio (SSMS) interface. This means you can work with your databases in any way that you’re used to working with them. If you prefer scripts to using the GUI, not a problem. If you prefer using the GUI to having to learn T-SQL, again, that’s fine.
After installing SQL Source Control, this is what you’ll see when you open SSMS:
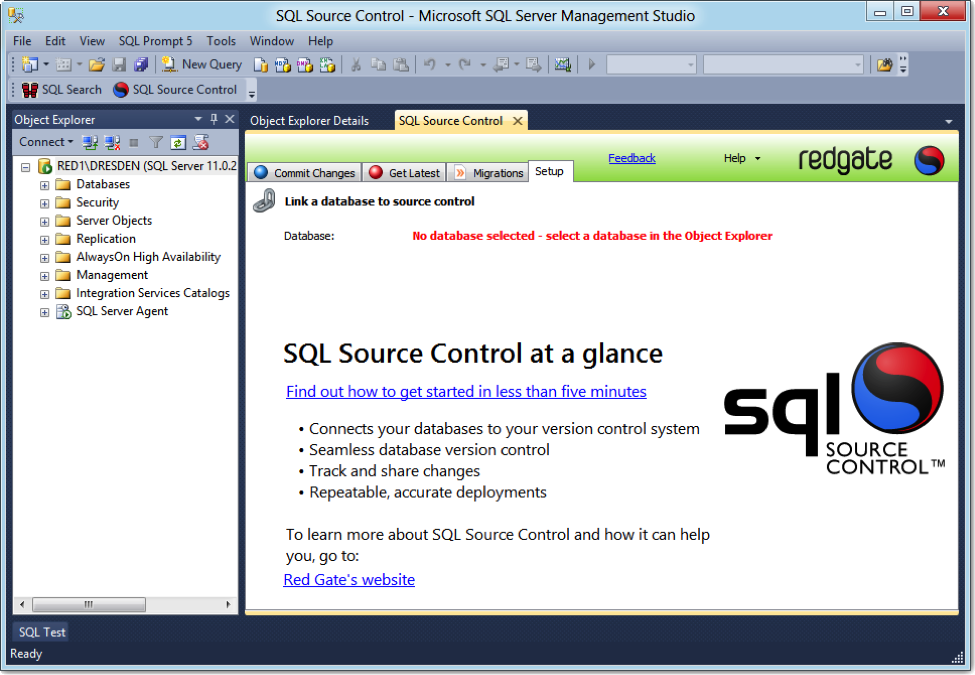
SQL Source Control is now a direct piece of the SSMS environment. The key point initially is that I currently don’t have a database selected. You can even see that in the SQL Source Control window where it shows, in red, “No database selected – select a database in Object Explorer.”
If I expand my Databases list in the Object Explorer, you’ll be able to immediately see which databases have been integrated with source control and which have not. There are visible differences between the databases as you can see here:
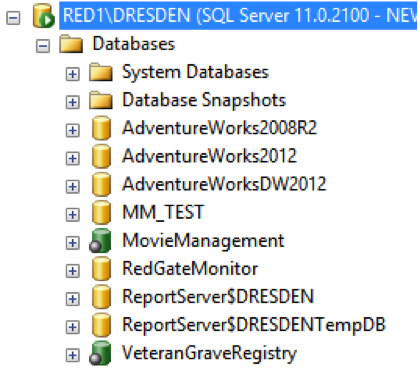
To add a database to source control, I first have to select it. For this example, I’m going to add the AdventureWorks2012 database to an instance of the SVN source control software (I’m using uberSVN). When I click on the AdventureWorks2012 database, the SQL Source Control screen changes:
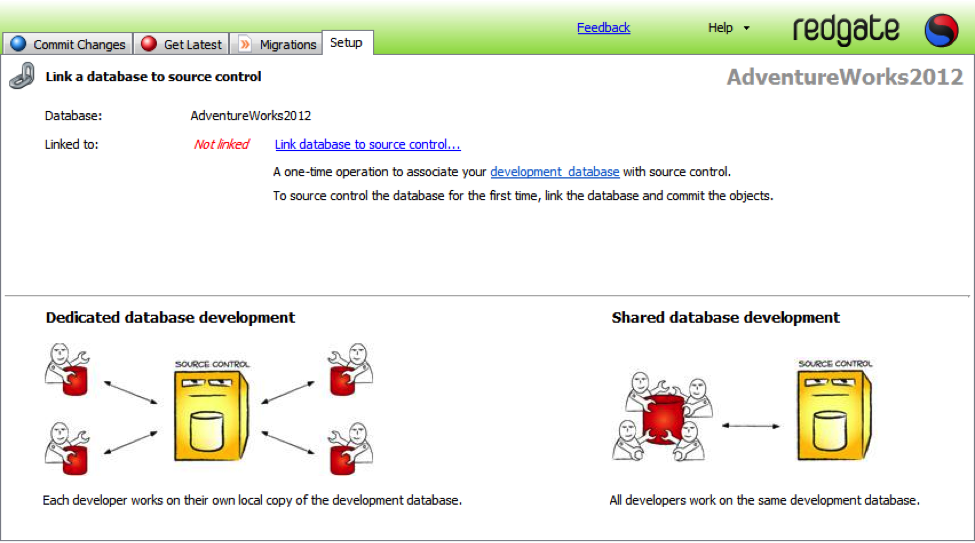
I’m going to need to click on the “Link database to source control” text which will open up a window for connecting this database to the source control system of my choice. You can pick from the default source control systems on the left, or define one of your own.
I also have to provide the connection string for the location within the source control system where I’ll be storing my database code. I set these up in advance. You’ll need two. One for the main set of scripts and one for special scripts called Migrations that deal with different kinds of changes between versions of the code. Migrations help you solve problems like having to create or modify data in columns as part of a structural change. I’ll talk more about them another day.
Finally, I have to determine if this is an isolated environment that I’m going to be the only one use, a dedicated database. Or, if I’m sharing the database in a shared environment with other developers, a shared database. The main difference is, under a dedicated database, I will need to regularly get any changes that other developers have made from source control and integrate it into my database. While, under a shared database, all changes for all developers are made at the same time, which means you could commit other peoples work without proper testing. It all depends on the type of environment you work within. But, when it’s all set, it will look like this:
SQL Source Control will compare the results between the empty folders in source control and the database, AdventureWorks2012. You’ll get a report showing exactly the list of differences and you can choose which ones will get checked into source control. Each of the database objects is scripted individually. You’ll be able to modify them later in the same way. Here’s the list of differences for my new database:
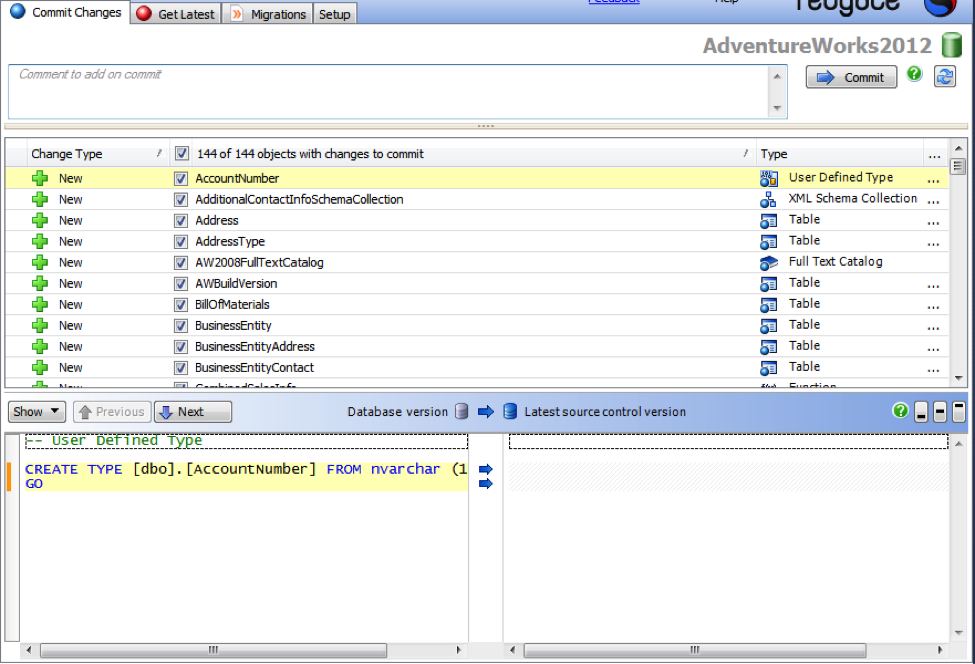
You can select/deselect all the objects or each object individually. You also get a report showing the differences between what’s in the database and what’s in source control. If there was already a database in source control, you’d only see changes to database objects rather than every single object. You can see that the database objects can be sorted by name, by type, or other choices. I’m going to add a comment such as “Initial creation of database in source control.” And then click on the Commit button which will put all the objects in my database into the source control system.
That’s all it takes to get the objects into source control initially. Now is when things can get fun with breaking changes to code, automated deployments, unit testing and all the rest.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments