

My motivation for writing this summary was an interaction with a project owner that didn’t understand why we couldn’t use feature flags directly in Power BI to control the user interface. This was different from our other deployments, so it took a few rounds of explanations to convince them that our use case didn’t support feature flags.
It’s an oversimplification to say they can’t be used in data projects. They can be used in Power BI and other reporting tools, but the implementation is different from coding languages and their usage is limited in comparison.
Feature flags can also be used in ETL tools, data engines, ETL tools, and other data tools, but with some caveats. Sometimes those caveats are severe enough that you will want to carefully consider how you use feature flags in your data projects.
Description of feature flag and use cases
Feature flags are one of the primary strategies when implementing DevOps. Feature flags, also known as feature toggles or just flags, are used to branch code depending on the current value of the feature flag. This is no different from any other branching logic, except feature flags involve a lookup to a feature flag table, or configuration file, or a call to a feature flag API. The value returned by the feature flag system is used to determine which branch of code is executed. This allows code to be pushed to production using automated methods (CICD or near CICD) before it has been fully tested. The new, untested code does not execute until the feature flag is enabled.
As mentioned, the primary use case of feature flags is to turn off or disable new features in code until they have been fully tested and related systems are ready for the changes. There are many ways to implement feature flags and many customizations possible. I won’t be covering those options, rather just considering how feature flags can be used in data projects and their limitations.
Feature Flags in Data Projects
Non-Breaking Changes
Before I get too deep into the technical aspects of feature flags in database engines and data products, the concept of non-breaking changes should be discussed. Non-breaking changes simply means that adding a new column to a table or view, adding output to a stored procedure, adding a new parameter to a stored procedure, or modifying the internal logic of a data object should not break existing usage of these objects. That includes ETL, reports, API calls, and anything else hitting that data object. Non-breaking changes are especially important for tables since they can’t be feature flagged. When you add a new column, it is there and can’t be disabled. It can be hidden behind a view, it can be empty, it can be ignored, but table changes happen immediately during deployment.
Non-breaking changes are an important design consideration with database development, whether using DevOps or manually deploying database objects. In a database project, non-breaking changes means making sure that new columns are added to the end of tables, columns and tables are removed only after all references to those items are gone, and logic changes (in stored procedures or other objects) don’t impact the output column definitions.
The basic design considerations for non-breaking changes in databases
Basic design considerations for non-breaking changes in databases is fairly straight forward. First, use ALTER TABLE to add columns rather than using the GUI to add them to the middle of your table. Next, specify columns in all SQL, SELECT, INSERT, UPDATE, MERGE, CTEs, view creation, temp tables, or any other reference to the objects rather than using the wildcard *. Some design patterns and data products gracefully handle new columns and some are very unfriendly to changes, even to views or tables when columns are added at the end. You will need to understand how the data products you use in your environment handle changes, and mange objects with that in mind.
Changes are inevitable, but careful modeling at the beginning of a project and care when making changes helps immensely. You will need to make breaking changes at some point, but there are ways to minimize their impact and downtime.
Parallel table design
One option for extensive changes is parallel table design. If you are refactoring to a significant degree, you may have to keep two tables running and in synchronization while all related code and related products are updated. Feature flags will be used at an API / application level but you will likely not use feature flags in your database objects, or reports. At the database level, new database objects that reference the new parallel tables should be created. Creating new objects is also easier to manage when you clean up your code later. The new tables will likely need to be included in your ETL, depending on the design.
Adding parallel tables can be a lot of work, but refactoring to this degree is always a lot of work. After the new tables are in place and data is being maintained in both copies, the real work begins of changing anything dependent on those tables. Hopefully you don’t allow external applications or reports direct access to your transactional tables, which minimizes impact. When all code has been refactored, the old tables should be removed.
Changing existing objects
You won’t normally need to create parallel tables. The existing table will be modified or data objects will be added and modified.
Change all code first
This is obvious, but all code that references the updated table should be added and feature flags put in place before you deploy your database changes. The new methods and feature flag code must be ready so the deployment with the modified data code doesn’t break. Using DevOps, they could be part of the same release, but it needs to be ready when the data code is updated.
Update data objects
Database objects need to be updated as well. Update stored procedures, views, and functions. Don’t forget items such as indexes, constraints and foreign keys too. If you are using a data project in Visual Studio, build your project before you check in the code to make sure everything compiles after your changes.
It is sometimes necessary to manually update data with a pre-deployment script or items may need to be modified with a post-deployment script. This should be avoided when possible, but for breaking changes it isn’t always possible. Also watch for issues with nullability of columns. It is sometimes necessary to deploy the column as nullable, populate it, then change it to be not nullable later or in your post-deploy.
Update data products
Reports and ETL flows also need to be updated. Data models, metadata, SQL scripts, and any other references to the modified database code needs to be fixed. The deployment timing of this is also critical. These deploys need to happen before the breaking change is implemented or in conjunction with the change.
Final steps and considerations
Removing columns can have the most impact. This will be the last change you would make, as it will break anything referencing that column.
When everything is updated and the new code path is getting used, the deprecated objects can be removed. Monitor the database and connected systems for errors. You will need to work with external teams to be sure they modify their connected tools also, but this should happen early in the process.
Impact of adding columns
It can be tempting to add a column to the middle of a table. Developers and business users like data to be grouped together logically within tables. Adding a new column that logically fits with other existing columns, such as additional address information, might feel like it should be placed adjacent to those columns. This can cause huge performance problems in a production system. It can also break existing queries if they happen to reference columns by ordinal position. This can be done in SQL Server in the ORDER BY statement, but it isn’t recommended.
Using an ALTER TABLE statement can mean the difference between a sub-second deployment and many hours and system disruptions if the table is large. Adding a column anywhere but the end of the table causes a sequence of events that are very resource intensive.
The following is a small portion of what happens when a column is added anywhere but the end of the table using ALTER TABLE. You can see that a temporary table is created, foreign keys are dropped and recreated on the new table, data is transferred, the identity value is set, extended properties are set and any other table properties. Finally, cleanup tasks are performed.
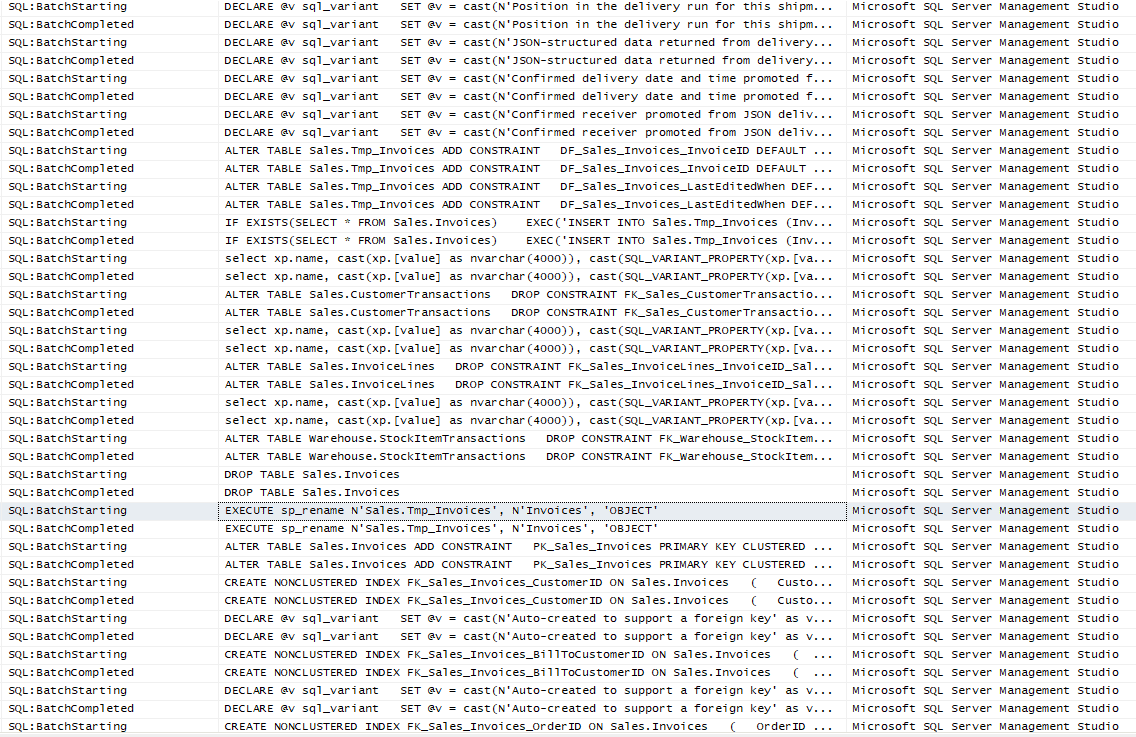
In contrast to the above, adding a column to the end of a table with the ALTER TABLE statement, either explicitly with the SQL statement or by using the GUI, is generally a sub-second operation and has very little impact on the table and database in general.
|
1 2 3 |
ALTER TABLE Sales.Invoices ADD NewColumn2 int NULL GO |

Good coding practices at the application level are also needed to ensure database changes don’t break the application. Avoid SELECT *, each column used by the application should be specified.
Test Base
The following examples presented here use a very simple feature flag table. A single table, a stored procedure and a function for lookups are the complete implementation. Your actual feature flag system would likely be more complicated and have additional features. The test database WideWorldImporters was used. The scripts are presented below.
The schema and table definition:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE SCHEMA FF AUTHORIZATION dbo GO CREATE TABLE FF.FeatureFlags ( FeatureFlagID int NOT NULL CONSTRAINT PK_FFFeatureFlags PRIMARY KEY CLUSTERED identity ,FeatureFlag varchar(100) NOT NULL CONSTRAINT UNQ_FFFeatureFlags_FeatureFlag UNIQUE NONCLUSTERED ,IsEnabled bit NOT NULL ,CreatedDate datetime NOT NULL CONSTRAINT DF_FFFeatureFlags_CreatedDate DEFAULT(GETDATE()) ) GO |
The stored procedure, used in the SSIS and the ADF examples:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE OR ALTER PROCEDURE FF.prc_FeatureFlag_Lookup @FeatureFlag varchar(100) AS SET NOCOUNT ON SELECT FF.FeatureFlag ,FF.IsEnabled FROM FF.FeatureFlags FF WHERE FF.FeatureFlag = @FeatureFlag GO |
The scalar function, used in the SQL example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE OR ALTER FUNCTION FF.fn_FeatureFlag_Lookup ( @FeatureFlag varchar(100) ) RETURNS bit AS BEGIN DECLARE @IsEnabled bit SELECT @IsEnabled = FF.IsEnabled FROM FF.FeatureFlags FF WHERE FF.FeatureFlag = @FeatureFlag SELECT @IsEnabled = ISNULL(@IsEnabled,0) RETURN @IsEnabled END |
Feature Flags in SQL Server
The above section on non-breaking changes demonstrated that feature flags can’t be used on tables. They could potentially be used with views but not to add or remove columns, only for logic in a view. The best location to put feature flags in the data engine is within stored procedures since they are generally where any database logic will reside. But it is usually easier to include that logic in your application. Given those limitations, this section describes how you can use feature flags in SQL.
Fast, reliable and consistent SQL Server development…
Stored Procedures / Functions / Views
Stored procedures can easily use feature flags, especially if they are stored in the same database or the flags are passed in as a parameter. If an API is used, it can be called directly from SQL using sp_OACreate. This can also be done via a CLR stored procedure using C# and standard libraries. The first part of the code, or a predecessor to the current stored procedure needs to make this call, then CASE statements or IF statements can be used for the branching logic.
Even though you can call APIs directly from SQL, I would not recommend this pattern. It has the potential to open security holes since it increases the surface area used by the SQL engine. It is also more fragile compared to calling the API from your regular coding environment. There are some additional steps needed to configure the engine to allow this and you have to allow the SQL Server to call the IP or range of IP addresses used by the API servers. It’s not a great pattern. In addition to the security and configuration issues, it is also a more fragile design.
An alternative method
Another method that can be used with stored procedures is to create a new version of the stored procedure and call the correct version from your API. This allows you to place all the logic in one location, it is less fragile, and cleanup is easier in SQL Server. Cleaning up feature flag code can be tedious and has potential to introduce new bugs. If there are versioned instances of stored procedures, they can simply be deleted after they are deprecated. Removing an entire stored procedure is easier to get right compared to surgically removing portions of code. Having multiple, versioned, SQL objects doesn’t incur a performance penalty since it is just metadata storage. Be sure you have a clear naming standard and clean up code promptly or the duplicate objects can become very confusing.
The following example shows using a feature flag inside of a view. The scalar function presented above is used to determine the current state of the feature flag. If it is set, the column is presented as-is. Not set? The hard-coded mask is presented. If there were issues, the flag could be disabled and the hard-coded masking would be presented to users again.
This shows the view altered from the default installation of WideWorldImporters:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE OR ALTER VIEW [dbo].[vw_CustomerName] AS SELECT CustomerID ,CASE FF.fn_FeatureFlag_Lookup('SQL Example') WHEN 1 THEN CustomerName ELSE LEFT(CustomerName,1) + N'xxx' END CustomerName ,CityName FROM sales.Customers C INNER JOIN Application.Cities CTY ON C.DeliveryCityID = CTY.CityID GO |
Note that in the function, a default value of 0 is returned if a flag isn’t setup. The feature flag is first inserted or updated and enabled. Results are shown from the view, then the flag is disabled with corresponding results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
; WITH SQL_CTE AS ( SELECT 'SQL Example' FeatureFlag ,1 IsEnabled ) MERGE INTO FF.FeatureFlags FF USING SQL_CTE TF ON FF.FeatureFlag = TF.FeatureFlag WHEN NOT MATCHED THEN INSERT ( FeatureFlag ,IsEnabled ) VALUES ( TF.FeatureFlag ,TF.IsEnabled ) WHEN MATCHED THEN UPDATE SET IsEnabled = TF.IsEnabled ; SELECT TOP 10 * FROM dbo.vw_CustomerName ORDER BY CustomerID UPDATE FF.FeatureFlags SET IsEnabled = 0 WHERE FeatureFlag = 'SQL Example' SELECT TOP 10 * FROM dbo.vw_CustomerName ORDER BY CustomerID |
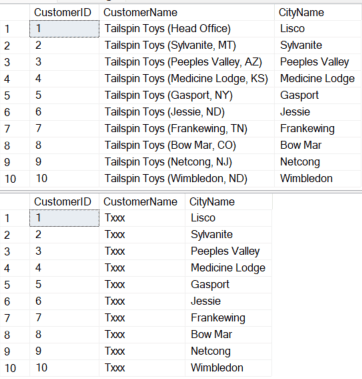
A reminder about implementing feature flags in SQL via this method. It is more difficult to maintain feature flags within data objects than creating and versioning your data objects. I’ll reiterate that deleting an entire object is much easier than correctly removing or modifying individual lines of code.
Entity Framework and Dynamic SQL
Using feature flags with Entity Framework (EF), or any other ORM, is very straight forward. Since the SQL is created by EF via code, feature flags are used in a normal fashion in the API using control flow logic. ORMs can also be used to call stored procedures. The same principles apply, use branching logic based on the feature flag to call the correct version of your stored procedure.
Table Options
This was already discussed thoroughly in the non-breaking changes section. Table changes happen immediately and can’t be put behind feature flags. Keep that in mind when adding columns, but especially when removing columns and tables. Follow the basic rules, don’t add columns to the middle of your table, use a complete column list for all queries, both DDL and DML, and work with other teams to be sure changes are understood. This includes logic changes as well as column changes.
Feature Flags in Report Engines
This is where feature flags in data projects can get tricky. You have to be very specific when describing the capabilities of a reporting system in regards to feature flags. Can feature flags be used with reporting systems? Yes and no. It depends on what you are trying to do. You generally won’t be able to control the user interface and you also probably can’t dynamically add columns unless they are already defined and in your data model. Graphics are the core of modern reporting and it is what product owners generally want modified or added to a report. This is what you would put behind a feature flag in a regular application. SSRS and Power BI don’t have feature flag support built into the user interface, but that doesn’t mean they can’t be used in other scenarios.
SQL Server Reporting Services (SSRS) Options
SSRS has not been deprecated yet, but most organizations are moving to Power BI or have it on their tech roadmap for replacement. It is still widely used and merits some consideration. You can’t dynamically add columns to SSRS, but logic behind derived columns can be modified in several ways.
The following shows the code that creates an SSRS report. It is a predefined, XML format. Trying to add a feature flag to this would not modify the report output, but would likely break the report. This is why feature flags can’t be added directly to the GUI portion of report engines.
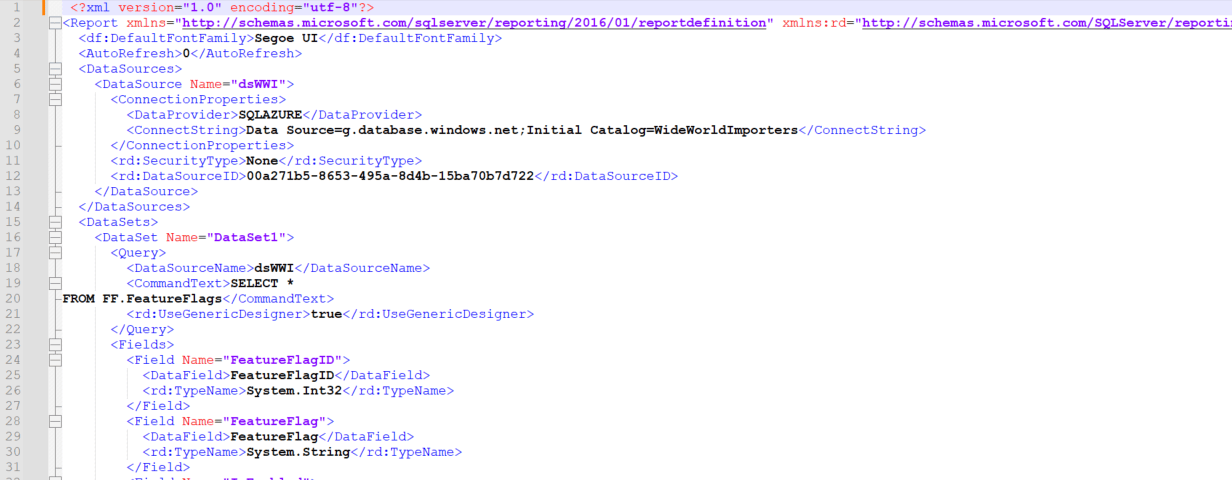
The methods mentioned previously for SQL Server can be used to control logic and versions for stored procedures and even dynamic SQL. This is no different from any application calling SQL. The feature flags can be looked up in the stored procedure itself, if they are stored in the database. The current feature flag can also be passed in as a parameter.
Using VB.NET and/or a DLL
VB.NET or a DLL can be used in SSRS. These methods can be used to look up active feature flags and call different versions of the code to manipulate data. Code is frequently used to create common blocks of code that operate on the data returned in the datasets. These blocks of code can use feature flags to determine and change the logic. If code is used to manipulate data in the report, feature flags can also be used in global variables to determine which path to run.
Code can be added directly to the report using VB.NET in the Code section:
And assemblies can be added in the References section of the report properties:
The report variables can use expressions to set variables for your feature flags or as a result of feature flags.
An easier, more testable, and more maintainable method is simply to copy the existing report and have multiple versions on the server. Having two versions is added overhead, but would be my method if I needed to be ready with a new version with no delay. If reports are called via an application or API layer, the correct version can be called based on the feature flag system used by the application, rather than trying to control it in SSRS.
Power BI
Power BI (PBI) has many of the limitations that SSRS has, but it also has some advantages not available in SSRS. Several different languages are supported directly in PBI which expands some of the options available. The following shows the raw PBIX file. You can see that it is a binary file, and the header indicates it is a ZIP file. There is nothing to modify at this level and the GUI has no support for feature flags.
Even if you change the extension to a ZIP file and open the file, you can see it contains a set of files with a set format. Even if you were to modify it directly, the report engine would have to be looking for those files or modifications to implement feature flags directly in PBI.
Using the same methods with SQL Server in Power BI
The same methods used to modify SQL logic can be used when SQL Server is used with PBI. It is easier to control this logic on the SQL side rather than the PBI side. It also has the advantage of providing consistent output no matter what application is calling the procedure.
The coding languages in PBI offer more flexibility. R is a statistical processing language, but it can be used to do many things, including calling databases or API services. R modules are available in PBI. You won’t be able to change the base behavior or output in PBI via R, but graphics and other data created and manipulated via R can fully utilize feature flags. This is a potential method to change the graphical output in PBI.
Python is also integrated within PBI. It is a full-fledged programming language and can be used to manipulate data and check feature flag enablement. Python code can be controlled by feature flags, just like standard application logic. It can be used to change the logic used within Python. The data model can’t be directly changed with this method, but logic can be manipulated. Graphics presented by Python can also be fully manipulated via feature flags.
As I mentioned, you can use feature flags with these programming languages, but that limits the development style in PBI. I have seen a large emphasis on end-user development, and this would greatly limit the pool of users able to modify the code.
Other programming languages
The other programming and data manipulation languages in PBI are more limited than R and Python. M, the query language for Power Query, MDX, used to manipulate data in PBI and SSAS, and DAX, also used in SSAS and PBI have conditional operators. IF, SWITCH, IIF, and variables can be created and used in the scripts. They can be used to evaluate feature flags and change output. This limited feature flag support depends on the data being available in the dataset or a lookup function. It is very similar to using feature flags within SQL objects and code.
Feature Flags in ETL
ETL packages have much more flexibility with the implementation of feature flags when compared to reporting engines. Control flow is standard. This makes implementing feature flags easy.
SQL Server Integration Services
SQL Server Integration Services (SSIS) can implement feature flags using any of the conditional logic operators available, as well as the SQL methods.
Since SSIS can call web services via standard tasks, make connections to databases, run custom code in C# via a script task, and call virtually any application, your enterprise standards can be maintained while using feature flags with SSIS.
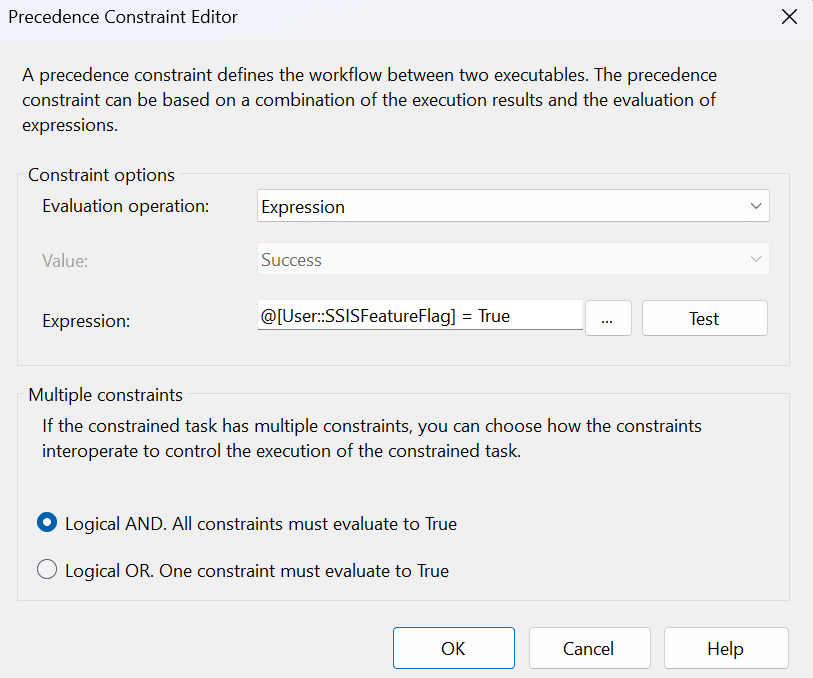
The following is a simple example of using a feature flag to determine which Data Flow Task (DFT) to run. The precedence for each DFT is set to Expression and the appropriate feature flag return value.
|
1 2 3 4 5 |
INSERT INTO FF.FeatureFlags ( FeatureFlag ,IsEnabled ) VALUES ('SSIS Example',1) |
The precedence for the “DFT – Test Flow” is set to execute when True
 Debugging in the editor shows the intended path is being followed.
Debugging in the editor shows the intended path is being followed.
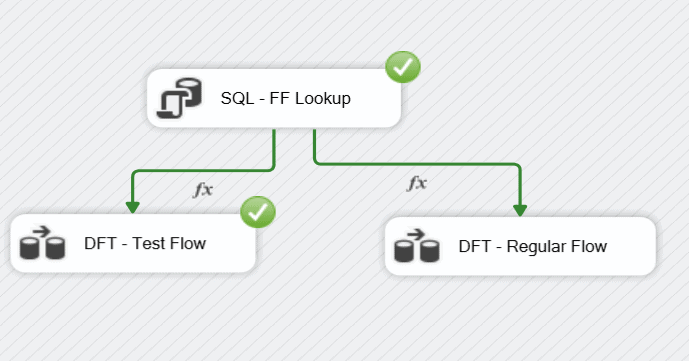
To be sure the regular flow isn’t followed when the feature flag is set, it also has an expression precedence constraint. It is set to False.
Azure Data Factory
Azure Data Factory (ADF) can use the same methods as SSIS. Database connections can be made, connections to services and virtually anything else in the enterprise can be targeted.
The following sets the feature flag for ADF to True.
|
1 2 3 4 5 |
INSERT INTO FF.FeatureFlags ( FeatureFlag ,IsEnabled ) VALUES ('ADF Example',1) |
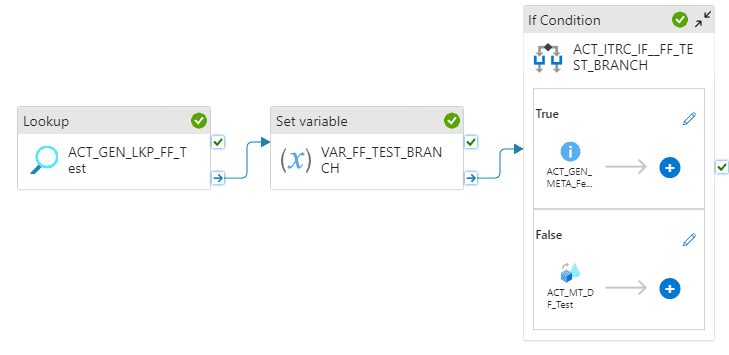 The debugger confirms that the flow followed the True path and activated the Metadata activity.
The debugger confirms that the flow followed the True path and activated the Metadata activity. 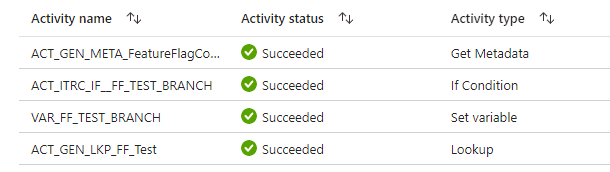
To confirm that everything is working as expected, the False condition is tested next.
|
1 2 3 |
UPDATE FF.FeatureFlags SET IsEnabled = 0 WHERE FeatureFlag = 'ADF Example' |
The debugger activities show that the Data Flow – Test path is executed during the false condition.
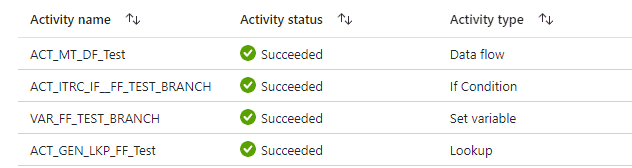
ETL Product Summary
All modern ETL platforms, including those not mentioned such as Databricks and Informatica, include control flow logic. They can usually call a service or a database to access feature flag values. This will depend on your exact environment and tools, but there is a method to use feature flags in all of these platforms.
The same reminders apply to any ETL tool. Consider what happens when the feature flag system can’t be reached or the value is not present. Default behavior should be predictable and not cause an error. Implement feature flags in a way that makes cleanup easier. Creating a new data flow, even if most of it is copied, is easier and safer to remove later when the feature flag is deprecated.
As with SQL, it is easier to remove a complete object instead of pieces of an object or a section of a data flow.
Summary
Feature flags can be used in data projects, but their scope is limited. Since report engines expect a specific file format and they use that format to create a report, flags can’t be added to a report at the GUI level unless the vendor has specific support for them. The report files are proprietary and changes to them will be ignored at best, or more likely, cause a runtime error.
Support increases at the SQL engine level, but it is still more limited than with full programming languages and custom code. Care must be taken when adding columns or modifying objects. Breaking changes should be avoided and only happen when necessary. Adding columns anywhere but the end of a table and removing columns are common breaking changes that should be avoided or carefully planned out first.
Feature flags also need to be maintained. They shouldn’t be in the system forever – they have a specific purpose and ideally will adhere to that single, time-limited purpose. Not everyone agrees with this scope for feature flags, but I firmly believe that a permanent feature flag should actually be feature of the software and not controlled by flags.
Feature flag cleanup can be a time-consuming development task. Removing deprecated feature flags should be an integral part of development. This includes removing old stored procedures, methods, and any other code related to the deprecated feature flag.
The limitations of feature flags
Depending on your method of feature flag deployment, there are limitations. SQL scripts, including post-deployment scripts, have a limit of 1000 items when used in an INSERT / VALUE statement. If you start hitting these limits or the performance of the system is impacted, feature flag cleanup needs to be a top priority.
Creating and using feature flags at a method and data object level (stored procedures, views, functions) is easier than imbedding the code within single methods or stored procedures. Simple scripts can be run to look for the old code and removing them involves lower risk than surgically removing code. Rigor is needed for both activities, but it’s better to keep things simple.
Feature flags are not magic and don’t solve all of your issues with deployments. Care must still be taken and best practices followed. Using feature flags doesn’t eliminate the need for code reviews or testing. It is also possible to introduce errors based on the feature flag code itself. Use feature flags with care in data projects, know their limitations, be consistent, test both code paths, and remove flags when they are no longer in use.
Simple Talk is brought to you by Redgate Software
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments