

At first sight, the new Copy Job may seem only one more redundancy: Why do we need this?
We have Data Pipelines for the Copy Activity and also a Copy Assistant to help us configure it. What’s new about the Copy Job?
Spoiler: It’s much more than a new UI
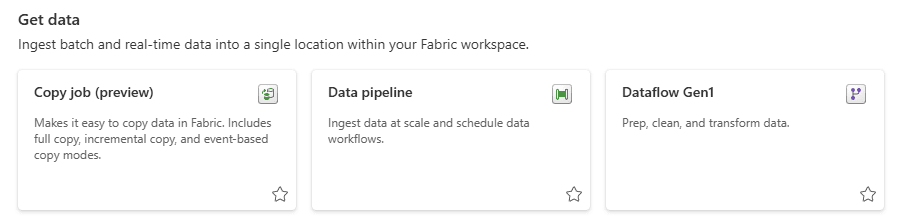
The new Copy Job Object and UI
The Copy Job is exactly what the name says: a “dedicated data pipeline” intended only to execute a copy activity. We schedule it exactly as a data pipeline.
The new UI is cute, you finish the configuration with the job already scheduled for every 15 minutes by default.
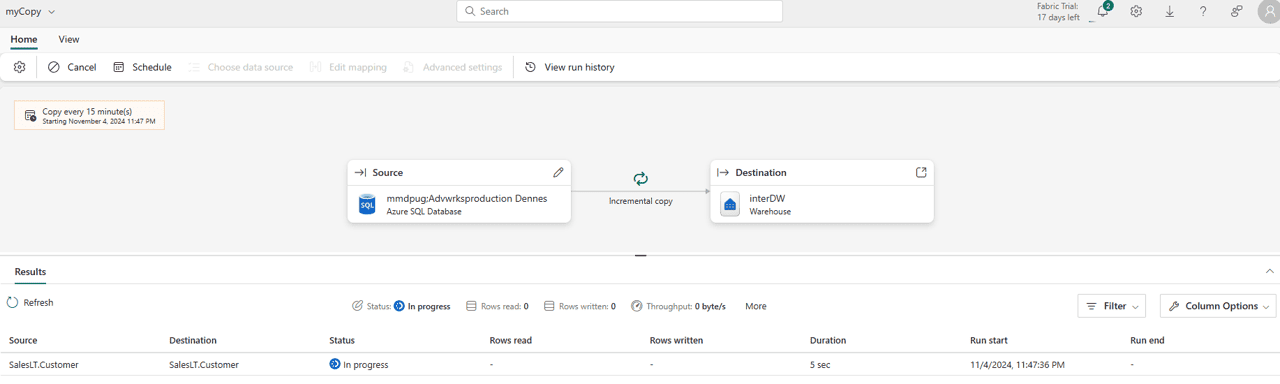
These are only the small details.
Incremental Load with the Copy Job
In my opinion, this is the great advantage of this new feature: It builds an incremental load for you.
The configuration for incremental load requires an incremental column. A date/time column which will allow the job to identify changed records.
The source model is the responsible for updating the date/time column every time a record is updated. After that, the job manages all the work.
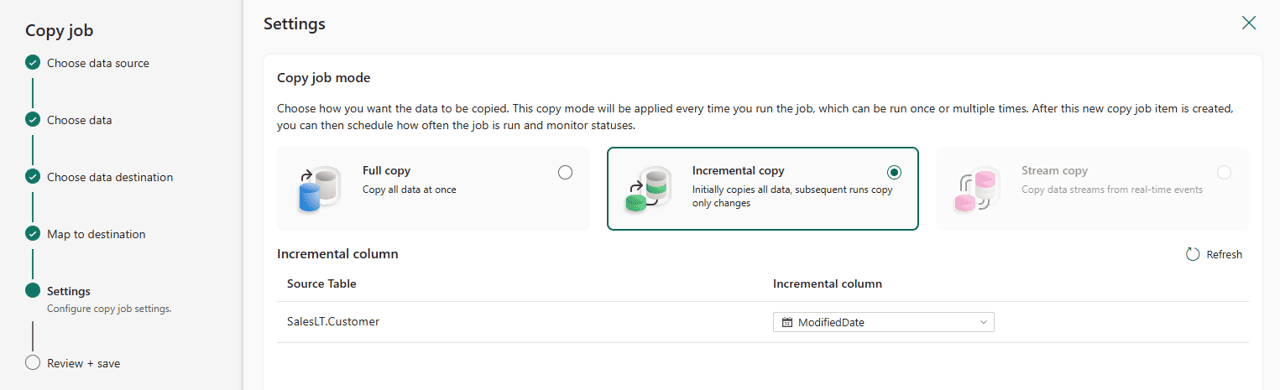
The job will make a first execution with a full load, and continue with incremental load every 15 minutes, by default.
Copy Job and Other Options
How this new feature compare with the other options?
We have the CDC Ingestion from Azure SQL and Mirroring from Azure SQL, how the new job compares with them?
Let’s enumerate some differences:
- It is not real time, it works by schedule
- It requires a special field in the source for the incremental work. CDC doesn’t
- The Copy Job is not limited to Azure SQL, the two previous options are
You can also take a look on Fabric Monday 58: Copy Job and Incremental Load
Summary
Everyday Microsoft makes it easier to put data into Fabric
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments