
Once upon a time, we got the Data Warehouse concept. A concept as great as difficult to implement.
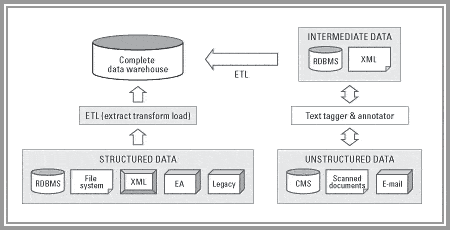 The definition of this concept may surprise you nowadays: the Data Warehouse is a collection of structured and unstructured data. The structured data is what we usually know, but what happened to the unstructured data on this concept?
The definition of this concept may surprise you nowadays: the Data Warehouse is a collection of structured and unstructured data. The structured data is what we usually know, but what happened to the unstructured data on this concept?
The Data Warehouse was always a project very difficult to implement. It’s a too long project and may take a lot of time before it shows any result.
In the beginning of a Data Warehouse project no one have any idea of all the possibilities it will create. It’s difficult to get support inside the company for an expensive project without a clear final result.
At that time, we had plenty of tools to deal with structured data, but nothing integrated to deal with the unstructured data. Add into this the difficult to convince the company about the project and the unstructured data end up forgotten.
Big Data
 Fast forward many years, the internet brought to us the Big Data concept. A huge amount of data arriving in many different forms into our servers in a speed that regular relational databases were not ready to support. Data ingestion techniques and architectures had to be created. At this point we were dealing with both, structured and unstructured data.
Fast forward many years, the internet brought to us the Big Data concept. A huge amount of data arriving in many different forms into our servers in a speed that regular relational databases were not ready to support. Data ingestion techniques and architectures had to be created. At this point we were dealing with both, structured and unstructured data.
We got, with Big Data, the concept of Data Lake. It’s simple: The amount of data is so huge we can’t afford moving it everytime we need some processsing.
The Data Lake concept arrived easily: We don’t move the data, we provision the tools and servers we need for processing, always pointing to the Data Lake.
Back to our days, we have different tools to deal with each part of this: SQL Server for the data warehouse, Event Hub and Stream Analytics for the Big Data, Hadoop, Spark and Machine Learning for the data lake, besides Power BI, a powerful visualization tool.
Each tool having it’s own techniques to be learned, this makes the life of HR specialists very difficult. It’s hard to find the professionals for each task.
DataLakeHouse
 Microsoft is going a step forward with Synapse Analytics, which integrates the capacity of all these tools in a single one, making it easier to manage and stay up-to-date, or at least we hope so.
Microsoft is going a step forward with Synapse Analytics, which integrates the capacity of all these tools in a single one, making it easier to manage and stay up-to-date, or at least we hope so.
The new tools brought the possibility of handling together structured and unstructured data resuting in the creation of a new concept: Data Lakehouse. It’s a marriage between Data Warehouse and Data Lake, dealing with structured and unstructured data, as if the original Data Warehosue concept didn’t already include unstrucutred data.
At this time, the original concept of Data Warehouse is forgotten. Everyone only hear and accept Data Warehouse as being only the structured part of the data. I saw great data professionals speaking in huge technical events and using the name Data Warehouse meaning only the structured part of the data. This scares me.
It’s not only a matter of names, it’s a matter of concepts lost in time, not being implemented, and not even having a name anymore, since their name, data warehouse, was stolen by something way smaller.
What we left behind
What concepts am I talking about ? Don’t we have everything today, structured and unstructured data, working together?
Not really. The unstructured data we are dealing with now has no relation to the original idea of the unstructured data we should be dealing with.
We have unstructured data, Big Data and Data Lake, but containing something completely new: production data, either IoT or web logs or something similar, in a global volume. We end up forgetting the original unstrucutred data we should be collecting.
Let’s analyse what is this data we are leaving behind. Take a look on the graphic below:
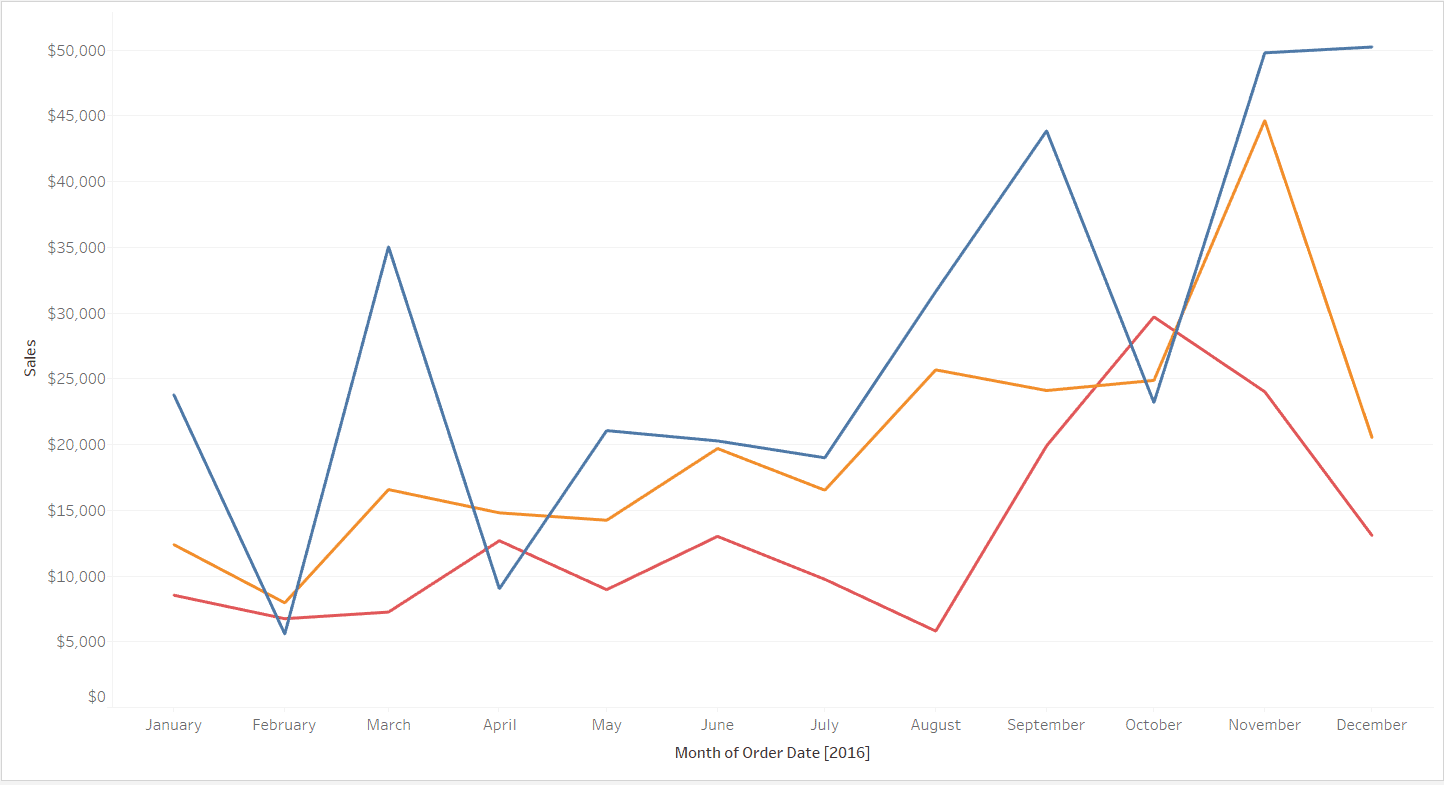
It’s a beautiful sales graphic by year, probably would worth a pay raise for the employee who built it. He only has to answer the question which come with the graphic presentation: Why on Aprial and October the sales of the blue product dropped so much?
That’s when you will discover if you really have an intelligence system. I’m not talking about technology, I’m not talking about creating an AI model to analyze the data. Most times the data was not even collected and stored.
We need to be able to register the fact the company replaced the sales supervisor on April and the new sales supervisor tried many different sales, some of them with success, some not.
That’s the piece we are missing. There are many systems in production where the company just change the price of the products when creating a new sales. How register the sales? How they register the success or failure of the sales for the future analysis? Many production systems don’t record anything like this. CEO’s want information extracted from a set of data, .but many times the information is not there.
These below are some examples of essential information we need to take decisions. Most companies are not keeping this information together the data warehouse:
- Business decisions
- Replacement of decision makers
- Business process changes
- System changes
The original Data Warehouse theory involves not only capturing the production data, but also capturing context information to make this data meaningful. Sometimes this means changing company processes to start recording, somewhere, employees decisions that affect the company results.
Conclusion
The technology advances way faster than the theory and, due to that, the uninformal meaning of names end up changing across the years.
The danger these naming changes pose is the danger of forgetting the innitial idea of a Data Warehouse. The techniques which should be used to keep the data relevant for decades are left behind, making the company rely on employees memory.
Considering the business speed on the internet, maybe for some business this relevance across decades is not important. However, there are many areas which would appreciate this additional intelligence on our data. However, when we talk about intelligence nowadays, everyone only look towards AI expecting something magic to happen. People don’t look towards the collecting of the data which should have been better planned in the first place.
Let’s talk more about this. Comment about your experience:
- Have you faced lack of context information like this before?
- Do you know business for which this would not be relevant?
- Have you manage to implement this kind of data capturing on a project?
- What you think about the mix of Data Warehouse definitions? The original including unstructured data and the new one only the structured data, resulting the creation of the DataLake House concept?
if (window.location.href.indexOf(“simple-talk”) == -1)
{
window.location.href=” https://www.red-gate.com/simple-talk/blogs/data-warehouse-concepts/“;
}
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments