

A SQL Server database configuration audit is where most issues are found — from compatibility levels and file locations, to backup models and in-memory table settings. This final part of Ben Johnston’s complete guide to auditing a SQL Server walks through every key database-level configuration item you need to check, explains what to look for in each, and provides ready-to-run T-SQL scripts to gather consistent, repeatable results across both on-premises and Azure SQL environments.
This is the fourth and final part of my series on how to successfully audit a SQL Server. In this section, I’ll examine and explain database configuration audits.
As with the previous audit sections, the boundaries for the audit can be blurry. I try to stick to configuration items only, but I also discuss some code smells and items that can impact performance or might be covered in a code review. You will need to determine the scope of your audits and how much you want to cover in this portion of the audit.
This follows the patterns of the previous audits, starting with a list of items to validate, followed by key points to examine for each of those items, and ends with scripts or tactics to gather the actual audit results. As with previous audits, there are multiple methods to examine each item, but I generally prefer scripts due to their repeatability, especially when they need to be run by another team.
General Audit Template
- Database configuration
- Database compatibility level
- Database configuration
- Configuration options not set to default
- File locations
- Data
- Log
- Tempdb
- Backup
- Database level collation
- Containment model
- Backup model
- In-memory table configuration and full-text
- Elastic queries
- CLR Integration
- Extended events
- Environment differences
- Database configuration
Evaluating SQL Database Configuration
The focus of this audit is the database level configuration. The configuration needs to be checked for each database on the server, or virtual server in Azure. This is similar to the server items, with some additional details. The database configuration and options, file locations and drive types, the backup model, and other database specific items need to be confirmed, documented, and evaluated.
Installation options, such as database level collation, containment level, backup model, and in-memory table configuration should be noted. There isn’t a default right or wrong answer to these, but they should be correct for the environment. Correct for the environment means they meet the business requirements and are consistent with enterprise standards. Even critical items such as the backup model depend on the requirements and enterprise standards. A large portion of this audit is ensuring the database configuration is consistent and expected.
Database compatibility level
The compatibility level should be checked for each database. There is a minimum level allowed depending on the database engine. This is easy to overlook, but it can have a significant impact on performance and available functionality. When possible, you want to be on the highest compatibility level available. Don’t move to the latest level without testing applications hitting the database and the application specific workload. As I mentioned, it can have a significant impact on performance, but that can also lead to degraded performance in certain limited scenarios.
Document the compatibility level for each database. Note databases that are not at the latest level. Flag any databases that are more than one version behind. You will want to know if this is an oversight or if there is a specific reason for the discrepancy.
Database configuration and configuration options
As in the server configuration, any database setting not using the default value should be documented and explainable. These can range from minor items to extremely important items with performance or recovery impacts.
Azure SQL has a number of options that are configurable at the database level, so this applies to both full SQL installations and Azure SQL. If you are looking at a server installation, remember that database options will generally override the sever level settings. An example of a difference you might see is the maximum degree of parallelism, or maxdop in the database scoped configuration. You can set a default at the server level but it can be changed at a per-database level.
Note these configuration items, especially those that differ from the defaults. As with SQL Server configuration items, the general guideline is that the options should be left at the default unless there is a specific reason for changing them.
Fast, reliable and consistent SQL Server development…
File locations
File locations for on-prem servers need to be documented. The rule of thumb is that the data, log, tempdb, and backups should be on separate drives. This can differ based on the type of media, but it’s a good starting point. The performance limiting factor for most SQL systems is the I/O subsystem. Putting these files on different drives is a good starting place for healthy I/O.
The default file locations at the server level are useful to know, but the actual file locations for each database need to be confirmed. This is where it is actually important to have the locations separated for a full SQL Server installation. As mentioned in the server section, if you have non-traditional disks, such as SSDs or memory-based drives, this may not be an issue. You still need to be sure you don’t overload the I/O subsystem, but this is much less likely when you move away from traditional drives. Work with your admins and be sure the I/O throughput is sufficient for your server. Note anything that is not using the default location. The files should be separated by type onto different physical drives. This can have a major impact on performance due to the difference in access patterns for each file type.
The number of files, their configuration, and locations should be documented. Look for overlap between different databases. Also investigate files not in the default location. If I/O issues were discovered in the server hardware audit, this is a primary concern. If you see that database files are in a non-standard location or row data is in multiple locations, it’s a good indicator that there have been previous I/O concerns with this database.
Tempdb file configuration also needs to be examined. The scripts used to examine tempdb are the same, but it will have a different optimal configuration. It is recommended that tempdb files are on separate drives from your other databases. You will generally want 8 data files for tempdb, but this is another item that has changed over time. Refer to current documentation for the best configuration. It can also help to put tempdb on SSD drives.
If your server is on a Managed Instance or is an Azure SQL Database, you have even less control. Performance tiers and options change frequently, so additional options will likely be available in future iterations. Document the performance tier and be aware of the I/O limits with the current configuration.
Database level collation
Database level collation is an informational item for this audit. The collation can impact matching, duplicate behavior, and accuracy of data storage. Document it for this audit. It should be consistent between databases in the enterprise, or there should be a reason why it was chosen if different from the default. Remember that collation can be changed at a table, column, and even query level too.
Containment model
The containment model for the database should be documented. Having a contained or partially contained database can have a few advantages. It makes moving to Azure easier and it can help with Always On failovers. If you’ve ever had user differences between servers in an Always On scenario, you understand why this would be useful.
The containment model isn’t right or wrong, but it should fit the goals of the database, future migrations, and administrative goals. Document the containment model and be sure it fits these needs.
Backup model and backups
All of the configuration items for a database are important, but the backup model is one of the most important. There isn’t a right or wrong recovery model – the correct model depends on the database use case and standards. Note the recovery model for each database. The model used should support the business requirements for business continuity. Backups should happen frequently enough to recover data within the defined recovery window. This needs to be balanced with the ease of administration and recovery. It is easiest to perform a full backup every night, but this takes more space than combining full backups, differentials, and transactional backups. More frequent transactional backups make your recovery window smaller, but are more work. Everything is a trade-off. You will usually want to err on the side of recoverability.
Check the standard items for the backups. If using a full recovery model, the logs should be backed up on a regular basis, verify the timing of backups, check the physical location for the backups, check if off-site storage is used, check when test restores are performed, and check the security of the backup location. This isn’t an item you want to rush through.
In-memory table configuration and full-text search
In-memory tables can tremendously improve performance for hotspots, trouble areas, or critical tables. The downside is that the memory they consume is not available for the rest of the system. This is very similar to tables pinned in memory in older versions of SQL Server (6.5, etc.). They make more sense now with the relatively vast amounts of memory available to systems compared to older servers. If you see that a database file is configured for memory optimized tables, it merits additional exploration. You will want to understand how it is getting used and the reason it was configured. At a database level, this will be seen as a file type description of filestream.
Full-text search is another item you will want to explore. Full-text search is a very I/O intensive item. Check to see if it is enabled and if any full-text indexes are configured. In addition to the performance overhead, they need to be managed separately. Document these items. This is an item that is also worthy of additional consideration. Newer technologies are available that may be more appropriate for the business objective.
Elastic queries
Elastic queries are mentioned in server configuration, but they are implemented at a database level. Check each database to see if elastic queries are used. Verify and document how elastic queries are used for each database. I have found them to perform very well, but it really depends on the implementation. Check for external tables (Elastic queries) in each database. Also check the external data sources associated with the elastic queries. Document the elastic queries and the external data sources.
CLR Integration
CLR (Common Language Runtime) integration is available with full SQL Server installations. These are .NET database objects such as functions and stored procedures. CLR integration is enabled at a server level, but it is implemented at a database level, so I include it here. I personally don’t see many servers configured with CLR objects, but that doesn’t mean they aren’t out there. I have created and used them – they can be much faster for some operations and can extend SQL Server capabilities relatively easily. The downside of CLR integration is potential security gaps and maintenance overhead. They also consume memory on the server which can lead to instability if they are not programmed correctly.
Confirm if CLR integration is enabled and each database that has assemblies installed. You will want to know what the code is doing. It is ideal if the code is signed by your organization as it makes installations easier and ensures the source of the code. It is also ideal if the source code is available. You may not review it for your audit, but it should be readily available and meet enterprise standards.
Extended Events
Extended events were mentioned in my section covering SQL Server engine level audits. They are repeated here because they are only supported at a database level in Azure SQL databases. As with the server level extended events, it’s good to understand why the events are running and the events getting captured. Document the extended events and their configuration. This can be an indication of problem areas that admins have been examining.
Evaluating Database Environment Differences
When there are multiple environments for a project, application, or set of databases, the environments at a server and SQL Server level will generally be different. The database level items differences should be minimal or even non-existent.
Pay special attention to things like the collation, containment, and optimizations that are different between environments. It is normal to have a different backup model between production and dev, or even no backups in the lower environments, but other configuration items should be trivial. Confirm and document these items.
Gathering the Database Audit Information
Database compatibility level
Compatibility level can be checked via TSQL for both on-prem and Azure databases. The levels available by edition are listed in the Alter Database documentation in the links section at the end of this document. SELECT name ,compatibility_level FROM sys.databases
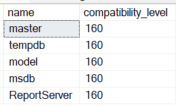
Database configuration options
The database configuration is generally less important in a cloud environment, but there are still some items that can be changed and should be verified. This also applies to a full server installation. As with the server configuration options, look for anything not configured with the default values at the database level.
|
1 2 3 |
SELECT * FROM sys.database_scoped_configurations WHERE is_value_default = 0 |
Database properties
The following shows the database properties for each database. Values can be added with each version, so be sure to check the latest documentation for new properties. This can also be used against Azure SQL Databases, but you will need to limit it to your current database if you aren’t a virtual server level admin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
DECLARE @Databases TABLE ( DatabaseName varchar(255) ) INSERT INTO @Databases ( DatabaseName ) SELECT name FROM sys.sysdatabases DB DECLARE @Properties TABLE ( PropertyName varchar(255) ) INSERT INTO @Properties ( PropertyName ) VALUES ('Collation') ,('ComparisonStyle') ,('Edition') ,('IsAnsiNullDefault') ,('IsAnsiNullsEnabled') ,('IsAnsiPaddingEnabled') ,('IsAnsiWarningsEnabled') ,('IsArithmeticAbortEnabled') ,('IsAutoClose') ,('IsAutoCreateStatistics') ,('IsAutoCreateStatisticsIncremental') ,('IsAutoShrink') ,('IsAutoUpdateStatistics') ,('IsClone') ,('IsCloseCursorsOnCommitEnabled') ,('IsFulltextEnabled') ,('IsInStandBy') ,('IsLocalCursorsDefault') ,('IsMemoryOptimizedElevateToSnapshotEnabled') ,('IsMergePublished') ,('IsNullConcat') ,('IsNumericRoundAbortEnabled') ,('IsParameterizationForced') ,('IsQuotedIdentifiersEnabled') ,('IsPublished') ,('IsRecursiveTriggersEnabled') ,('IsSubscribed') ,('IsSyncWithBackup') ,('IsTornPageDetectionEnabled') ,('IsVerifiedClone') ,('IsXTPSupported') ,('LastGoodCheckDbTime') ,('LCID') ,('MaxSizeInBytes') ,('Recovery') ,('ServiceObjective') ,('ServiceObjectiveId') ,('SQLSortOrder') ,('Status') ,('Updateability') ,('UserAccess') ,('Version') ,('ReplicaID') SELECT @@SERVERNAME ServerName ,DB.name DatabaseName ,PropertyName ,DATABASEPROPERTYEX(DB.name,PropertyName) PropertyValue FROM sys.databases DB INNER JOIN @Databases ON DB.name COLLATE Latin1_General_100_CI_AS = DatabaseName COLLATE Latin1_General_100_CI_AS CROSS JOIN @Properties |
File locations
File locations for the current database can be found with the following.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT DF.file_id ,DF.type_desc ,DF.name DatabaseFileName ,DF.physical_name ,DF.state_desc ,FG.name FileGroupName ,FG.type FileGroupType ,FG.type_desc FileGroupTypeDesc FROM sys.database_files DF LEFT JOIN sys.filegroups FG ON DF.data_space_id = FG.data_space_id |

Database level collation
Database level collation is shown with the following. It is also included in the database property script above. Don’t forget that you can also assign collation at a table and column level.
|
1 |
SELECT DATABASEPROPERTYEX(DB_NAME(),'COLLATION') |
Containment model
The following works for both on-prem servers and Azure database.
|
1 2 3 4 |
SELECT name DatabaseName ,containment_desc ContainmentDescription FROM sys.databases |
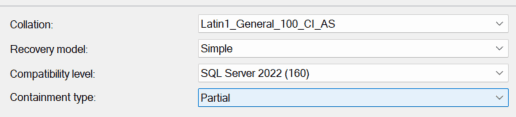
You can also use SSMS to look at the properties of the database to show this. The “Options” tab shows the Collation, Recovery Model, Compatibility level and Containment type.
Write accurate SQL faster in SSMS with SQL Prompt AI
Backup model and backups
The following shows the backup recovery model.
|
1 |
SELECT DATABASEPROPERTYEX(DB_NAME(),'Recovery') |
Database backups can be shown with the following query. This won’t work with Azure SQL.
|
1 2 3 4 5 |
SELECT * FROM msdb.dbo.backupset BS INNER JOIN msdb.dbo.backupmediafamily BMF ON BS.media_set_id = BMF.media_set_id WHERE BS.database_name = DB_NAME() |
The following works for Azure SQL databases.
|
1 2 3 |
SELECT * FROM sys.dm_database_backups ORDER BY backup_start_date DESC |
In-memory table configuration and full-text search
In-memory tables can be seen with the following query.
|
1 2 3 |
SELECT * FROM sys.tables WHERE is_memory_optimized = 1 |
Full-text indexes are shown with this query. It also shows the current crawl status.
|
1 2 |
SELECT * FROM sys.fulltext_indexes |
Elastic queries
Elastic queries are indicated by the is_external column in sys.tables.
|
1 2 3 |
SELECT * FROM sys.tables WHERE is_external = 1 |
They are also in the system view sys.external_tables.
|
1 2 |
SELECT * FROM sys.external_tables |
The data sources for each elastic query can be found in sys.external_data_sources.
|
1 2 |
SELECT * FROM sys.external_data_sources |
CLR Integration
CLR integration isn’t available in Azure SQL databases. It is available in full SQL installations on-prem and managed instances. You can see if CLR integration is enabled at the server level by checking sp_configure. EXEC sp_configure ‘clr enabled’
After it is enabled at a server level, CLR assemblies need to be installed and configured at a database level. These can be seen via sys.assemblies.
|
1 2 |
SELECT * FROM sys.assemblies |
Extended Events
Server level extended events are only available for full server installations.
|
1 2 |
SELECT * FROM sys.dm_xe_sessions |
Azure database level extended events are shown via dm_xe_database_sessions.
|
1 2 |
SELECT * FROM sys.dm_xe_database_sessions |
Summary
Database level configurations are where you will find most of your items of concern when performing a SQL Server audit. Look for differences between environments and items not using the default values. You will also want to pay special attention to file locations and the backup configuration for each database. These items alone can justify the audit and curtail potential issues in the future. Remember that consistency is a crucial. Automated deployments and configurations make this much easier. You are trying to find items that are not within enterprise standards. Items outside of the documented standards should be justified by business or project need.
Continue learning the ins and outs of SQL Server auditing with Ben
Click here for other articles in the series (and see below for this article’s references).
References
- https://learn.microsoft.com/en-us/sql/t-sql/statements/alter-database-transact-sql-compatibility-level?view=sql-server-ver16
- https://learn.microsoft.com/en-us/sql/t-sql/functions/serverproperty-transact-sql?view=sql-server-ver16
- https://learn.microsoft.com/en-us/sql/database-engine/configure-windows/configure-windows-service-accounts-and-permissions?view=sql-server-ver16
- https://learn.microsoft.com/en-us/sql/t-sql/statements/alter-database-transact-sql-compatibility-level?view=sql-server-ver16
- https://learn.microsoft.com/en-gb/azure/azure-sql/database/transact-sql-tsql-differences-sql-server?view=azuresql
- https://learn.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-external-data-sources-transact-sql?view=sql-server-ver16
- https://learn.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-external-tables-transact-sql?view=sql-server-ver16
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments