
The DOS stub at the top of the file is the first thing you notice when you open a .NET assembly in a hex editor. But what do those bytes mean, and what do they do? As I discussed in a previous post, the first 64 bytes are the DOS header, and the next 64 bytes is the stub program. What does that program do?
Real mode & DOS
All modern x86-compatible processors, right up to the latest Pentiums and Athlons, boot up into real mode, the addressing mode used in the original 8086, and the mode used in all DOS programs. In this mode, processor registers are all 16-bits long, and the currently running program is entirely responsible for the 1024kB of physical memory available to it (how times have changed…).
Memory addresses are specified by adding an offset to the (shifted) value of one of four segment registers. These specified the ‘base’ addresses of the stack, code (the program loaded into memory), and data segments within memory (the fourth segment register was an ‘extra’ that could be used as the program saw fit).
When a DOS program is run, the contents of the executable are loaded into memory, processor registers are set to values specified in the DOS header, and the bytes immediately following the header are executed on the processor.
Disassembling the DOS stub
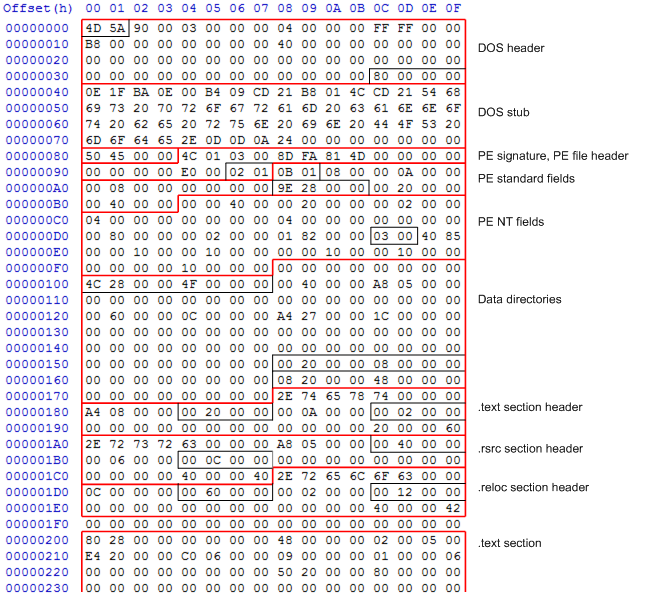
Most of the DOS header consists of the string This program cannot be run in DOS mode.rrn$. In the example .NET assembly above, this string starts at file offset 0x4E. Before that, we have the following bytes:
|
1 |
0E 1F BA 0E 00 B4 09 CD 21 B8 01 4C CD 21 |
If we run this through a disassembler, we get the following 16-bit x86 code:
|
1 2 3 4 5 6 7 |
push cs pop ds mov dx, 0xe mov ah, 0x9 int 0x21 mov ax, 0x4c01 int 0x21 |
Well, what on earth is that doing? Let’s break it down into stages.
push cspop ds
These two instructions operate on the stack available to real mode programs; thepushinstruction is essentially shorthand for ‘Copy the specified value to the location pointed to by the stack pointer and increment the pointer’, whilepopdoes the opposite.To start off with, the
csregister points to where the program code is loaded into memory. These two instructions are copying the value of thecs(code segment) register to theds(data segment) register via the stack.mov dx, 0xe
This is setting the value of thedxregister to the constant 0xe. If you have a look at the stub above, this is the offset at which the text string begins from the start of the code.mov ah, 0x9int 0x21
Let’s start off withint 0x21. This instruction invokes a software interrupt; interrupt 0x21 is the interrupt number for the DOS API (yes, such a thing exists!). Theahregister (the high byte ofax) contains the number of the API function to call.If you have a look at the list of function codes, 0x9 corresponds to ‘Write string to STDOUT’, with the string to write to pointed to by
ds:dxand terminated by$. Asdshas been set the same ascs, and the offset 0xe is indx, this prints the stringThis program cannot be run in DOS mode.rrnto the console.mov ax, 0x4c01int 0x21
This is another DOS function call. The high byte ofax, 0x4c, corresponds to the Exit function, and the low byte, 0x01, specifies the return value. So this stops execution of the program and returns to the DOS prompt, with a return value of 1.
Why is this here?
When the PE file format was introduced in Windows NT 3.1, there was a real possibility users would try to execute PE files in a DOS environment. So the existance of the DOS stub was specified in the PE file specification. When .NET 1.0 was introduced in 2002 for Windows 98, ME, NT, 2000 and XP, there was still a possibility that assemblies would be run under DOS, so the DOS stub was also specified in the CLR specification. For backwards compatibility, this stub still exists in .NET 4 assemblies.
That’s it!
There we go, nice and simple. However, the CLR loader stub, which I’ll be looking at in the next post, is significantly more complicated!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments