
Today, I’ll be starting a look at what exactly is inside a .NET assembly – how the metadata and IL is stored, how Windows knows how to load it, and what all those bytes are actually doing. First of all, we need to understand the PE file format.
PE files
.NET assemblies are built on top of the PE (Portable Executable) file format that is used for all Windows executables and dlls, which itself is built on top of the MSDOS executable file format. The reason for this is that when .NET 1 was released, it wasn’t a built-in part of the operating system like it is nowadays. Prior to Windows XP, .NET executables had to load like any other executable, had to execute native code to start the CLR to read & execute the rest of the file.
However, starting with Windows XP, the operating system loader knows natively how to deal with .NET assemblies, rendering most of this legacy code & structure unnecessary. It still is part of the spec, and so is part of every .NET assembly.
The result of this is that there are a lot of structure values in the assembly that simply aren’t meaningful in a .NET assembly, as they refer to features that aren’t needed. These are either set to zero or to certain pre-defined values, specified in the CLR spec. There are also several fields that specify the size of other datastructures in the file, which I will generally be glossing over in this initial post.
Structure of a PE file
Most of a PE file is split up into separate sections; each section stores different types of data. For instance, the .text section stores all the executable code; .rsrc stores unmanaged resources, .debug contains debugging information, and so on. Each section has a section header associated with it; this specifies whether the section is executable, read-only or read/write, whether it can be cached…
When an exe or dll is loaded, each section can be mapped into a different location in memory as the OS loader sees fit. In order to reliably address a particular location within a file, most file offsets are specified using a Relative Virtual Address (RVA). This specifies the offset from the start of each section, rather than the offset within the executable file on disk, so the various sections can be moved around in memory without breaking anything. The mapping from RVA to file offset is done using the section headers, which specify the range of RVAs which are valid within that section.
For example, if the .rsrc section header specifies that the base RVA is 0x4000, and the section starts at file offset 0xa00, then an RVA of 0x401d (offset 0x1d within the .rsrc section) corresponds to a file offset of 0xa1d. Because each section has its own base RVA, each valid RVA has a one-to-one mapping with a particular file offset.
PE headers
As I said above, most of the header information isn’t relevant to .NET assemblies. To help show what’s going on, I’ve created a diagram identifying all the various parts of the first 512 bytes of a .NET executable assembly. I’ve highlighted the relevant bytes that I will refer to in this post:
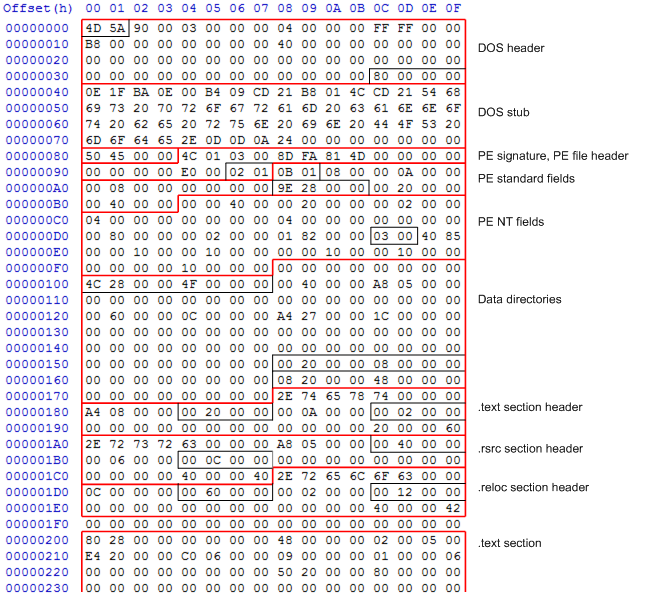
Bear in mind that all numbers are stored in the assembly in little-endian format; the hex number 0x0123 will appear as 23 01 in the diagram.
The first 64 bytes of every file is the DOS header. This starts with the magic number ‘MZ’ (0x4D, 0x5A in hex), identifying this file as an executable file of some sort (an .exe or .dll). Most of the rest of this header is zeroed out. The important part of this header is at offset 0x3C – this contains the file offset of the PE signature (0x80). Between the DOS header & PE signature is the DOS stub – this is a stub program that simply prints out ‘This program cannot be run in DOS mode.rn‘ to the console. I will be having a closer look at this stub later on.
The PE signature starts at offset 0x80, with the magic number ‘PE’ (0x50, 0x45, 0x00, 0x00), identifying this file as a PE executable, followed by the PE file header (also known as the COFF header). The relevant field in this header is in the last two bytes, and it specifies whether the file is an executable or a dll; bit 0x2000 is set for a dll.
Next up is the PE standard fields, which start with a magic number of 0x010b for x86 and AnyCPU assemblies, and 0x20b for x64 assemblies. Most of the rest of the fields are to do with the CLR loader stub, which I will be covering in a later post.
After the PE standard fields comes the NT-specific fields; again, most of these are not relevant for .NET assemblies. The one that is is the highlighted Subsystem field, and specifies if this is a GUI or console app – 0x2 for a GUI app, 0x3 for a console app.
Data directories & section headers
After the PE and COFF headers come the data directories; each directory specifies the RVA (first 4 bytes) and size (next 4 bytes) of various important parts of the executable. The only relevant ones are the 2nd (Import table), 13th (Import Address table), and 15th (CLI header). The Import and Import Address table are only used by the startup stub, so we will look at those later on. The 15th points to the CLI header, where the CLR-specific metadata begins.
After the data directories comes the section headers; one for each section in the file. Each header starts with the section’s ASCII name, null-padded to 8 bytes. Again, most of each header is irrelevant, but I’ve highlighted the base RVA and file offset in each header. In the diagram, you can see the following sections:
.text: base RVA 0x2000, file offset 0x200.rsrc: base RVA 0x4000, file offset 0xc00.reloc: base RVA 0x6000, file offset 0x1200
The .text section contains all the CLR metadata and code, and so is by far the largest in .NET assemblies. The .rsrc section contains the data you see in the Details page in the right-click file properties page, but is otherwise unused. The .reloc section contains address relocations, which we will look at when we study the CLR startup stub.
What about the CLR?
As you can see, most of the first 512 bytes of an assembly are largely irrelevant to the CLR, and only a few bytes specify needed things like the bitness (AnyCPU/x86 or x64), whether this is an exe or dll, and the type of app this is. There are some bytes that I haven’t covered that affect the layout of the file (eg. the file alignment, which determines where in a file each section can start). These values are pretty much constant in most .NET assemblies, and don’t affect the CLR data directly.
Conclusion
To summarize, the important data in the first 512 bytes of a file is:
- DOS header. This contains a pointer to the PE signature.
- DOS stub, which we’ll be looking at in a later post.
- PE signature
- PE file header (aka COFF header). This specifies whether the file is an exe or a dll.
- PE standard fields. This specifies whether the file is AnyCPU/32bit or 64bit.
- PE NT-specific fields. This specifies what type of app this is, if it is an app.
- Data directories. The 15th entry (at offset 0x168) contains the RVA and size of the CLI header inside the
.textsection. - Section headers. These are used to map between RVA and file offset. The important one is
.text, which is where all the CLR data is stored.
In my next post, we’ll start looking at the metadata used by the CLR directly, which is all inside the .text section.
Load comments