
Any close look at the method definitions in a .NET assembly has to start off with the method’s information in the metadata tables – the MethodDef. So lets do that.
MethodDef
The MethodDef entry for the entrypoint method in my TinyAssembly example used in previous posts has the following bytes:
|
1 |
D0 20 00 00 00 00 91 00 47 00 0A 00 01 00 |
According to the CLR spec, the row is interpreted as follows:
D0 20 00 00: RVA. The RVA of the method body within the assembly (0x20d0).00 00: ImplFlags. Various flags indicating how the method is implemented. All-zeros indicate this is a pure-IL managed method.91 00: Flags. In this example, these flags indicate this method is declaredprivate static hidebysig.47 00: Name. offset into#Stringsheap (‘Main’).0A 00: Signature. Offset into#Blobheap containing the signature (return type & parameter types) of the method. I might look at signature encodings in a later post. In this example, the bytes at this offset indicate a method with no parameters and avoidreturn type.01 00: ParamList. A RID to theParamDeftable with information on the method’s parameters. As this method has no parameters, and there is noParamDeftable in the assembly, this is essentially ignored.
You’ll notice there’s no reference to the owning TypeDef within a MethodDef. In an assembly, associations like this are one-way – in order to find which type owns a particular method, you have to scan the TypeDef table until you find a type that includes the method in its method list.
Method bodies
So, a MethodDef describes the basic properties of a method – its name, signature, and implementation details. What about the actual body of a method?
Within the assembly, these are all located between the CLI header/strong name hash and the CLR metadata, as you can see:
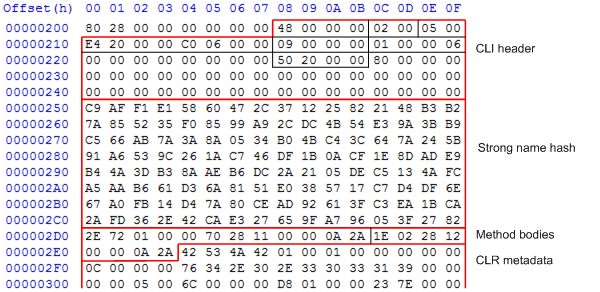
The RVA within a MethodDef tells us where the method body can be found. In this case, the RVA is 0x20d0, so the method body comprises the following bytes:
|
1 |
2E 72 01 00 00 70 28 11 00 00 0A 2A |
How are these bytes interpreted? To start with, we have to understand a bit about CIL opcodes.
Instruction encoding
CIL uses a variable-length instruction encoding; each opcode can be represented by 1 or 2 bytes, with all the commonly-used instructions using 1 byte. After the opcode are bytes representing the argument to that instruction, if there is one.
There are usually two versions of instructions that take an argument, a short version and a long version. For example, the ldarg instruction (load argument) is a 2-byte instruction that takes a 2-byte argument with the argument number to be loaded. However, very few methods are going to have argument lists with more than about 10 arguments, so the ldarg.s 1-byte instruction takes a single byte with the argument number. And, in fact, IL takes this a step further, as there are separate ldarg.0, ldarg.1, ldarg.2 and ldarg.3 instructions to load the first 4 method arguments in only 1 byte.
If we compare the 3 different instructions encodings, we can see what difference in bytes this can do:
ldarg 1FE 09 01 00ldarg.s 10E 01ldarg.103
Since ldarg.1 is likely to be used many, many times within an assembly, this saves a lot of space.
Within the instruction stream, metadata items are all referenced using a 4-byte token, with the table number in the most significant byte and the RID in the other 3 bytes. For example, the IL instruction
|
1 |
callvirt instance string [mscorlib]System.Object::ToString() |
could get compiled to
|
1 |
6F 05 00 00 0A |
0x6f is the encoding for the callvirt instruction, and the token argument is pointing to the 5th row of the MemberRef table (table number 0x0a), which will have the name and signature of the Object.ToString() method.
Method headers
Again, there’s a header at the start of the method body. And, in a similar way to the instruction encoding, there are two formats for the header depending on what needs to be specified, a thin format and a fat format. The first two bits of the first byte specify which header this is.
The thin format header takes up a single byte, and is used when a method:
- has no local variables
- has no exception handling blocks
- never has more than 8 items on the stack
- has a method body shorter than 63 bytes (not including the header)
If any of these do not apply, then the fat header needs to be used, which is 12 bytes long. This header specifies the maximum number of items on the stack, a token to the locals signature in the StandAloneSig metadata table, and a flag indicating if there are exception handling tables after the method body.
Thin headers are typically used for simple property getter & setters, which usually do no more than a load field & return or load argument & store field.
Decoding method bodies
We can now decode the method body mentioned above. To recap, the bytes are:
|
1 |
2E 72 01 00 00 70 28 11 00 00 0A 2A |
So, in order:
2E
This is the method header. The bits are:The least significant bits are122 E0010 111010, indicating this is a thin method header. The remainder of the bits gives us the size of the method body – 11 bytes (1011)72 01 00 00 70ldstr "Hello World"
0x72 is the opcode for theldstrinstruction, and the argument is a 4-byte token. However, this is no ordinary token; the table number is 0x70, which does not refer to any of the metadata tables. In a method body, a token with a table of 0x70 is actually referring to the#USmetadata heap, and the RID is actually the zero-based offset within that heap. So this refers to the item in the#USheap starting at offset 1 – the string “Hello World”28 11 00 00 0Acall void [mscorlib]System.Console::WriteLine(string)
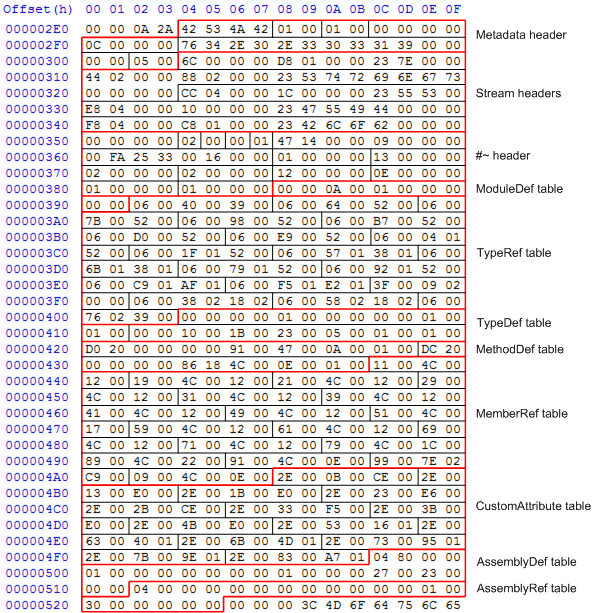
0x28 is the opcode for thecallinstruction, again with a 4-byte token argument. This is a normal token, and refers to the 17th entry in theMemberReftable. If we have a look back at the metadata tables the 17th row in theMemberReftable has the bytes99 00 7E 02 C9 00. This points to theTypeRefforSystem.Console, “WriteLine” in the#Stringsheap, and the method signaturevoid(string). This is everything the CLR needs to know to work out which method to call.2Aret
0x2a is the opcode for theretinstruction, which takes no arguments.
{kind=link}
As you can see, this is actually a very simple “Hello World” program.
Conclusion
I hope this series of posts has given you an insight into how data is actually stored in a .NET assembly. Please do comment or email me if there’s anything you want me to have a look at in more detail. That’s not the end of the series; the next few posts will have a look at the DOS and CLR loader stubs that are part of every assembly – why they are there, and what they do.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments