
To recap from my previous posts, .NET assemblies are built on top of the PE file format, which is used for all executables and dlls in Windows. The PE file is split up into sections, and the data read by the CLR is all inside the .text section. Inside that section, the CLR data starts with a CLI header, followed by the strong name hash and the method bodies.
Right after the method bodies comes the CLR metadata, which is itself split up into streams. The metadata itself if stored in tables within the #~ stream; binary arrays of structures representing different aspects of the assembly.
At the top of the #~ stream is a header with the rowcounts of each table present in the assembly; these are used to determine if RIDs and tokens referencing those tables use 2 or 4 bytes of storage.
CLR metadata
Now we’ll look at the actual bytes comprising the metadata header & #~ stream. Here’s a diagram showing the bytes comprising the CLR metadata (click for an expanded version):
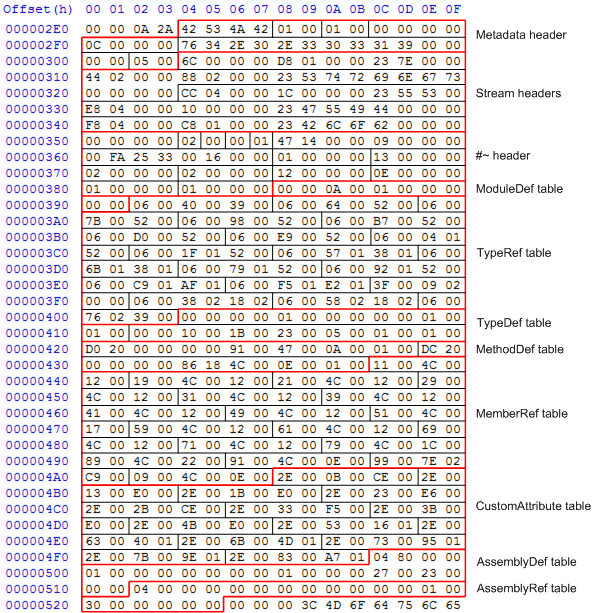
As with most structures, the CLR metadata starts off with a header. This starts with a magic number of 0x424a5342, then the major and minor version numbers of the CLR metadata (currently 1.1). The next 4 bytes are reserved (no doubt the CLR team has exciting plans for those bytes), then the length and ASCII of the CLR version string, null-padded to a 4 byte boundary. This is the string that determines which version of the CLR this assembly runs under, so for .NET 2.0, 3.0 and 3.5 this string is “v2.0.50727” (as the CLR version didn’t change for 3.0 or 3.5), and for 4.0 it is “v4.0.30319”. The next two bytes are again reserved, followed by the number of streams in the metadata.
Stream headers
The stream headers are analogous to the section headers in the PE structure. They give the offset, size and name of each stream in the metadata. Note, however, that the offset given is relative to the start of the metadata header. For example, the first stream header is for the #~ stream, and has the following information:
- Offset: 0x6c
- Size: 0x01d8
- Name: 0x23 0x7e (#~)
In this assembly, the metadata header starts at file offset 0x2e4. This means that the #~ stream starts at offset 0x2e4 + 0x6c = 0x350, and stops at offset 0x350 + 0x1d8 = 0x528.
The #~ header
The #~ header comes straight after the stream headers, at the top of the #~ stream. This is the header containing all the information on the size of RIDs and offsets within the metadata tables, as discussed in the previous post.
The header starts off with 4 reserved bytes (more exciting plans on the horizon?), then the major and minor numbers indicating the layout of the tables; this is unchanged from .NET 2, where generics were added. After that is a single byte indicating whether heap offsets within the table use 2 or 4 bytes – bit 1 for #Strings, bit 2 for #GUID, bit 3 for #Blob. As this byte is zero, all the heap offsets in the tables use 2 bytes. The next byte is again reserved, and is always set as 1.
The next 8 bytes is a bit vector indicating which tables are actually present in the stream – although a table may be defined in the CLR spec, it doesn’t have to be present in an assembly if it isn’t needed. For example, the assembly has no generic types or instantiations in it, so the MethodSpec, TypeSpec, GenericParam and GenericParamConstraint tables will all be missing.
If we have a look at this bit vector, it has the value 0x900001447. The bits that make up this number are:
|
1 |
9 0 0 0 0 1 4 4 71001 0000 0000 0000 0000 0001 0100 0100 0111 |
Counting from the right, this tells us that the following tables are present in the metadata:
0x0: ModuleDef0x1: TypeRef0x2: TypeDef0x6: MethodDef0xa: MemberRef0xc: CustomAttribute0x20: AssemblyDef0x23: AssemblyRef
The next 8 bytes are also a bitvector, but these indicate which tables are sorted. As most of the tables in a compiled .NET assembly are sorted, we can ignore this for now (we might come back to it in a later post).
Following the two bitvectors are a series of uint32 values specifying the rowcounts of all the tables present in the metadata, ordered by their table number:
ModuleDef: 1TypeRef: 19TypeDef: 2MethodDef: 2MemberRef: 18CustomAttribute: 14AssemblyDef: 1AssemblyRef: 1
As you can see, this is a very small assembly, with 2 types, 2 methods, and no fields. Furthermore, as all rowcounts are nowhere near 65535, all the RIDs and coded tokens used in the tables will be 2 bytes rather than 4.
Interpreting the table data
Right after the metadata stream header comes the table data itself, again ordered by the table number. The contents of each table row are defined in the CLR spec, and interpreted according to the field lengths given in the CLR metadata. If we have a look at the second TypeDef entry (the first is the pseudo-class <Module>), we’ve got the following bytes:
|
1 |
00 00 01 00 1B 00 23 00 05 00 01 00 01 00 |
Every RID, coded token and offset in the assembly is specified using two bytes, so these bytes are interpreted as follows:
00 00 01 00: Flags. The single bit set indicates theBeforeFieldInitproperty on the type.1B 00: Name. Offset into#Stringsheap (‘Program’).23 00: Namespace. Offset into#Stringsheap (‘TinyAssembly’).05 00: Extends. Coded token of typeTypeDefOrRef. Interpreted as:the two rightmost bits specifies the10000 0101TypeReftable, the bits left over give the row index within that table. So this coded token refers to the first row of theTypeReftable.01 00: FieldList. First row of theFieldDeftable. As there is noFieldDeftable in this assembly, this type does not have any fields.01 00: MethodList. First row of theMethodDeftable. As this is the lastTypeDefin the table, the type’s methods include everything from this RID to the end of the table.
Heap data
Straight after the #~ stream comes the 4 heaps – #Strings, #US, #GUID and #Blob. The contents of these aren’t that interesting by themselves, but we’ll be referencing them when we look at the MethodDef table and method bodies in the next post.
Conclusion
The CLR spec gives details on the contents and interpretation of every table row in the metadata, and the #~ header at the top of the #~ stream gives us enough information to work out which bytes correspond to which table rows, and what each row represents.
Next time, I’ll have a look at how the contents of methods are referenced and defined.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments