
Before we look at the bytes comprising the CLR-specific data inside an assembly, we first need to understand the logical format of the metadata (For this post I only be looking at simple pure-IL assemblies; mixed-mode assemblies & other things complicates things quite a bit).
Metadata streams
Most of the CLR-specific data inside an assembly is inside one of 5 streams, which are analogous to the sections in a PE file. The name of each section in a PE file starts with a ., and the name of each stream in the CLR metadata starts with a #.
All but one of the streams are heaps, which store unstructured binary data. The predefined streams are:
#~
Also called the metadata stream, this stream stores all the information on the types, methods, fields, properties and events in the assembly. Unlike the other streams, the metadata stream has predefined contents & structure.#Strings
This heap is where all the namespace, type & member names are stored. It is referenced extensively from the#~stream, as we’ll be looking at later.#US
Also known as the user string heap, this stream stores all the strings used in code directly. All the strings you embed in your source code end up in here. This stream is only referenced from method bodies.#GUID
This heap exclusively stores GUIDs used throughout the assembly.#Blob
This heap is for storing pure binary data – method signatures, generic instantiations, that sort of thing.
Items inside the heaps are indexed using a simple binary offset from the start of the heap. For the binary heaps (#US and #Blob) that offset is a coded integer giving the length of that item, then the item’s bytes immediately follow. The #GUID heap doesn’t require a length for each item, in that GUIDs are all 16 bytes long; the offset simply points at each GUID. Each item in the #Strings heap simply reads from the offset to the first null character.
Metadata tables
The #~ stream contains all the assembly metadata. The metadata is organised into 45 tables, which are binary arrays of predefined structures containing information on various aspects of the metadata. Each entry in a table is called a row, and the rows are simply concatentated together in the file on disk. For example, each row in the TypeRef table contains:
- A reference to where the type is defined (most of the time, a row in the
AssemblyReftable). - An offset into the
#Stringsheap with the name of the type - An offset into the
#Stringsheap with the namespace of the type.
in that order.
The important tables are (with their table number in hex):
- 0x2:
TypeDef - 0x4:
FieldDef - 0x6:
MethodDef - 0x14:
EventDef - 0x17:
PropertyDef
Contains basic information on all the types, fields, methods, events and properties defined in the assembly. - 0x1:
TypeRef
The details of all the referenced types defined in other assemblies. - 0xa:
MemberRef
The details of all the referenced members of types defined in other assemblies. - 0x9:
InterfaceImpl
Links the types defined in the assembly with the interfaces that type implements. - 0xc:
CustomAttribute
Contains information on all the attributes applied to elements in this assembly, from method parameters to the assembly itself. - 0x18:
MethodSemantics
Links properties and events with the methods that comprise the get/set or add/remove methods of the property or method. - 0x1b:
TypeSpec - 0x2b:
MethodSpec
These tables provide instantiations of generic types and methods for each usage within the assembly.
There are several ways to reference a single row within a table. The simplest is to simply specify the 1-based row index (RID). The indexes are 1-based so a value of 0 can represent ‘null’. In this case, which table the row index refers to is inferred from the context.
If the table can’t be determined from the context, then a particular row is specified using a token. This is a 4-byte value with the most significant byte specifying the table, and the other 3 specifying the 1-based RID within that table. This is generally how a metadata table row is referenced from the instruction stream in method bodies.
The third way is to use a coded token, which we will look at in the next post.
So, back to the bytes
Now we’ve got a rough idea of how the metadata is logically arranged, we can now look at the bytes comprising the start of the CLR data within an assembly:
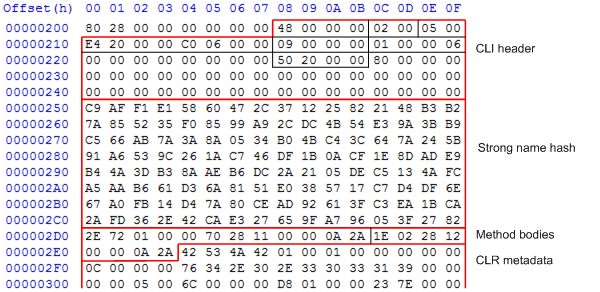
The first 8 bytes of the .text section are used by the CLR loader stub. After that, the CLR-specific data starts with the CLI header. I’ve highlighted the important bytes in the diagram. In order, they are:
- The size of the header. As the header is a fixed size, this is always 0x48.
- The CLR major version. This is always 2, even for .NET 4 assemblies.
- The CLR minor version. This is always 5, even for .NET 4 assemblies, and seems to be ignored by the runtime.
- The RVA and size of the metadata header. In the diagram, the RVA 0x20e4 corresponds to the file offset 0x2e4
- Various flags specifying if this assembly is pure-IL, whether it is strong name signed, and whether it should be run as 32-bit (this is how the CLR differentiates between x86 and AnyCPU assemblies).
- A token pointing to the entrypoint of the assembly. In this case,
06(the last byte) refers to theMethodDeftable, and01 00 00refers to to the first row in that table. - (after a gap) RVA of the strong name signature hash, which comes straight after the CLI header. The RVA 0x2050 corresponds to file offset 0x250.
The rest of the CLI header is mainly used in mixed-mode assemblies, and so is zeroed in this pure-IL assembly.
After the CLI header comes the strong name hash, which is a SHA-1 hash of the assembly using the strong name key.
After that comes the bodies of all the methods in the assembly concatentated together. Each method body starts off with a header, which I’ll be looking at later. As you can see, this is a very small assembly with only 2 methods (an instance constructor and a Main method).
After that, near the end of the .text section, comes the metadata, containing a metadata header and the 5 streams discussed above. We’ll be looking at this in the next post.
Conclusion
The CLI header data doesn’t have much to it, but we’ve covered some concepts that will be important in later posts – the logical structure of the CLR metadata and the overall layout of CLR data within the .text section.
Next, I’ll have a look at the contents of the #~ stream, and how the table data is arranged on disk.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments