
Dataflows Gen 2 are the new version of Power BI dataflows. There are so many changes in relation to the previous version they are considered a new feature.
The main difference is the possibility to set a target for the result of each query in the dataflow. In this way, it can be used as an ingestion tool to lakehouses and warehouses.
Let’s talk about some additional secrets of this tool.
1 – Azure Blob Connector vs Parquet Connector
If you need to read Parquet files stored in an Azure blob storage, which connector is the best option? The blob connector, or the Parquet connector?
Azure Blob Connector: Will list the files of an Azure blob container.
This connector only accepts as a starting connection the address of the container. If you include any path or file information, you receive an error complaining about URL parameters. Yes, it’s a terrible error message.
For example, if you consider the address https://azuresynapsestorage.blob.core.windows.net/sampledata/NYCTaxiLocations/ , this connector accepts https://azuresynapsestorage.blob.core.windows.net/sampledata and list the contents of the container, if you have permission. However, the entire address will generate an error.
This is a good choice to loop through files and folders, but besides that, it may not be the correct choice.
If you don’t have access to the root of the container, it becomes impossible to use it to load files.
Parquet Connector: This connector loads a single parquet file from the URL you use. However, it’s not capable to load an entire folder with parquet files.
In Summary: One connector can list the files, but not load them, and another can load file by file. 3 years ago, I wrote a blog explaining how Power BI Desktop can read parquet files . It builds a script in M to load the data. This was already bad. On the dataflow gen 2, you need to build the script, because it doesn’t build for you.
2 – Dataflow Staging
When we create a dataflow gen 2, a lakehouse and a data warehouse are created in the same workspace. These are special lakehouses and data warehouses, we should never touch them.
By default, every query has its data always loaded to staging and the transformations are done in the staging lakehouse.
There are some situations when we wouldn’t like to be using the staging:
- When the entire processing uses query folding. The processing will be done on the source server and has no need for the staging.
- When the data is of a reasonable size and the processing can be entirely done in memory
The staging affects a lot the performance of the ETL. Disabling it, when possible, will make the processing faster.
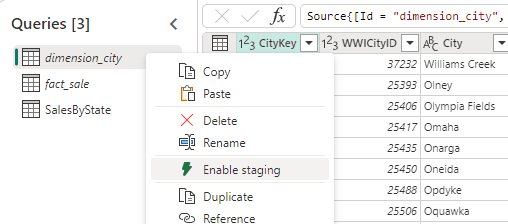
Disabling the staging is simple: Right-click the table and click the Enable Staging option in the context menu
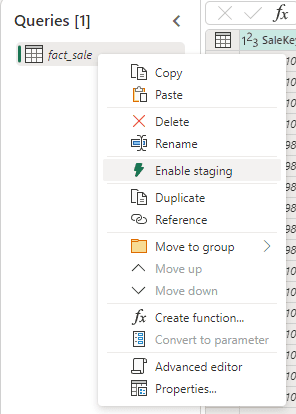
Of course, if you disable the staging on an ETL which would need it, the performance will get worse. It’s a matter of testing.
3- Dataflow Compute
It’s interesting to notice the staging is done only with the special lakehouse created for it. The special data warehouse has another purpose: Execute what is called compute operation.
When your resulting table appears with a lightning sign, this means this table needs computing. It will be processed using not only the staging, but also the compute area.
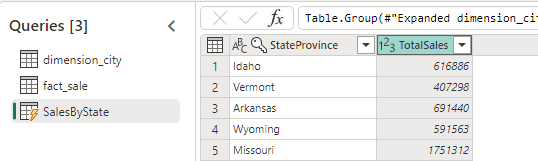
If you can avoid dynamic tables requiring compute, this will improve the ETL performance.
You can avoid the compute requirement in a similar way as you usually did on the old dataflows: “disabling the load”. The only difference is that instead of “load”, we call it “staging”.
Considering the example above, the middle tables, dimension_city and fact_sale, can have the staging disabled. This will make the table SalesByState avoid the compute stage.
This “reduced one level” on the SalesByState table. Instead of using compute, it will now use staging, because the first two tables are processed in memory.
There are some additional options:
- We can also disable staging on SalesByState and process everything in memory.
- We can disable staging only on SalesByState but not on the other two. The other two tables would still use staging, but the SalesByState would be processed in memory.
4- Data Warehouse Destination Requires Staging
At the moment I’m writing, dataflows gen 2 require staging when using data warehouse as destination. On the other hand, if you choose a lakehouse destination, the staging will not be needed.

Unfortunately, this means the same processing will execute faster if the destination is a lakehouse than a data warehouse
5- Workspace to Storage the Dataflow
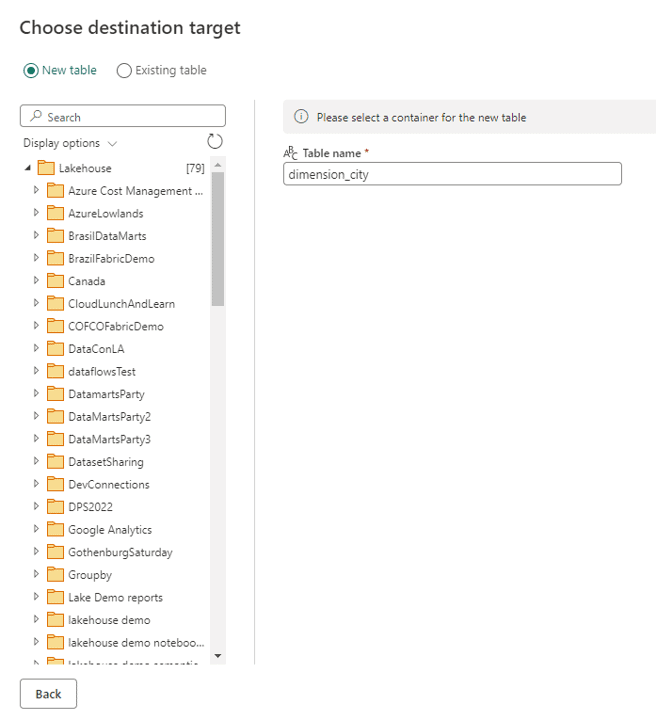
If the dataflow uses a Lakehouse as destination, we can have a workspace only for them, what is a good practice. I mentioned this on Fabric Monday 9.
Using a lakehouse as destination, we can choose the lakehouse from any accessible workspace.
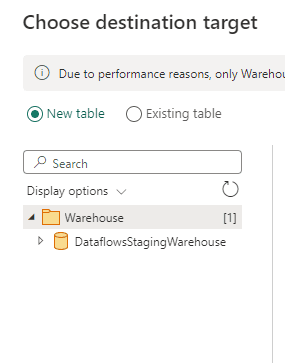
However, when the destination is a data warehouse, both needs to be saved in the same workspace. This is an additional limitation of using a Data Warehouse as destination of a Data Flow Gen 2.





Load comments