
Agile Software development techniques results in fast and frequent development cycles in which the pressure mounts on us, the Test Engineers, to be able to “cover” an area of functionality quickly and in depth. As a result, we need testing techniques that promote comprehension of the system under test (SUT), break the back of the combinatorial explosion of test cases, and adhere to the Agile testing mantra of “automate, automate, automate“.
In my day-to-day testing, I’ve adopted Model Based Testing (MBT), a technique that combines graph theory and code writing to help the Test Engineer keep pace with frequently changing functionality. It allows us to:
- Generate models that describe the SUT in terms, for example, of its behavior, or structure
- Generate test cases automatically, based on our models
- Dynamically execute the test cases against the SUT
- Increase understanding of the SUT and improve the chances of finding bugs early, reducing development costs
This article aims to raise awareness of this technique, offers a brief overview of how MBT works, provides advice on how to generate models, based on user stories, or on application behavior, and how to turn models into tests that run overnight.
How MBT Works
Model Based testing is a form of Model Based design, a way of visualizing a complex system to aid the design of a new system or the comprehension of an existing one. There are two modeling approaches:
- Structural modeling examines the entities that make up a system and the relationships that exist between those entities.
- Behavioral modeling analyzes the control flow, data flow or state transition characteristics of a system, in response to different types of input
This article focuses on the State Transition mode of behavioral modeling. In this approach, we build a formal description, or abstract model, to describe the values or states of the system at a given point in time, and the inputs into the system that cause the states to change.
This model can provide visual feedback about the system, which might not otherwise have been obvious, from the model description. In a process called exploration, we can use the model to examine the possible paths through the system to identify states that might not be reachable (dead states) and identify specific paths that form the basis of test cases.
When developing a new system, we can derive the model from user stories, which is a valuable exercise as it helps validate the specification and irons out any ambiguities before the developers write the functionality. Alternatively, we can use a manual testing strategy, such as exploratory testing, to interrogate an existing piece of software, establish how it behaves and then model this behavior, for regression testing purposes.
In either case, the user can choose to execute the tests, manually or otherwise, in a process called Conformance testing, which validates the software against this formal description. This is made possible by means of an adapter layer, which fits between the model and the product to be tested.
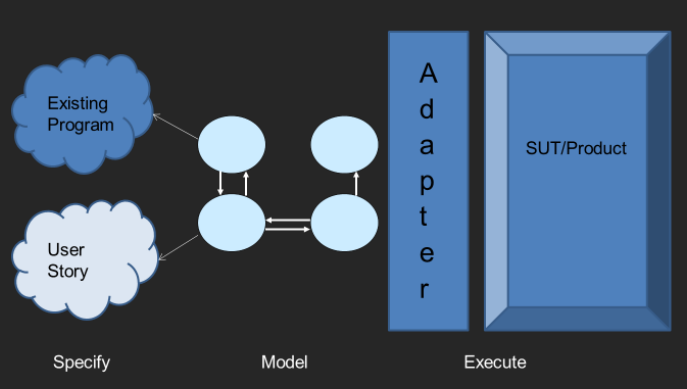
Figure 1: Model Based Testing: the big picture
A Simple Example of a State Transition Model
As a simple example, let’s consider a Red Gate product installer, which sits on my hard disk as an executable. It is in a “non-running” state until the user double clicks it, at which point the state changes to “running” and the user arrives on page 1 of the Wizard. Clicking ‘Next’ takes the user to Page 2 of the Wizard and therefore into a new “running” state. From here, the user can click ‘Cancel’, returning the system to a “non-running state”, or click ‘Next’ to transition the system to a third “running” state.
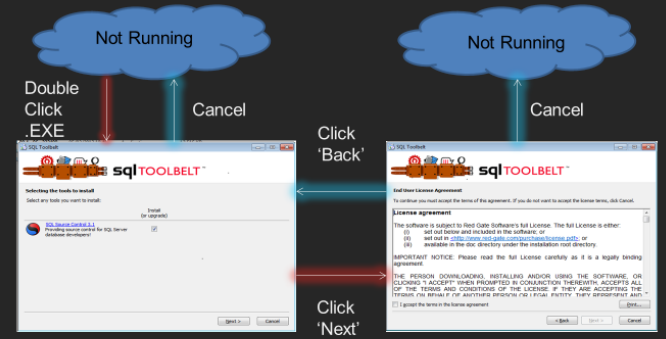
Figure 2: Modeling the behaviors of the RG Installer
Based on predicted user behavior, and associated state transitions, we can generate the formal State Transition diagram or graph.
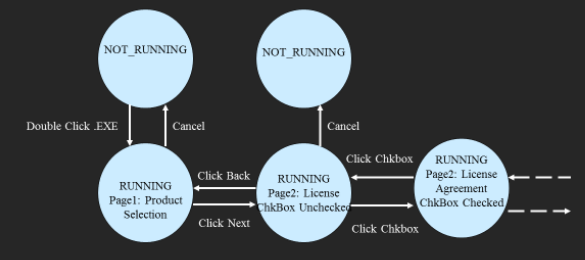
Figure 3: State Transition Model to describe behavior of the RG Installer
This discrete mathematical world is of great interest to us as we have the ability to explore this graph using algorithms and extract paths through the graph, which then form the basis for test cases that we can execute against the real product.
Developing Models
This is all very abstract so far, so how do we create this model? There are various approaches, but I’ve been using NModel, a lightweight, open source framework and toolset from Microsoft Research, which allows me to create the model by writing C# code.
What’s nice about having the model written in C# is if the functionality changes, for whatever reason, I update the model by changing lines of code and regenerate the corresponding test cases. This is much quicker than editing a multi-line manual test script.
In our C# code, we create state variables, which represent the different states of the system. In this example, we have the WizardPage enum, representing the different pages of the installer Wizard, and the state variable called Page.
We evaluate conditions (called enabling conditions) on the state variables. If the result of an evaluation is ‘true’, NModel will execute the associated Action code. For example, in the code example below we have an enabling condition called CancelFromPage1Enabled. If it evaluates to true then the associated Action, CancelFromPage1 executes and the Wizard will exit and return to a non-running state. If it evaluates to false, the wizard continues to display Page 1.
In other words, the enabling conditions control the selected Actions and therefore describe the states that are possible from that point. The role of the Action methods (those annotated with the Action attribute) is to update the state variables so further test exploration is possible.
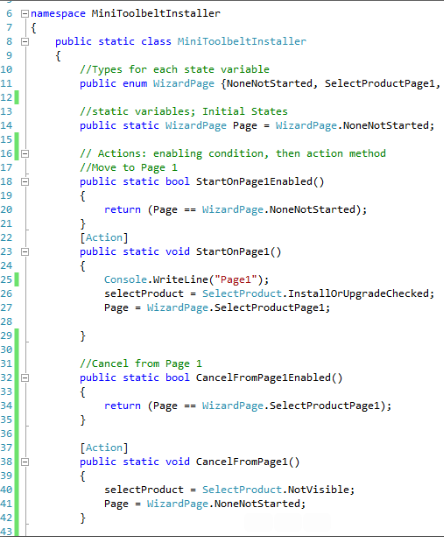
Figure 4: Developing Models in C#
NModel provides various tools, all of which consume our Model Program, i.e. the C# program written in this fashion. For example:
- mpv tool – visualize the model program graphically
- otg tool – generate test cases offline
- ct tool – verify that the system under test conforms to the model
These tools also support a textual notation, which we can extract from the model, for describing the test cases. The grammar of this notation consists of the Action names used in the model. This is a primitive form of Domain Specific Language and can be used to construct test cases in a text editor and store them on disk to be executed against the software at a later time.
MBT Challenges
One of my main concerns when I started Model Based Testing concerned the manageability of the models, particularly for software with inherent complexity. Models can become quite large and unwieldy meaning that the C# Model Program becomes complex in itself, and the number of transitions and states is huge.
The best way to manage this problem is to adhere to some basic modeling rules:
- Choose a goal for the model describing exactly what you want to achieve
- Write out or sketch some of the basic cases that the model will cover
- Use an appropriate level of abstraction to manage the level of detail and consequently the number of states that will be available.
In my example model, I was interested only in the navigation of the installer wizard, how a user progressed from one page to the next or back, or canceled. By design, the model omits any details concerning the state of controls outside of this remit.
NModel also helps manage the complexity problem by providing excellent support for merging models. I can concentrate my efforts on producing models for separate areas of functionality, which are easier to manage, but I can also merge models to extract end to end test cases.
MBT Pay-off
So how useful has MBT been? Well, firstly it’s not without its challenges and I would strongly recommend following the model writing process that I described. That said my first attempts produced some good results. While working on the SQL Source Control product the first model I wrote which took approximately 2 hours to write found 2 product issues, 3 issues with the Product API and 1 API anomaly.
Encouraged, I integrated the tests into the team’s automated test suite, so they can provide feedback whenever we build the product. The build system uses JetBrain’s Team City and NUnit, so I had to find a practical way of translating NModel tests into this world. My solution was to build a NUnit TestCaseSource, which deserializes an NModel test case from a static text file and offers the Test Case fixture, one test at a time. Within the Test Case fixture code, we wrap within an NUnit assert a call to the ct tool to execute the test case, and report a NUnit ‘pass’ or ‘fail’.
Since gaining practical use of this technique, I’ve been educating our teams at Red Gate with a view to getting more people using it. Some interesting ideas have arisen from discussions and presentations on this topic, including the possibility of running two sets of tests from the same model; one that executes the same tests repeatedly, and another set that randomly walks the graph, automatically searching for bugs. Watch this space!
Summary
In 11 years of Software Testing I have been in search of a technique that is flexible, powerful and involves code writing which I love doing. Model Based testing is one such example. I’d recommend learning the science through NModel as the book Model Based Testing and Analysis from Microsoft Press describes this in great detail. I’d also recommend the more evolved Spec Explorer 2010 also from Microsoft, a toolset that really gives me the feeling that I am testing in the 21st Century.
Load comments