Baselining a SQL Change Automation project from an existing database
This article show how to create a 'baseline' for your Visual Studio SQL Change Automation project, from an existing, target SQL Server database, so that the team can start making changes and easily deploy them to the target database.
Deploying schema changes to SQL Server databases can be tricky when you’d like to automate parts of your workflow. For instance, how do you go about version controlling your schema changes? In application development there are many tools you could use such as Git, or Subversion. However, there exists no obvious choice for SQL Server database development.
That’s where SQL Change Automation (SCA) can be useful. Designed to slot into existing workflows, SCA allows you to keep track of schema changes by representing each change as a T-SQL script, known as a migration script. By running these migration scripts in order, you can version your database schema.
Importantly, MSBuild for Visual Studio can then be used to turn the scripts into a deployment package which can be executed on any database. This gives you confidence that deployments across environments will be uniform.
When creating a new SCA project, the schema of your production environment can also be imported as a baseline. Further work can be built on top of the baseline in a sandbox development environment and, when you’re happy with the changes, the project can be deployed to production.
Baselining the production database is an essential part of integrating SCA into your workflow, so we wanted to make it as simple and intuitive as possible. As David Simner, Technical Lead on SCA explains: “We wanted users to get all the way to deploying to production with SCA without reading the docs – the SCA baseline wizard makes it straightforward.”
Importing a baseline schema with the new wizard
The new wizard walks users through the process of creating a project baseline from an existing database in several easy to follow steps:
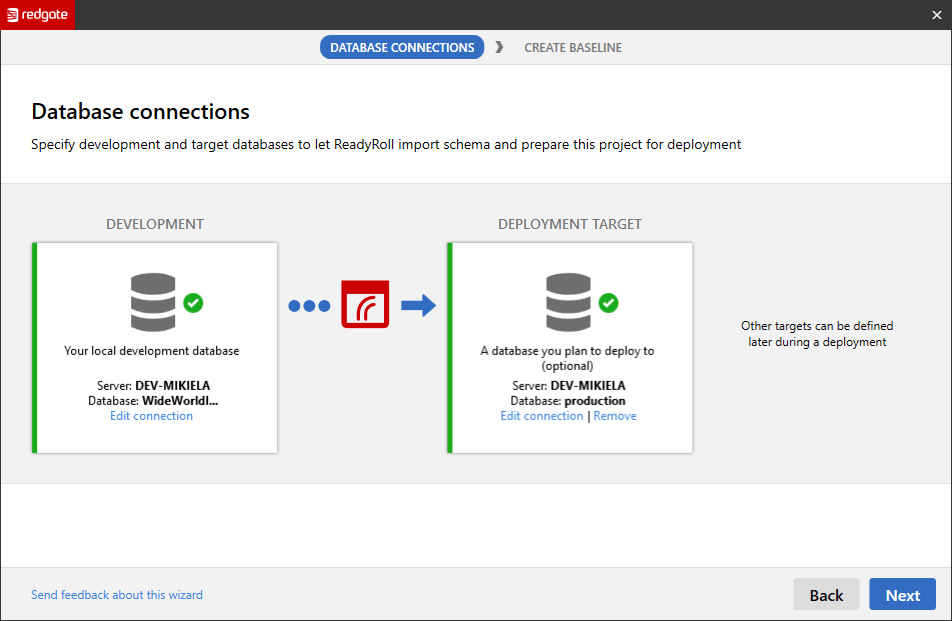
Firstly, it prompts users to specify the location of the sandbox development database and deployment target, and then provides a quick overview of the baseline process. Creating the schema baseline is just a matter of clicking the Create baseline button.
SCA automatically generates a migration script which represents the current schema on the deployment target – the baseline schema. Two folders are also generated, 1.0.0-Baseline and 1.1.0-Changes. The baseline schema migration script is automatically placed in the 1.0.0-Baseline folder, and the baseline schema can be deployed to your sandbox development environment by clicking Deploy project. You can then make changes on your development environment, which will be placed in 1.1.0-Changes.
This whole process takes less than a minute, and all necessary concepts are introduced and explained without being overwhelming. Before, you would have had to follow a lengthy documentation page to configure SCA correctly to handle a project baseline. With the wizard all of the configuration is done for you.
Alongside the project baseline functionality, the wizard offers a host of smaller enhancements to the general experience of setting up a new SCA project. For instance, we’ve improved the way database connections are validated. In the old setup UI, invalid database connections would trigger a large error dialog to replace the entire interface. Now SCA checks database connections when they’re specified, and displays information in context without breaking the flow of the setup experience.
Note to advanced users
If you’re an experienced SCA user, you’ll be aware of the concepts of Semantic Versioning, Offline Schema Model, and Programmable Objects. The new wizard turns on both Semantic Versioning and Offline Schema Model automatically. You will be prompted to enabled Programmable Objects later on in the process. This is the way that we recommend a SCA project should be set up.
Conclusion
The SQL Change Automation baseline wizard makes setting up a project relatively easy and allows you to include SQL Change Automation in your existing workflow by simply importing your production database schema to a sandbox development environment.
SQL Change Automation is a capability of the SQL Toolbelt, the suite of industry-standard database development tools that make you more productive, your team agile, and your data safe.
Tools in this post
You may also like
-

Article
Deploying cross-database dependencies to different environments
The SQL Change Automation team here at Redgate occasionally take time out from development to explore some of the issues our customers face when automating deployment of database changes. As part of one such exercise, we took a closer look at cross-database and cross-server dependencies – these can cause problems when deploying databases to multiple environments
-

Article
Basic data masking for development work using SQL Clone and SQL Data Generator
Richard Macaskill describes a lightweight copy-and-generate approach for making a sanitized database build available to development teams, using SQL Clone, SQL Change Automation and SQL Data Generator.
-

Article
Unearthing Bad Deployments with Redgate Monitor and Redgate's Database DevOps Tools
Sudden performance issues in SQL Server can have many causes, ranging all the way from malfunctioning hardware, through to simple misconfiguration, or perhaps just end users doing things they shouldn't. But one particularly common culprit is when deployments go wrong: I don't know a single DBA who hasn't been burned by a bad release.
-

Article
Database Continuous Integration with the Redgate SQL Toolbelt and Azure DevOps
Alex Yates shows how to set up automated processes for SQL Server database source control, build and continuous integration using Redgate SQL Toolbelt, Git and Azure DevOps
-
Article
Getting Started with Automatic Database Branch Switching
Alexander Diab demonstrates how a team of developers can work on and test features in different branches of a SQL Server database development project, while their local development database automatically remains 'synchronized' with the current branch in version control.