What’s new in v6.3 of Data Masker for SQL Server
The first time you approach the task of data masking, it can seem daunting. You've identified your sensitive columns, but how do you decide on the best data masking strategy? Which rules do you need in your data masking set? Data Masker for SQL Server makes it easy to decide.
If you want to use a copy of the production data for development and test work, then you’ll need both a plan and a strategy for protecting data that is classified as personal identifiable data, personal sensitive data or commercially sensitive data. First, you’ll need to find out in which tables and columns this personal or sensitive data resides, and document this, and then you’ll need to devise and implement a way to sanitize this data.
It’s relatively easy to anonymize data entirely; simply replace all the data with fake values. However, this is not so useful for development or test work, where we’d like the data, although sanitized, to have the same distribution and characteristics as the original data.
This is where Data Masker helps. It provides an array of data masking rules, tools and methods so that regardless of your database design, or what type of data to you to mask, you can do so in a way that the sanitized data still looks and behave like the real thing.
Helping you choose the right rules
Data Masker is a versatile tool, but that means it offers a lot of different rule types, including Command rules to allow us to execute SQL statements in the target schema, Substitution and Shuffle rules to replace and scramble data values, while retaining a certain data distribution, and many more.
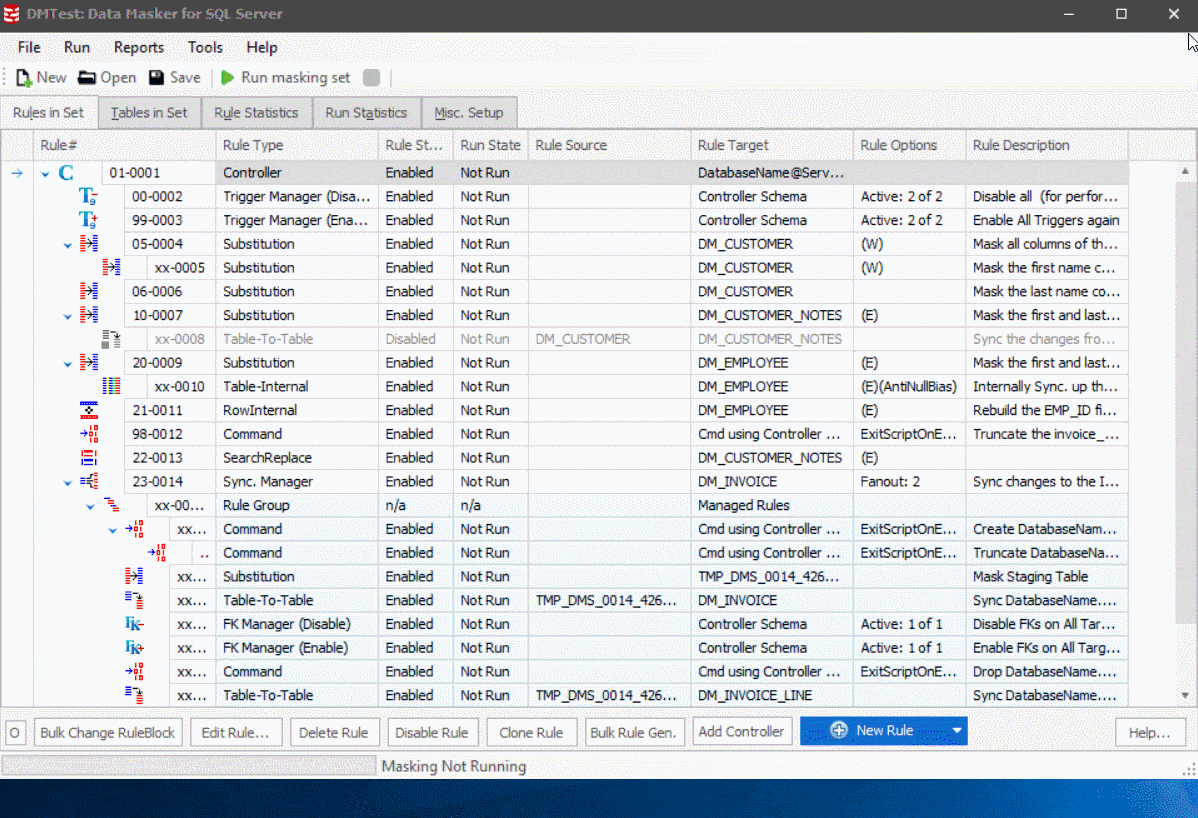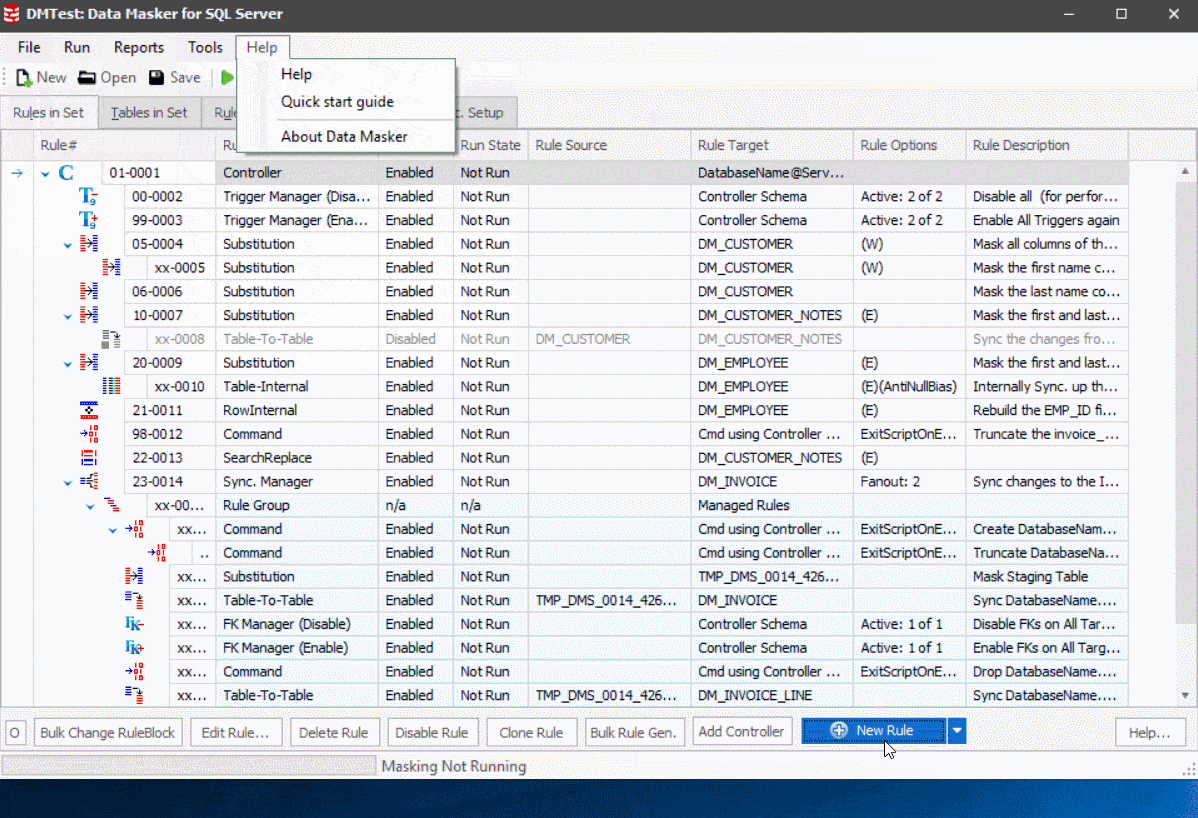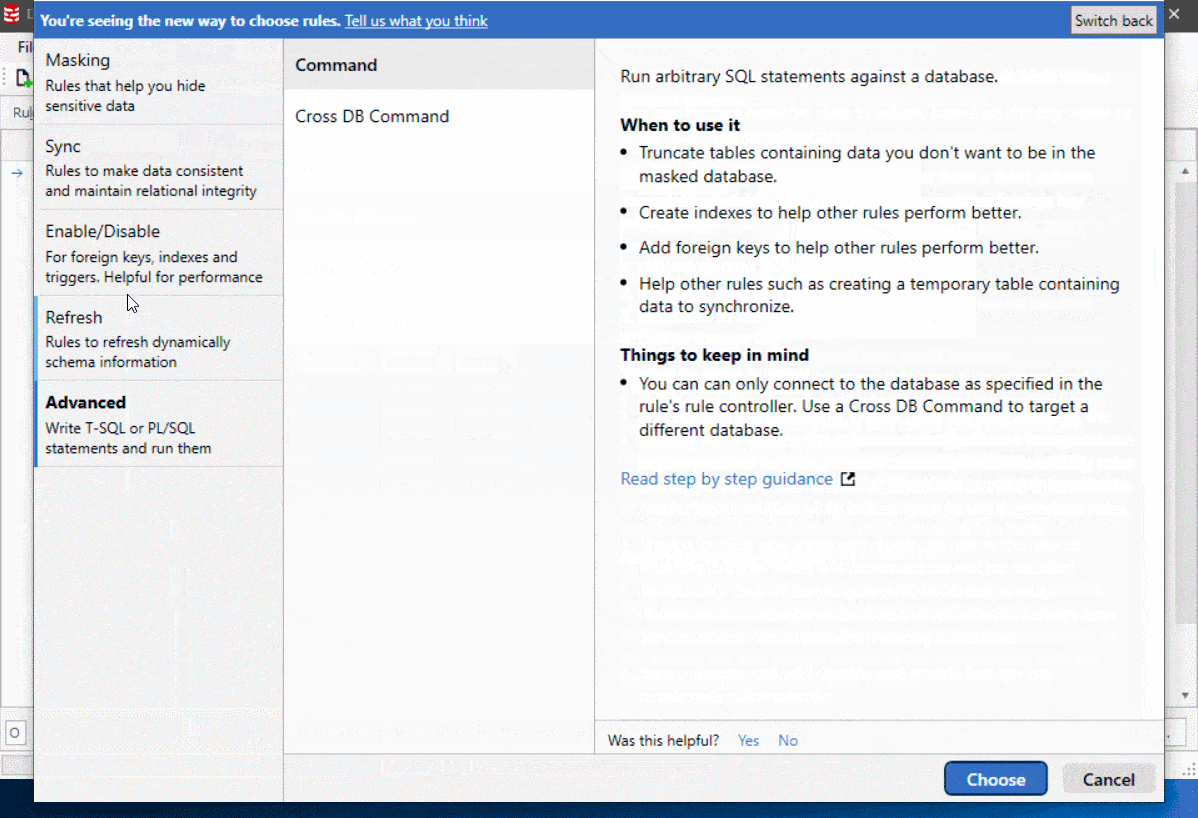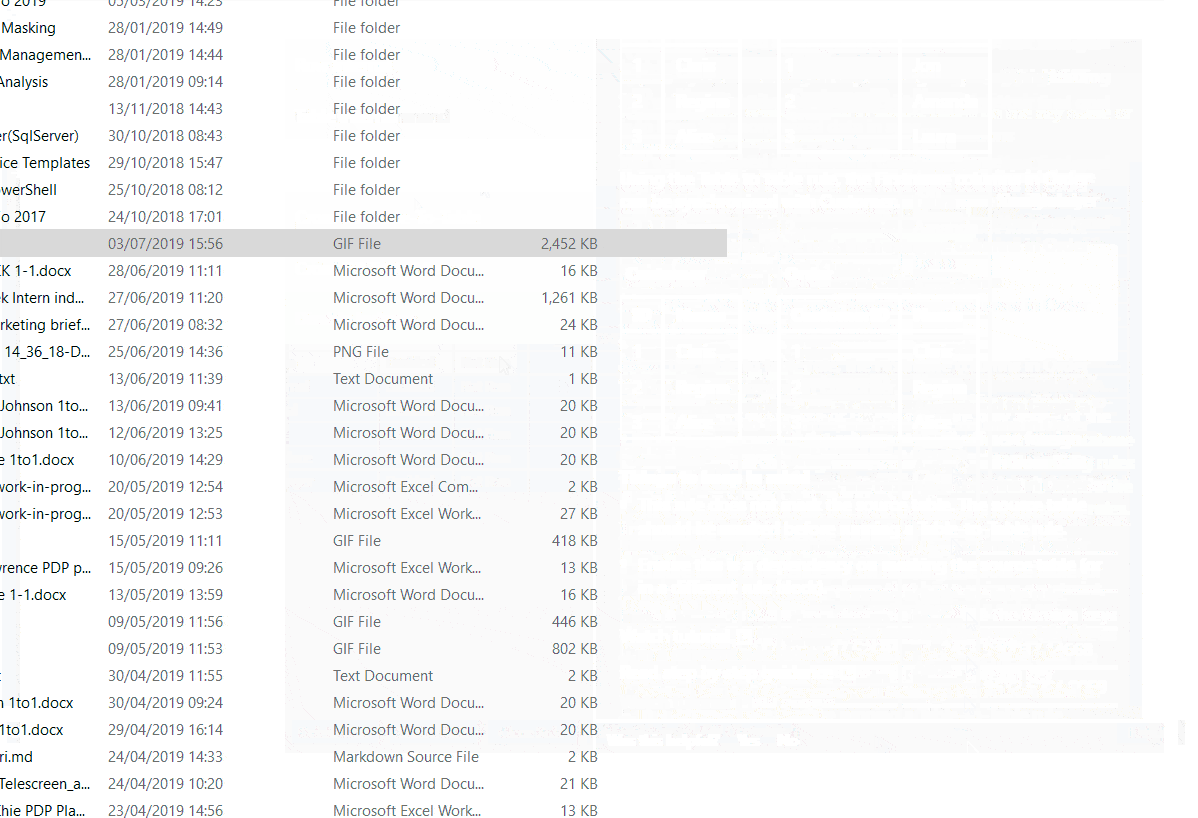
Figure 1
In v.6.3 of Data Masker for SQL Server our goal was to make it much easier to define the correct rule set, by making it much easier to identify the type of rule that best fits your needs. The most important change we’ve made is to overhaul the “Add a rule” window so that it offers a lot more guidance on which type of rule might best suite your requirement:
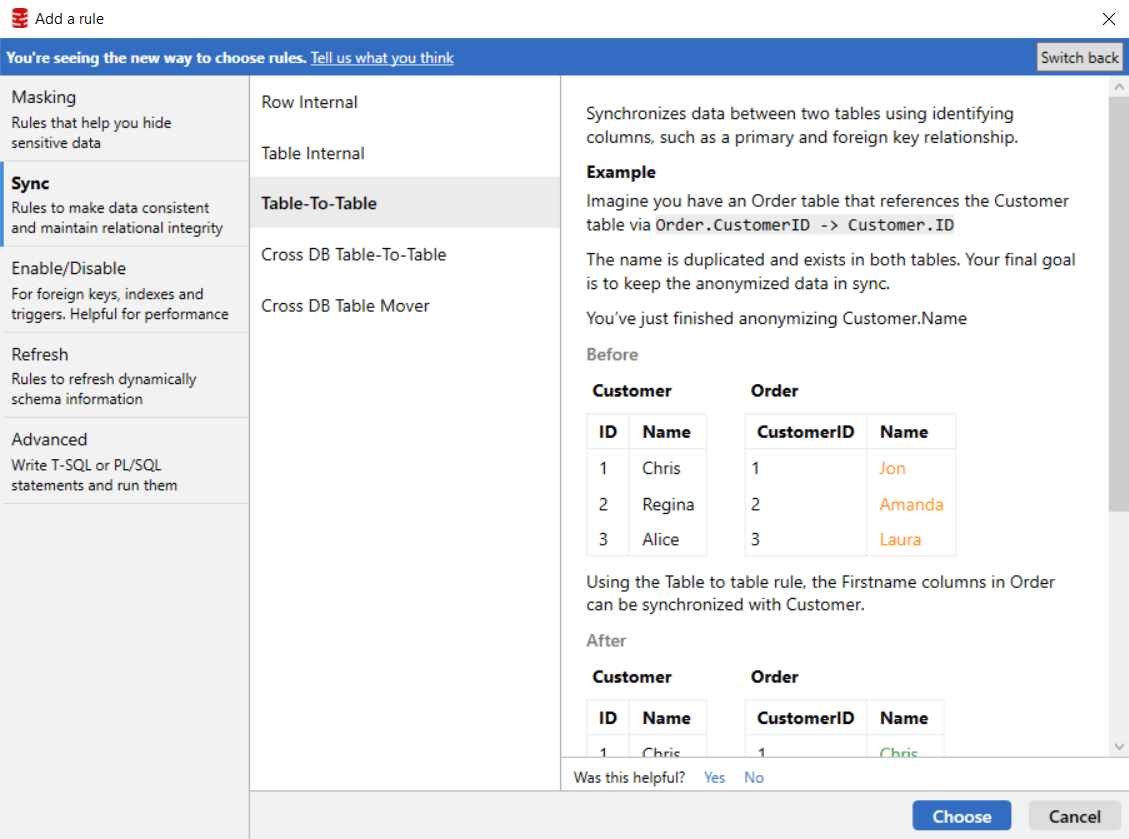
Figure 2
As well as a cleaner look and feel, each rule includes in-product guidance about when to use the technique. You can also find links to specific online tutorials at Redgate University.
We’ve also sorted the rules into new categories based on the type of problem they solve.
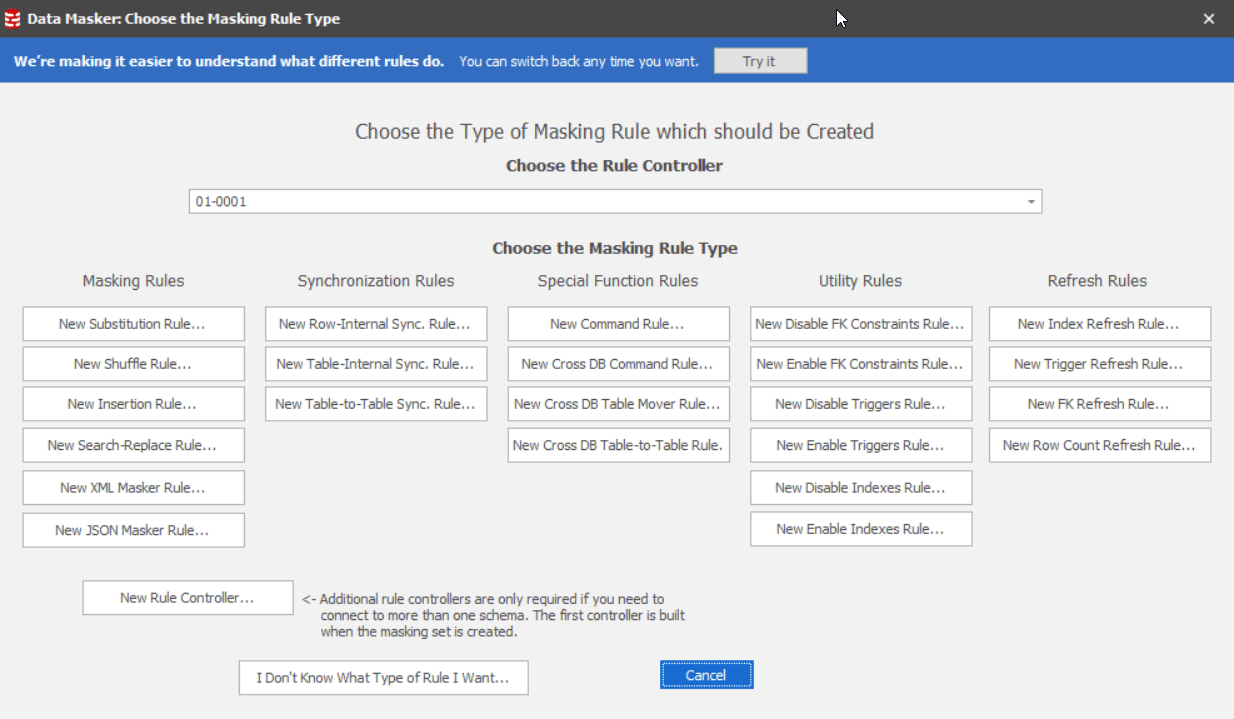
Figure 3
To give it a go, all you need do is hit the ‘Try it now’ button at the top of the old “Add a rule” window. You can switch back anytime.
Quick access to frequently used rules
We’ve also made it a lot easier to get to the rules you use most commonly without opening the rules window. Just click on the New Rule dropdown at the bottom of Figure 1:
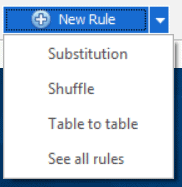
Figure 4
You’ll also notice in Figure 1 the new menu bar and tool bars. Removing the sidebar gives more space to focus on the task at hand and turning the tools tab into a menu makes possible to grab a tool without shifting context. The standard Windows menu bars should feel very familiar.
What do you think?
If you already have Data Masker for SQL Server, you can try this out today by upgrading to the latest version. Alternatively you can download a trial.
We’d love to hear how this works for you, drop us an email at datamaskereap@red-gate.com
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
SQL Provision
Provision virtualized clones of databases in seconds, with sensitive data shielded
You may also like
-

Article
Backup and restore of a SQL Clone
What if you now do development work on a clone, but you to continue working on you own local clone while ‘disconnected’, such as when travelling? One simple option if the original database contains no private data, or the image has been masked, is to performance a normal backup and restore operations the clone, although you'll now be working with a normal, full-sized database.
-

Article
Getting Started with SQL Data Masker: I Need to Mask some Columns
Grant Fritchey explains the core rules and features of Data Masker, and how you go about using them to mask columns, so that when the data is used outside the production system it could not identify an individual or reveal sensitive information.
-
Article
How to create and refresh development and test databases automatically using SQL Clone and SQL Toolbelt
A PowerShell automation script to build a SQL Server database from source control, seed it with dummy data, document it, and then deploy copies to any number of test and development servers.
-

Article
Getting Started with Database Development Using SQL Provision
Steve Jones shares how he migrates his existing development databases to clones, using SQL Provision and a simple PowerShell function.






