
If you are thinking of deploying Exchange 2007, the chances are that you have a requirement to implement the product with high availability in mind. More and more organizations are placing much more importance on the messaging infrastructure and, as a result, high availability and site resilience have a much higher emphasis than they did several years ago. In this article I’m going to cover the high availability options within Exchange 2007, giving you an outline of each one and the options you have for implementing the product with high availability in mind.
I’m going to assume that you’ve already made the decision to implement Exchange 2007 in a highly available manner, so I won’t be covering the discussion points around whether high availability is appropriate for you or your organization. That will make a useful discussion topic for a future article. Another subject that will also make a good discussion topic for a future article is the site resilience option available for Exchange 2007 and therefore I won’t be covering that at this time.
Finally, bear in mind that I’m going to be covering the native options available in Exchange 2007 and therefore no 3rd party high availability solutions will be detailed within this article.
As you likely know, Exchange 2007 is comprised of five different server roles and each one has high availability options, some of which differ quite significantly from others. We’ll take each of the five roles in turn and detail the options you have for making these roles highly available.
Mailbox Server Role
First, let’s take a closer look at the high availability options for the Mailbox server role. This is where the users’ actual mailbox data is stored so it’s one of the key roles to make highly available.
When you think of high availability for mailboxes in Exchange, you will most likely think of clustering since many previous versions of Exchange have included this technology. So it will come as no surprise that clustering is also at the heart of high Availability in Exchange 2007, although there are some significant changes that may cause you to re-evaluate clustering if you have previously dismissed it.
Single Copy Clusters
The first technology we’ll look at is Single Copy Clusters (SCC). This technology will be familiar to those Exchange administrators who have implemented clustering in previous versions of Exchange since it’s essentially the new name for ‘traditional’ Exchange clustering.
SCC in Exchange 2007 is essentially the same as previous versions of Exchange clustering. This means that it still uses the shared storage model, where the actual mailbox and public folder databases only exist once within the storage infrastructure (hence the term single copy). The individual cluster nodes of the SCC environment can all access the same shared data, but only one node at a time can actually use it. Figure 1 shows a simplified diagram of how this might look with a three-node SCC environment.
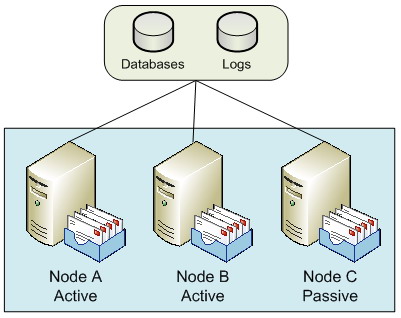
Figure 1: Single Copy Clusters
In Figure 1, you can see three nodes within the SCC environment, two of these are curretly active nodes (i.e. they are actively servicing users), while the third is passive. Exchange 2007 clusters only support the active/passive model: it’s possible to have up to eight nodes configured as long as one is passive
The passive node is available to take ownership of the data currently belonging to one of the active nodes, if and when an issue arises with one of those active nodes. With up to eight nodes available, some interesting combinations can be designed. For example, you might consider a six-active and two-passive node system, or perhaps a four-active and four-passive node system. The latter option actually falls within the Microsoft best practice recommendations, since Microsoft recommends that you have at least one passive node for every active node that you implement.
You might consider a configuration such as a two active and two passive node SCC environment to be wasteful in terms of hardware resources, since two nodes aren’t actually offering a service to the users. However, you have to consider the reason that you may have implemented such a design: high availability, and therefore the preservation of your messaging service in the event of a node failure. For example, consider the case in Figure 1, where you have two active nodes and a single passive node. If Node A fails, the service will failover to use Node C and users are largely unaffected. However, you are now in the situation where you no longer have a passive node available until you resolve the problem with Node A. Therefore, if Node B were to fail before Node A is brought back into service, there is nowhere for the services on Node B to failover to and thus users will be affected. Therefore, having at least one passive node per active node is good practice.
You can clearly see that an SCC environment is excellent at providing high availability in cases where there is a server failure. Although SCC environments can and do provide good levels of uptime, the main drawback with SCC is the fact that there is only a single copy of the storage present. Some organizations implement their Exchange databases on replicated Storage Area Networks (SANs) to overcome this. Here, synchronous data replication can be used to ensure that the Exchange databases are copied to a different SAN, typically located in a different data centre.
One key area to consider regarding clustering is that if you deploy the Mailbox server role on a clustered solution, either using SCC or Clustered Continuous Replication (CCR), which will be described later, no additional Exchange 2007 server roles can be combined with the Mailbox server role. Consequently, the minute you decide to deploy a SCC environment for your Mailbox servers, you will need additional servers to run other roles such as the Hub Transport and Client Access Server roles.
Local Continuous Replication
This is the first of the new continuous replication technologies available within Exchange 2007. The first and most obvious point to make about Local Continuous Replication (LCR) is the fact that it is a single-server solution and not a clustered solution. Therefore, LCR will not protect you against the failure of an entire server. Having said this, LCR does implement the new log shipping and replay functionality that Exchange 2007 provides. It does this by shipping the transaction logs generated by a storage group, known as the active copy, to another separate set of disks that are connected to the same server, referred to as the passive copy. Once the logs have been transferred to the alternate disks, they are replayed into a copy of the Exchange database that also resides on these disks. Thus, a separate copy of the database is maintained in near-real time fashion on the same server, and you therefore have data redundancy. Should there be a problem with the production database the administrator can switch over to using the backup copy of the database fairly quickly. An overview diagram of LCR is shown in Figure 2.
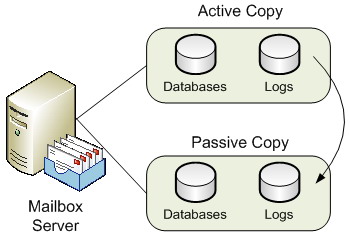
Figure 2: Local Continuous Replication
It makes the most sense to deploy the second set of disks via a separate disk array controller to cover for the failure of the primary disk array controller. As I’ve already mentioned, LCR is not a clustered solution and therefore does not protect you should the entire server fail. However, it is a good solution to protect against mailbox data corruption and additionally offers the ability to offload Volume Shadow Copy Service (VSS) backups from the active copy of the databases. In this scenario, you configure the VSS backup to be performed against the passive storage group. This is better for disk performance on the active storage group as well as allowing online maintenance to be unaffected by the backup process.
Clustered Continuous Replication
Whilst SCC offers you protection against server failure and LCR offers you protection against data failure, Clustered Continuous Replication (CCR) offers you both server and data protection. As you can guess from the name, CCR is the second of the new continuous replication technologies available with Exchange 2007. A CCR environment is a two-node cluster only, consisting of an active and a passive node. The key difference between a CCR environment and a SCC environment is that the CCR environment does not use shared storage. Rather, both nodes of the CCR environment have their own copies of the Exchange databases and transaction logs. The transaction logs from the active node are asynchronously copied to the passive node and replayed into the database. Should a problem occur with either the active node itself or the active node’s databases, the Exchange server can be failed over to run from the previously passive node and its own copy of the databases. A sample CCR environment configuration is shown in Figure 3.
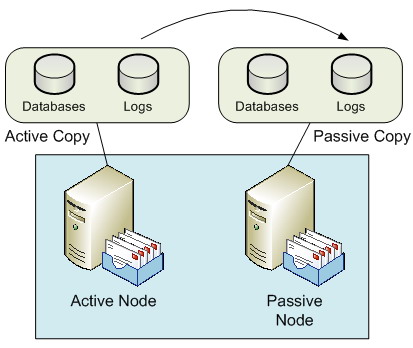
Figure 3: Clustered Continuous Replication
As I stated earlier, a CCR environment consists of two nodes; it cannot be scaled out to eight nodes as with the SCC environment. However, the fact that CCR implements two separate copies of the databases and transaction logs is usually attractive to many organizations. Also, CCR can be implemented using Direct Attached Storage (DAS) rather than SAN storage. This, too, can appear attractive to many organizations although it is important to note that this may not necessarily be a straight decision to make as there are other factors to consider. Also, VSS backups can be taken from the passive node, which is obviously good for the performance of the active node, plus it has the added benefit of allowing online database maintenance to run outside of the backup window.
Some organizations may choose to implement the active CCR node in one data center with the passive CCR node in a different data centre. This is technically fine, although it should be noted that if you are deploying CCR on the Windows 2003 operating system, both CCR nodes must be in the same subnet. You will therefore need to check with the network team in your organization as to how the network is configured across the two data centers. This restriction does not apply to Windows 2008 since clusters can be implemented with nodes from different subnets, although the nodes must be in the same Windows Active Directory site. With nodes in different data centers, the CCR environment can be considered a stretched cluster. You will also need to factor in considerations such as the available network bandwidth between the two data centers as well as the latency of the network connection. Such factors can affect the performance of the system, especially when you consider the fact that the various server roles will communicate via Remote Procedure Calls (RPCs) and thus require sufficient bandwidth.
Consequently, many organizations choose to implement a CCR environment within their production data center and Standby Continuous Replication (SCR) to a disaster recovery data center. CCR then protects from server and data failure within the same data center, which is more likely than the complete loss or failure of a single data center. Having said that, you may still need to plan for that eventuality which is where SCR comes in. SCR is a site resilience solution available in Exchange 2007 Service Pack 1 that currently falls outside of the topics that I want to cover in this article.
Hub Transport Server Role
If you have chosen to implement one of the high availability solutions for the Mailbox server role, your decision will likely be meaningless if you do not consider high availability for the Hub Transport role. The reason for this is an architectural change to the way messages are routed in Exchange 2007. In Exchange 2007, all messages are routed via the Hub Transport server role, even messages between users on the same database on the same Mailbox server. Therefore, if you have deployed an Exchange 2007 CCR environment, for example, but at the same time deployed just a single Hub Transport server, you should be aware that no messages will flow around your infrastructure should the single Hub Transport server fail.
It’s therefore vital to include the Hub Transport server role in your high availability planning. Fortunately, including high availability with the Hub Transport server role isn’t as complicated as the Mailbox server role, since this feature is built into the Hub Transport role by default. Therefore, all you essentially need to do is deploy multiple Hub Transport servers; no clustering or load balancing is required. For example, if you’ve deployed a single CCR environment consisting of two clustered Mailbox server roles, you’d likely deploy two independent Hub Transport servers for a balanced design.
Load balancing and redundancy is automatic with the implementation of multiple Hub Transport servers, and therefore no additional configuration is required. If two Hub Transport servers are deployed within the same Active Directory site, the Mailbox server will use them both; if one Hub Transport server fails, the remaining Hub Transport server will continue to process the messages from the Mailbox server. Additionally, when considering communications across Active Directory sites, a Hub Transport server in one Active Directory site will automatically use multiple Hub Transport servers in a different Active Directory site.
As I’ve already said there is no need to deploy hardware load balancing solutions or technologies such as Windows Network Load Balancing (NLB) when considering the Hub Transport server role. However, you could find yourself in the position where you wish to implement the Hub Transport server role on the same servers as the Client Access Server role, which themselves may be configured with Windows NLB. If that’s the case, it’s important to know that you can use Windows NLB to load balance the client connectors if you are using Exchange 2007 Service Pack 1, but take care to ensure that your Windows NLB configuration excludes the default SMTP communications on port 25 that occur between Hub Transport servers. We’ll look a bit more at Windows NLB in the next section.
Client Access Server Role
As with the Hub Transport server role, if you’ve elected to implement high availability for your Mailbox server role you should consider the same for the Client Access Server role. However, you may be thinking that you don’t need to do this based on the fact that maybe you’re not implementing client access methods such as Outlook Web Access, POP3, IMAP4 and so on. After all, these are the types of clients that communicate via a Client Access Server, right? Well, whilst that is absolutely correct, don’t forget that the Client Access Server also runs the Availability and Autodiscover services, which are also important for clients running Outlook 2007. If you’re spending the money to implement high availability for the Mailbox and Hub Transport server roles, implement high availability for the Client Access Server role too. The most common way to do this is to implement Windows NLB to load-balance the relevant communications ports. Of course, hardware load balancing can be used too. With Windows NLB, you essentially have a single IP address that is shared amongst the servers, which have their own IP addresses themselves. Figure 4 gives you an idea of how this might look, where a user is connecting to Client Access Servers.
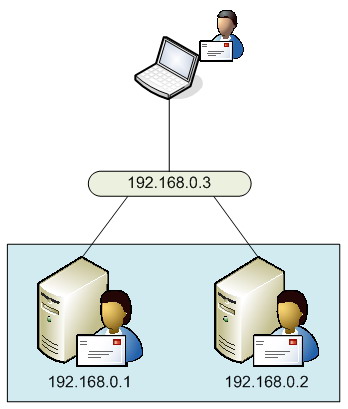
Figure 4: Windows NLB
As I mentioned in the previous section, on Hub Transport servers, some organizations choose to combine the Client Access Server and Hub Transport server roles onto the same server. This configuration wasn’t officially supported by Microsoft in the Release To Manufacturing (RTM) version of Exchange 2007 but is supported now that Exchange 2007 Service Pack 1 has been released. However, don’t forget what I previously mentioned within this article around the load balancing of client connectors, and the need to exclude the Hub Transport server SMTP communications from the load balancing configuration. Equally it should be noted that you don’t actually have to combine the Hub Transport and Client Access Server roles on the same server. In fact, in larger deployments the Client Access Server and Hub Transport server roles are separated onto different servers. This means that deployments consisting of a single CCR environment can actually see six servers deployed, namely two for the CCR environment, two for the Hub Transport server role and two for the Client Access Server role. This can be further added to by the deployment of the Unified Messaging and Edge Transport server roles which will be covered in the next two sections.
Unified Messaging Server Role
High availability for the Unified Messaging server role is similar to that of the Hub Transport server role in that you need to deploy multiple Unified Messaging servers to achieve redundancy. However, there is a little more configuration to do to achieve this. The key to achieving this high availability is to ensure that the Unified Messaging servers are configured in a single dial plan. The dial plan is effectively the link between an Active Directory user’s telephone extension number and their Exchange 2007 mailbox that has been enabled for Unified Messaging. Your Voice over IP (VoIP) gateways find your Unified Messaging servers via the dial plans and will attempt to connect to one of those Unified Messaging servers. Ultimately, if no response is received, the VoIP gateways will try the next available Unified Messaging server. I use the term gateways (plural) since you’ll likely implement multiple VoIP gateways in addition to multiple Unified Messaging servers to complete your redundant configuration.
Of course, in the example situation where two Unified Messaging servers are available, the VoIP gateways can be configured to balance incoming calls across both Unified Messaging servers. Note that technologies such as Windows NLB and round-robin DNS aren’t used to provide this high availability and redundancy. Rather, the VoIP gateways can be configured with either the IP addresses or the Fully Qualified Domain Names (FQDNs) of both the Unified Messaging servers.
Edge Transport Server Role
The Edge Transport server is unique amongst the five Exchange 2007 server roles in that it is the only server role that has to be deployed independently, and therefore cannot coexist with any other server role. Achieving high availability for the Edge Transport role once again involves the implementation of multiple servers. Since your Edge Transport servers effectively sit in between your Hub Transport servers on your internal network and the Internet, you simply need to ensure that your Hub Transport servers and the SMTP servers of everyone else on the Internet know how to contact them.
For inbound messages, the typical way to achieve this is to implement multiple Mail Exchanger (MX) records in DNS. You can either implement MX records with identical weightings, in which case both Edge Transport servers will be used equally, or you can implement the MX records in priority order. In the latter case, one Edge Transport server will be used in preference to the other, with the secondary Edge Transport server only being used if the primary Edge Transport server fails.
For outbound messages, the preferred option is to create Edge Subscriptions for each Edge Transport server. An Edge Subscription essentially links the Edge Transport server to the Hub Transport servers in a specified Active Directory site, thereby allowing, via Send Connectors, email messages to flow from the Hub Transport Servers to the Edge Transport servers.
Summary
In this article we’ve looked at the high availability options for each of the Exchange 2007 server roles. As you’ve seen, the most interesting options are available for the Mailbox server role but at the same time it’s vital to implement high availability for the other server roles if you’ve elected to choose a clustering solution for your Mailbox servers.
Load comments