
Performance – The Big Three
It is a real shame, actually. There are three major components that affect a computer’s performance: the speed and power of its processor, how much memory that it has, and the performance of its disk subsystem. Figuring out those first two – whether you need more memory and/or processing power – is generally pretty easy. For an example, refer to Figure 1.
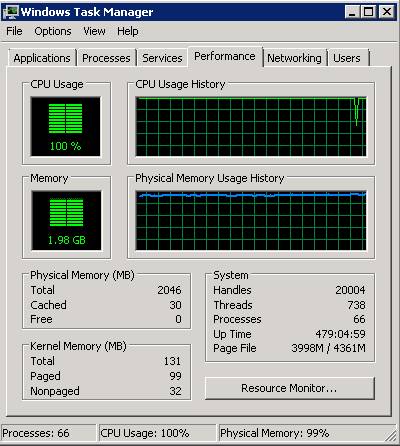
Figure 1: The First Sample Windows Task Manager Dialog
In Figure 1, it’s pretty easy to see that the processor on this computer is overburdened. For the entirety of the CPU Usage History graphical display, the utilization of the processor was almost always 100%. Similarly, when we look at the various memory indicators, it is also pretty plain that the memory on this computer is in short supply. It takes one more indicator to be certain of that, but we can reach that conclusion based on the following indicators:
- Physical memory is currently 99% utilized
- Free physical memory is at zero
- The usage history shows that physical memory has constantly been highly utilized
- The page file is 92% in use (3998 MB / 4361 MB)
Now, it is often true that processor utilization and memory utilization can be tightly related. For example, if a computer has so little memory that the operating system is constantly required to move data into and out of the swap file, this tends to keep the processor utilization higher than it would be otherwise. However, since disk is so much slower than memory, it’s rare that such a situation can cause a processor to be 100% utilized.
Also, you should note that physical memory being 99% utilized is not, by itself, an indication of memory depletion. In the general case, Windows will try to cache system files and system data into memory, if memory is available to do so. This allows Windows to access those items much more quickly, since memory is so much faster than disk.
If Figure 2, you can see another picture of that same computer, just a short while later.
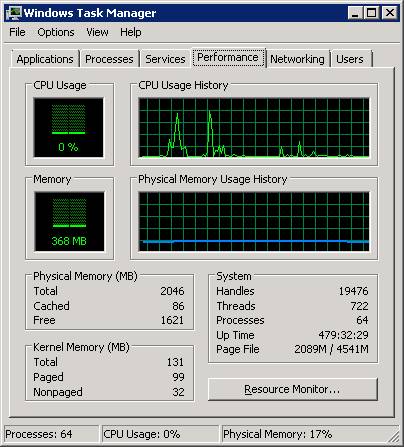
Figure 2: The Second Sample Windows Task Manager Dialog
In Figure 2, you see a processor that is fairly idle with no memory pressure. The total physical memory has not changed, but in this second performance snapshot, the amount of free memory is up to 1,621 MB and the page file is only 46% in use.
Based on what we see in Task Manager, this computer should be performing very well, shouldn’t it?
Of course, that is a trick question. In the first paragraph of this article I mentioned three key contributors to performance and so far, I’ve only discussed two. The third? Disk subsystem performance. Unfortunately, there is no sure-fire, single-graph view that will absolutely identify whether your disk subsystem is performing well or not. You have to do some investigation. That investigation is why some folks consider disk subsystem performance management something that is “more art than science”. However, I would disagree. Diagnosing performance issues is actually very direct. Now, predicting end-user disk subsystem utilization – that is a black art!
LogicalDisk vs. PhysicalDisk
A key component of understanding how to measure the performance of an Exchange disk subsystem – or any disk subsystem – is to understand the difference between the LogicalDisk and PhysicalDisk performance objects. This is even more important than normal since these object may, or may not, measure the same things.
The easiest way I’ve learned to explain them is below. Stay with me through the entire four parts of the explanation to find your “Ah-hah!” moment…
- LogicalDisk – A logical disk is the unit of a disk subsystem with which Windows and users utilize a disk. When you open “Computer” (or “My Computer” for Windows 2003 and older versions of Windows) the hard disk drives shown there are logical disks.
- PhysicalDisk – A physical disk is the unit of a disk subsystem which the hardware presents to Windows.
- A logical disk may consist of multiple physical disks (think of RAID)
- A physical disk may host multiple logical disks (think Windows partitions)
If you put all of these together, this means that in the case where a physical disk contains only a single Windows volume, LogicalDisk and PhysicalDisk measure the same thing.
Note: The highest performance disk devices currently available (Fiber Channel dual-controller disks) provide about 180 input-output operations per second (IOPS). They are quite expensive. More common enterprise class disk devices provide about 150 IOPS (for a 15K RPM SAS disk). Workstation class disk devices have much lower performance, often around only 35 – 50 IOPS.
Somewhat confusingly, disk aggregators (this includes RAID controllers, Storage Area Networks, Network Attached Storage, iSCSI, etc.) may present many physical disks as a single logical device to Windows. However, each of these devices (known as a logical unit number or LUN) may again actually represent multiple logical or physical disks. Thankfully, from a Windows performance perspective, those distinctions can be ignored, at least until a specific LUN is identified as having a performance issue. In that case, in order to acquire more specific data, you will have to use performance tools from the aggregator’s provider as the disk aggregators can sometimes provide unpredictable results.
Is there a conclusion here? Yes, there is. The conclusion is that in the most common cases, the performance of a LogicalDisk object is in what you are most interested.
Note: Lots of SAN and NAS software provides a feature called “LUN stacking” or “disk stacking” which allows multiple LUNS to exist on a single physical disk. This just complicates your life. Avoid it. J Just always remember that you have to be able to identify what you are measuring and the boundaries on that measurement. If you have multiple applications accessing a single physical disk, then your performance will always be non-deterministic and difficult to predict.
What do I measure?
Now that you know which performance object is interesting, what do you do with it?
As you probably know, any performance object is composed of a number of individual performance counters. A counter contains a discrete value which may be any of:
- A value that has been increasing since the last time the counter was cleared (which normally happens at system reboot).
- A value that represents the delta (change) since the last measurement.
- A value that represents the percentage change since the last measurement.
- A value that represents an instantaneous measurement of some item.
- A value that is a percentage against some absolute (such as a time interval).
For the LogicalDisk performance object, there are 23 counters:
- % Disk Read Time – the percent of wall-clock time spent processing read requests since the last sample
- % Disk Time – % Disk Read Time plus % Disk Write Time
- % Disk Write Time – the percent of wall-clock time spent processing write requests since the last sample
- % Free Space – the amount of unused space on the disk, expressed as a percentage of the total amount of space available on the disk
- % Idle Time – the percent of time spent idle since the last sample (that is, processing neither read nor write requests)
- Avg. Disk Bytes/Read – the average number of bytes transferred from the disk in each read operation since the last sample
- Avg. Disk Bytes/Transfer – the average number of bytes transferred from or to the disk in each I/O operation since the last sample
- Avg. Disk Bytes/Write – the average number of bytes transferred from the disk in each write operation since the last sample
- Avg. Disk Queue Length – the average numbers of I/O requests (both read and write) queued for the selected disk since the last sample
- Avg. Disk Read Queue Length – the average number of read requests queued for the selected disk since the last sample
- Avg. Disk sec/Read – the average amount of time that it took for a read request to complete for the selected disk since the last sample
- Avg. Disk sec/Transfer – the average amount of time that it took for any I/O request to complete for the selected disk since the last sample
- Avg. Disk sec/Write – the average amount of time that it took for a write request to complete for the selected disk since the last sample
- Avg. Disk Write Queue Length – the average number of write requests queued for the selected disk since the last sample
- Current Disk Queue Length – the current number of I/O requests queued for the selected disk
- Disk Bytes/sec – the average rate, or speed, that bytes are transferred from or to the selected disk during any I/O operation
- Disk Read Bytes/sec – the average rate, or speed, that bytes are transferred from the selected disk during a read operation
- Disk Reads/sec – the average number of read requests that occur per second for the selected disk
- Disk Transfers/sec – the average number of I/O requests that occur per second for the selected disk
- Disk Write Bytes/sec – the average rate, or speed, that bytes are transferred to the selected disk during a write operation
- Disk Write/sec – the average number of write requests that occur per second for the selected disk
- Free Megabytes – the amount of unused space on the disk, expressed in megabytes
- Split IO/sec – if a read or write operation is too large to be satisfied in a single I/O operation, the I/O is split into multiple separate physical I/Os; this counter records how often that happens for the selected disk.
Speaking as a person who likes math, I think that all of these counters are interesting, and are worthwhile tracking over time. For example, if the % Free Space is decreasing on a regular basis, then you may need to plan to add more disks – or stop the expansion in some way. If your Disk Write/sec is trending upward, you may need to investigate why more write operations are occurring to that disk drive.
What Defines Good Performance?
For determining whether you have adequate performance, I would suggest that there are four main counters that you need to constantly monitor. Note that in this case, I’m suggesting that the counters should be checked every one to five minutes. Those counters are:
- Average Disk Queue Length
- Average Disk Read Queue Length
- Average Disk Write Queue Length
- Free Space (either % Free Space or Free Megabytes)
For [4], it should be obvious that if any write operations are occurring to a disk, if it fills up, performance will rapidly approach zero, the event log will starting filling with errors, and users will be calling your phone saying “Exchange is down” (or name your favorite application instead of Exchange). On the other hand, if a disk is read-only, such as a DVD-ROM database, there is no need to measure either [3] or [4]. Writes cannot occur. But that is a special case, and since we are primarily concerned with Exchange, it doesn’t support any type of read-only volume.
You may find it interesting that I use the average values instead of the current values. That is because any system can be instantaneously overwhelmed. At any given moment of time, you may have 50 I/O’s queued to a particular disk waiting to be satisfied; but that is unlikely to be the normal case. If that high queue value becomes the normal case, then the average values will trend quite high as well. That will server to provide you with an absolute indication of an issue which needs to be addressed.
If the average values are not high, then you had what is called a “usage spike” in which a device was temporarily overwhelmed. And that is why we have queues anyway
What is a “high value”? A high value occurs when the device cannot empty the queue. Because each I/O is variable in size, its arrival cannot be predicted, and the I/O takes a variable amount of time to complete; the point at which a device is considered saturated or overburdened with I/O requests actually occurs a little earlier than you may presume.
Now, I am not a statistician, nor do I play one on TV. However, like many of you, I took basic queuing theory in college. A device becomes saturated when its I/O queue exceeds 70% on an average basis. To put that another way: if the average disk queue length of a device exceeds 0.70 then the performance of that disk is negatively impacting user performance.
The overall Average Disk Queue Length is an average of the read and write average queue lengths. The read and write queues are maintained independently. A disk may (and in fact, usually will) have significantly different read and write profiles. While checking the Average Disk Queue Length is an important indicator of disk performance, if it indicates heavy usage, your first order of business is to determine whether read performance or write performance (or both) are causing the performance issue. Therefore my recommendation to continuously monitor all three counters.
So now you know: the best way to check your Exchange disk performance is to:
- Make sure there is room on the disk, and
- Monitor the average disk queue lengths.
The next thing you may want to know is – how can I predict how my disk subsystem should perform? But that is a topic for another article.
Load comments