
Over the past year, the topic of AI has really blown up in the general public. However, AI was already something very important to most corporations, but the Large Language Models (LLM) made it extremely fashionable.
When something becomes fashionable, a lot of people try to ride the wave with no care about the truth of the details and technology. There are already many online services offering “LLM” and “AI” for different purposes, even not recommended ones.
Let’s dig into the alphabet soup world of the AI and discover what’s fact and what’s only fashion.
Before LLM there was Machine Learning

While the term AI has been used a lot for many purposes, when AI was mentioned, companies were often talking about Machine Learning: Machine Learning is typically used to analyse trends and predict what will be the probable result in a specific scenario.
Predicting scenarios over existing data is (or was) the main objective of most companies. The most famous scenario is the discovery that men buying diapers at night are prone to by beer as well. Hence sales results will be better if diapers and beers are put together in a store.
How Machine Learning works
Using Machine Learning is about choosing the correct algorithm to make a prediction, make the correct training and tuning of the algorithm for a specific dataset schema and, once achieving an acceptable percentage of correct predictions, make it available for company usage.
 The professional who executes these tasks is typically a Data Scientist.
The professional who executes these tasks is typically a Data Scientist.
A machine learning algorithm can be summarized as a program capable to apply a mathematical model to a set of data in order to discover specific patterns on this set of data.
The choice of the correct algorithm for the various scenarios an organization needs requires a deep mathematical knowledge. Most of the outsiders in relation to IT area are used to thinking that the IT professions requires a lot of mathematical knowledge.
However, among the thousands of professions in the IT area, Data Scientist requires far more mathematical knowledge than most if not all typical IT professions including most programmers..
The machine learning process starts with training an algorithm. This involves preparing the algorithm to process a specific dataset schema and make one or more predictions from the data.
The dataset schema are the fields, with their specific data types, used by one table of data. Training an algorithm involves selecting the set of fields in the dataset which the algorithm should analyse to predict the value of a new field.
For example, let’s consider a credit analysis. Based on the person profile, will he pay his debt correctly, or will he stay in debt?
During the training process, the algorithm processes a set of data where the resulting field value is well known. In this way, the algorithm discovers a pattern among all the other fields which leads to a prediction of the resulting field.
For example, in a dataset of bank customers, the algorithm can analyze all the customer profile and identify patterns on the profile fields which leads to the customer to pay his debt or stay in debt.
Once the algorithm finds a pattern, we use the algorithm over a second set of data, for which we know the result but don’t provide it to the algorithm. The algorithm makes the prediction of the result, and we analyze what’s the percentage of hits or miss.
Machine Learning was also Fashionable
At its time, machine learning was also quite fashionable. One of the biggest complains from Data Scientists was about how they were usually hired in this position only to discover most of the work they had to execute was in fact related to Data Engineering and Business Intelligence.
Data Engineering tasks generally are those involving the data transformations and management starting from the production environment to the data intelligence environment, building a trustworthy data repository which can be used for machine learning.
Of course, many specialists would say I’m summarizing too much, forgetting about Data Architect, Data Governance and Data Modeler, but for the purpose of this explanation, it’s ok. There are a lot of functions that are involved in providing data to the Machine Learning processes.
The fashion of machine learning, with low knowledge about what it really involves, is what made many leaders hire Data Scientists and put them to work but not get what they needed because of all the lead in work.
The Data Engineering work to create a data intelligence environment and the business intelligence work over this environment should already be done before reaching machine learning implementations.
Over time, it will be interesting to see what behaviours LLM will generate as it goes from being fashionable to just another tool we all use?
What’s Business Intelligence
Business Intelligence is the process of exploring the data generated by the work of Data Engineers, make discoveries over this data, and deliver actionable information for the company decision makers.

This process is executed by Data Analysts with the support of Business Analysts.
It makes no sense the attempt to make predictions before you have a trustworthy data repository built by Data Engineers and Data Analysts had the opportunity to explore it to the extreme, extracting all possible actionable information from it.
Only after all this process is in place you will have a trustworthy data set and you will know what information needs to be predicted by machine learning algorithms.
Of course, exceptions to this order of work may exist, but that’s what they are, exceptions.
The Large Language Models are here
LLMs are completely different than Machine Learning algorithms. They are not a replacement or the evolution of Machine Learning, they are a very different side of Artificial Intelligence. This new side of AI managed to shift the fashion from Machine Learning to LLMs, but technically, there is no replacement.
Machine learning is still needed in companies together with LLMs. Leave machine learning behind and replacing it with LLMs would only be a new mistake caused by the effect of fashions over solid decisions caused by poorly educated (and typically excitable!) leadership.
What are Large Language Models
LLMs are algorithms, but they are not the kind of algorithm we train to make predictions, such as the machine learning ones.
The big techs, starting with OpenAI (the company), pre-trained LLMs with a huge amount of language understanding knowledge and general world knowledge up to 2021 (in the case of OpenAI’s initial offering).

The algorithm is capable to receive a specific collection of tokens, process them using the pre-trained knowledge and return another collection of tokens as a reply.
When talking about text and language, token can be counted as characters, for example. It depends on how the algorithm was built and configured.
For comparison purposes, the most powerful algorithms currently are capable to process 32K tokens and there are announcements of new algorithms capable to go up to 120K tokens.
This total of tokens is divided between the input, containing the main question and instructions and the reply.
The input is basically text; instructions, questions, etc. which could reach 1K, 2K tokens? The reply is also text, it would hardly be more than 2K tokens. This makes a total of 4K tokens. What about the other 28K tokens?
The other 28K can vary a lot depending on the implementation and the environment provided. By this I mean the features provided by OpenAI (on ChatGPT), by Microsoft (on Azure OpenAI feature) and others.
For example, we may be able to upload documents, ask to analyse a URL, connect to a source of multiple documents or more.
The Input: System and User Prompts
The input can be broken down in two parts: A System Prompt and a User Prompt.
System Prompt: It’s a set of instructions about how the algorithm should behave. This includes instructions about what subject of the human knowledge the algorithm should focus on, what and if some limit should be applied, what kind of language should be used to reply, what format should be used to reply and much more.
The algorithm was pre-trained with a so huge amount of knowledge that different instructions can result in completely different results, making the same algorithm seems like completely different applications depending on the instructions sent to the algorithm.
This method of work already created the concept of Prompt Engineering, the knowledge (or art?) about the best way to write instructions to an LLM to achieve the desired behavior. There is already the belief this can become a new profession.
User Prompt: It’s the input (question typically) made by the end user
At this point you may be asking: How do we use them? You may remember ChatGPT UI, where you ask a question and receive an answer, but where is the difference between System Prompt and User Prompt?
The difference between them becomes visible when using their development API to build an application. You can build a custom website to receive the user input. When submitting the user input to the algorithm, you send the System Prompt, and the user input becomes the User Prompt.
In this way, you can use the same algorithm to build applications which will seems to the user to be completely different from each other. The System Prompt is the first element to stablish the difference.
Additional Information for Processing
The features provided by the API’s define what additional information we can send to the algorithm. This may include:
- Files
- Urls for web scrapping
- Connection to Azure Cognitive Services
- Connection to Cosmo DB Mongo API
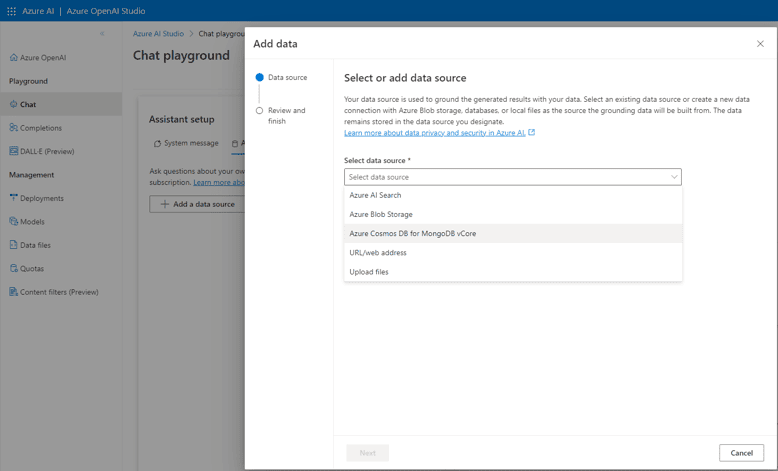
This allows the algorithm to use its power to process this information. The processing is based on language. It can summarize, find answers, and additional processing we can request through the prompts.
All this information, including the additional information sent, needs to be into the limit of tokens for each call of the algorithm. As a result, you can’t send a huge number of files or URLs. You may need to rely on different services working together, such as Cognitive Services Search, to find the best information to send to the algorithm.
Summarizing: The difference between Machine Learning and LLM
After analysing how each one, Machine Learning and LLM works, let’s summarize the difference between both.
| Machine Learning | Large Language Model |
| Models are intended for predictions | Although the reply could technically be called a prediction, it’s not for the end user. The model process existing data to provide an answer. |
| Model means an algorithm which requires training | Models are pre-trained. Additional training is minimal or none. |
| Model training is for one specific purpose | Model pre-training made by the big techs includes a huge amount of knowledge ingestion |
| The trained model analyses one specific dataset schema | The model provides answer about any knowledge ingested |
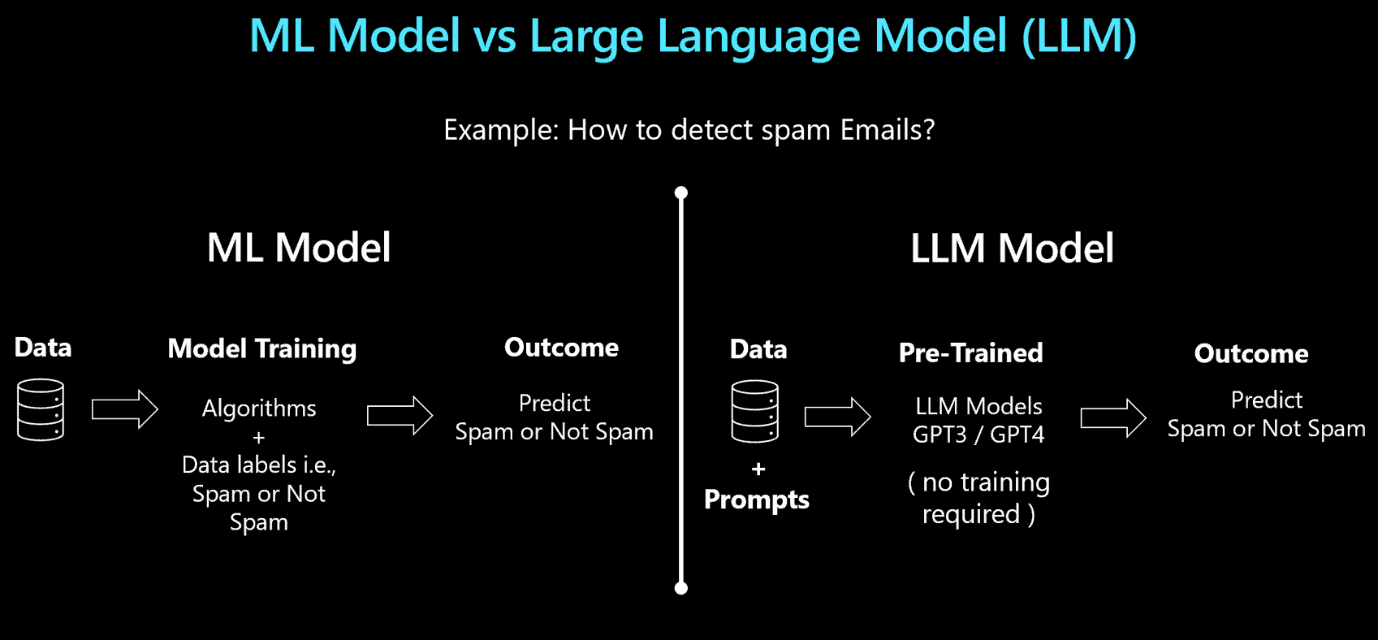
As you may notice, both have their own space in the corporate environment. They both can be used in the corporate data platform, with different purposes.
The Alphabet Soup increases: Bots and Co-Pilots
These are two words which became very common recently and linked to LLMs. But what is the difference between both and between them and the LLM itself?
Bots
A Bot is a chat software built using a tool which aggregates a language processing feature with a workflow developed to guide the subject of a conversation.
The Bot developer can design a conversation workflow to guide how the bot reacts when questioned about each subject.
The language processing feature ensures the bot can understand different ways to express the same subject, but that’s the limit of a bot, it has no additional intelligence.
Co-Pilot
A Co-Pilot is a custom chat app implementation using an LLM as a background. It’s associated with our daily tools and their system prompt is guided to provide specific results on our daily tools.
The co-pilots are being so integrated into existing daily tools that these tools are designed to call the backend LLM, get the result and make specific processing with the result according to the tool purpose. For example, find an email, implement a code, implement a report and so on. This is the result of a deep integration of the tool with a backend LLM deployment.
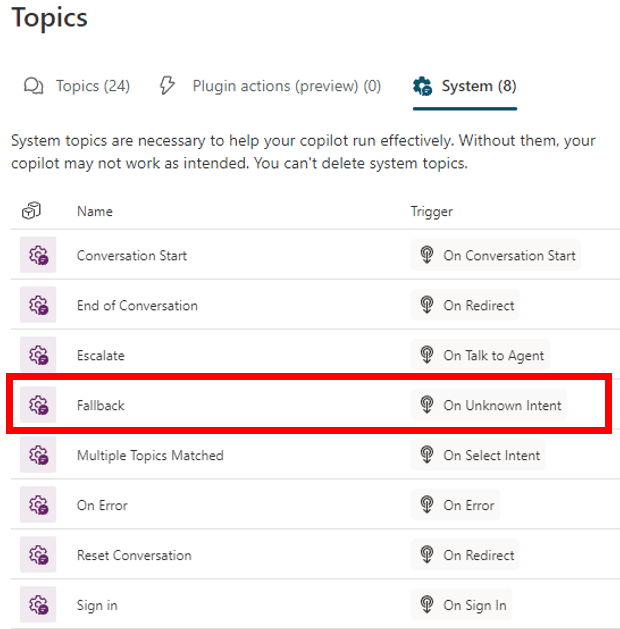
Difference between Bot, Co-Pilot and LLM
Bot: Provides a specific, controlled, and predictable set of answers.
Co-Pilot: It’s a specific implementation using an LLM as a backend. Its answers are not always predictable.
LLM: Is the backend algorithm used to implement what now became a convention to call Co-Pilot.
The use cases for each one is very simple:
- If you want a chat assistant with predictable and controlled answers, you use a Bot
- If you want a tool to help you with creation, search and processing, you use a custom Co-Pilot built over a backend LLM
- If you want the power of an LLM combined with a predictable workflow about a specific subject, you can build a Bot with a defined workflow and when the Bot doesn’t recognize the subject the user is talking about, the Bot send the question to a backend LLM, combining both.
After analyzing all this, it may seem easy to identify how wrong it would be to use an LLM as a virtual assistant for an end-user facing site: The answers are not controllable, you may be lucky and get good answers, but they can also be a mess.
Using a Bot, on the other hand, you can control the answers for specific conversation subjects, ensuring the bot provides good answers to your customer and leaving the power of LLM for more creative purposes.
This article came exactly when I found companies already offering LLMs to be used as virtual assistants on your website in the model of Software as a Service. Companies like this are not only riding on the fashion, but guiding the end user in the wrong direction.
Bots, Co-Pilots and Microsoft
Microsoft has a Bot Framework, which allows you to build bots completely by code. In the past, the bot framework had many helper tools, such as the bot composer, but these tools were not updated and are now deprecated. The Bot Framework, however, remains.
Inside Power Apps Platform, Microsoft created the Power Virtual Agents. The Power Virtual Agents are a no-code solution to build bots and integrate them on your applications. Recently, Microsoft rebranded the Power Virtual Agents as Co-Pilots and the portal to build them as Co-Pilot Studio.
What changed between Power Virtual Agents and Co-Pilots?
Microsoft included the capability to link the PVAs with an LLM in order to provide more powerful answers.
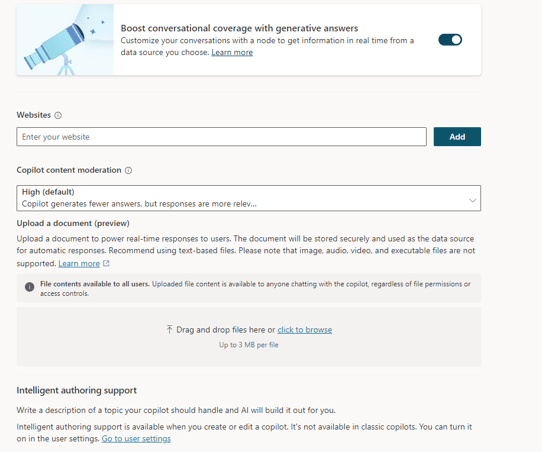
Although this goes on a good direction, using a bot and an LLM together, the configuration feature on the Co-Pilot in relation to the execution parameters of the LLM are limited. In my opinion, they will meet the needs of small business, exactly as power platform already does, but not the bit ones.
It’s important for the corporations to not fall for the wonders of a beautiful presentation: They will need, for sure, custom apps calling the LLM (such as an Azure Function calling Azure OpenAI) to control all possible LLM configurations and get all its power.
Summary
This is a great alphabet soup and it’s very easy to fall for the wonders presented in speeches which seems more like something for the show biz.
However, knowing exactly what each technology is and does makes it easier to identify the traps in the way and pursue the correct solution, built by the right specialists.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments