
If you want to get feedback on why your query is running slowly, then sharing its execution plan is the best way to get help, and the more information you include, the better feedback you can expect. However, many people are completely unaware of how much data is stored in an execution plan. Often, this won’t include any sensitive information, but in some cases, by sharing the plan, you might unknowingly ‘leak’ company confidential information, or violate privacy laws. Do not fall into this trap.
I’m a big advocate of using execution plans to troubleshoot slow queries, and of sharing them when you need to get help. This article explains the sort of data you might be exposing when you share a plan and suggests some ways to remove or anonymize potentially sensitive data, so that you can still share the plan, but safely.
Execution Plans and GDPR
It is impossible nowadays to search the internet without being greeted by posts about General Data Protection Regulation (GDPR), warnings about the repercussions of failure to adhere to its regulations regarding the storage, processing and removal of personal and sensitive data, and of course plenty of advertisements for tools and services to help with compliance.
All organizations want to collect data, and to be able to extract useful knowledge from it. The data professional has always been the person to warn the organization that data protection and privacy needed to be apriority, while engaged in these activities. For us, there is nothing special or new in the GDPR. In fact, it is proving a valuable tool in getting management backing for our cause: now that severe legal penalties are at stake, management is much more willing to listen and comply.
GDPR is only ‘bad news’ for organizations that have, up to now, been irresponsible in the way that they store and use their data, neglecting data privacy concerns. However, even in organizations that have tried to do the right thing, we all know that budgets and deadlines often get in the way. GDPR forces us to revisit past decisions and make sure everything is in order.
Which database and which tables hold personal data? Who has access to them? Is that database vulnerable to attack from within or outside the organization? Where does the data go when it leaves the database? It is the answer to that last question that can catch out even the experienced data professional. Sensitive data can ‘leak out’ of our database systems in many guises, including within your SQL Server execution plans.
Using and Sharing Execution Plans
SQL is a fourth generation programming language. It differs from third generation languages in that, when you write and execute a query, you are not telling SQL Server how to collect, filter, combine, and aggregate the base data in the tables to produce the required result. You only specify what result you want, and leave it to the database management system (DBMS) to decide how to get there.
In SQL Server, the query optimizer is the subsystem within the DBMS that figures out the “best” way to execute your query. Most of the time it does a great job. Sometimes, for various reasons, it fails and your query runs unexpectedly slow. Other times, you query logic has forced the optimizer to make certain choices, which has led to slow execution times. These cases require troubleshooting, and that process often starts with the execution plan.
The execution plan, created by the query optimizer, describes exactly what steps the execution engine takes when running a query. It reveals which tables and indexes a query accessed, in which order, how they were accessed, what types of joins were used, how much data was retrieved initially, and at what point filtering and sorting occurred. It will show how aggregations were performed, how calculated columns were derived, and much more. And this means that the execution plan usually also reveals why a query runs slow.
As regular readers of my blog will know, I’m one of the biggest fans of using execution plans to identify and resolve query bottlenecks. So please, do not misunderstand this article. I do not want you to stop using execution plans. However, I do want you to be aware of what you can, and what you should not, do with them, if you want to protect your company’s data.
The problems begin not with using execution plans, but when you share them. Perhaps you are a production DBA, handing the execution plan of a slow query to a developer. Or, perhaps you found an interesting execution plan that you want to send me, so I explain how it works, in a plansplaining post.
Most commonly, though, you are probably trying to tune a slow query, but are stuck. You are unsure where the problem lies, or are overwhelmed by its apparent complexity. At this point, you post the execution plan to a friend, or share it on a public forum, asking for advice. In all these cases, you might be sharing more than intended; there is more user data stored inside execution plans than most people realize, and by sharing execution plans with others, we could unwittingly breach data protection and privacy regulations.
The extent of the problem depends to some extent on how you share the plan. Sometimes, people just share a screenshot of the graphical plan, but often they will post the complete XML plan, as a .sqlplan file. Other times, they may share a plan in the format in which it was saved by a third-party tool, such as Plan Explorer.
Sharing Graphical Execution Plans
I’ve seen lots of post on public forums from people who are trying to tune a query, and have captured the associated plan, but don’t know how to proceed.
“My query is running slow, I think this is because of the Clustered Index Scan but I don’t know how to get rid of it. Please help!”
They will often post a screenshot of an execution plan, such as the one shown in Figure 1.
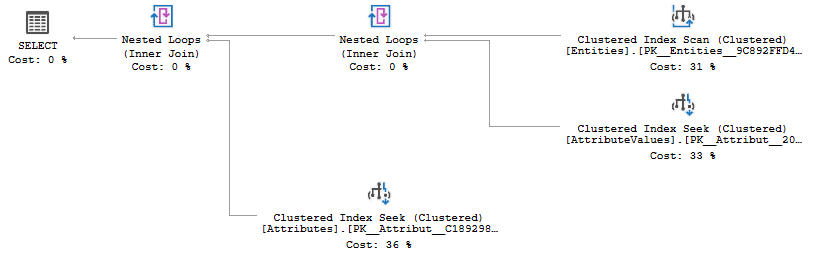
Figure 1
What Data is Stored in the Graphical Plan?
As you can see from Figure 1, by sharing a screenshot of a graphical plan, you are revealing some part of your data model, including the table names.
This is not a problem in most cases, but there are companies that treat their data model as company confidential. They are convinced that their data model is the best idea ever (trust me, it probably isn’t), that they are the first to have had the idea to use that data model (they aren’t), and that their competitors will promptly steal their idea if they see but a single table name (they won’t). And because of that conviction, they do not allow their staff to reveal table or column names in public.
The result? People ask for help on forums to fix a query performance problem, but without being allowed to post their code. I’ve seen cases where the forum user painstakingly anonymizes all the code, using fake object names, but then posts a screenshot of the real execution plan, which still exposes all the table names!
There can be other problems as well. I’ve seen data models where actual user data gets included as part of a table name. This is often a bad practice, or at least a code smell, but it happens. For example, imagine a company that does large infrastructure projects. Every project is unique and needs different tables, and so they include the customer name, or project name, in all table names. While this might well be a good design choice, in this case, it makes your table names company-confidential. Competitors can gain a huge strategic advantage if customer or project names leak during the bidding phase. For projects involving national security, often even the project name itself is considered classified.
Sharing Graphical Plans Safely
The good news is that this issue is easy to avoid. Go to a development server, recreate the same tables but with different names, and put in sufficient data to replicate the issue. Change the table names in the query to match your repro setup, then run it and capture the execution plan. You can now post both the query and the picture of the execution plan without worrying that confidential information embedded in the original table names leaks.
Sharing the XML Plan
A picture of the graphical execution plan is rarely enough for troubleshooting a slow query, because it fails to reveal many important operator properties. Each operator in a plan performs a distinct task and has a distinct set of property data. These properties often contain most of the useful information we need to read and understand the plan. This data reveals, for example, the number of rows the operator processed, how many times it was executed, details of any predicate conditions it applied, how many rows matched the conditions, details of any calculations and aggregations performed and a lot more.
Often, it’s only by examining these properties carefully that one begins to understand, for example, the appearance of an ‘unexpected’ operator, or the choice of one type of operator over another, or why a particular plan ‘pattern’ is used for one query but not for another, apparently very similar, query.
So, when need help tuning a slow query, you are often asked to right-click in the execution plan area, choose Save Execution Plan As, and then share the resulting .sqlplan file. This XML file provides all the information in the plan, including all properties. While this information is often essential for query tuning, you do need to know what you are sharing, or you might make the next data breach headlines!
What Data is Stored in the XML Plan?
Suppose you have a slow-running stored procedure and your attempts to resolve the problem fail, so you capture the execution plan, shown in in Figure 2, and send the associated .sqlplan file over to a friend (me), who you think can help.
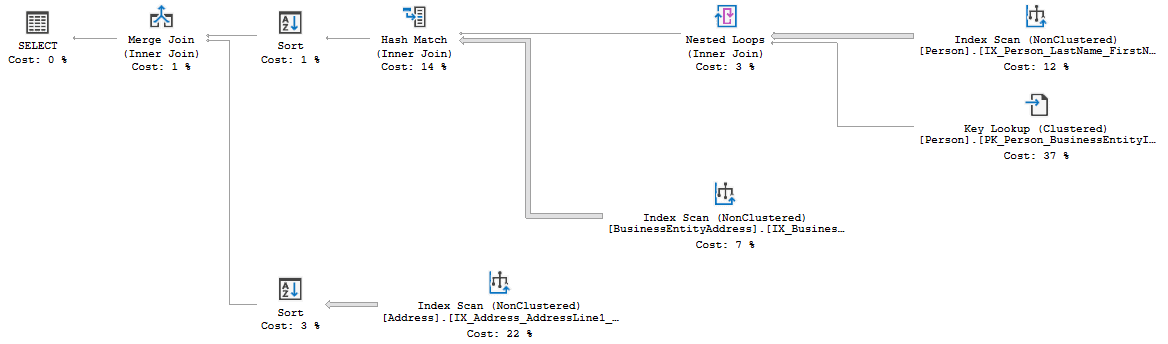
Figure 2
I now have a good chance of finding the issue and helping you, but you may have given me access to more information than you realized.
Data About Your Database
The XML plans reveals the same table names that the graphical execution plan already exposes, but there is a lot more information stored in the properties that I can now investigate. For example, I will now know:
- The full text of the query you executed (probably useful if you need help tuning it, but still something to be aware of)
- The names of every column that is somehow or somewhere used in the query
- How many rows you have stored in each of those tables
- The associated schema and database names of all tables used – these are revealed in the XML Plan but not the graphical plan
- The server names of any linked servers accessed by the query
- Assorted other information about your server and instance – for example:
- the actual number of rows is tracked per thread so I can see how many cores the query used
- looking in the plan for properties that were added in a recent SQL Server version shows me what service pack you are on
- the top-left operator includes information such as the full query text, memory available and used, and trace flags and
SEToptions in effect.
This type of data is pure gold for hackers! However, there is even worse news: you may also have revealed some of your users’ data.
Values in Your User Tables
Figure 3 shows the ToolTip properties window for the Index Scan on the Address table (in the lowest branch of the execution plan).

Figure 3
Look at the Predicate. It shows that this query will only return the rows where City = 'Perth'. This value is hardcoded in the query, so I can conclude that you have a stored procedure built specifically for Perth, and so Perth probably has some specific importance to the company.
Is it bad that this information leaks? Well, that depends on what actual values from what actual databases are included in the execution plans you share. It may be innocent, or it may be a huge data leak.
I’ve seen execution plans for queries that are dynamically generated. Some of these are not properly parameterized but have values hard-coded in the query. Where do these values come from? Perhaps they come from a client tool, so the plan reveals data that your users have entered. Alternatively, these values might come from another table, if you have a client application that reads from one source and then uses that information to build the next query, and so the execution plan contains actual values from your user tables.
It doesn’t stop there. Look at the values for the Number of Rows Read and Actual Number of Rows properties, in Figure 3. This tells me that out of a total 19,614 rows there are currently 80 rows in the Address table where City = 'Perth', so that accounts for 4% of your business. Still happy to share this plan?
Let’s move to the top left of the execution plan and focus on some of the properties of the SELECT operator. Figure 4 shows just one section of the full property window, which reveals even more information than the ToolTip popup.
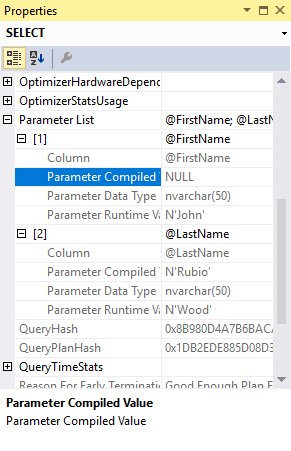
Figure 4
I have expanded the Parameter List property. It shows that this query uses two parameters, @FirstName and @LastName. However, the real issue here is that it also exposes some values, two for each parameter: Parameter Compiled Value and Parameter Runtime Value.
If you have ever investigated parameter sniffing, you will be aware of the importance of these properties for query tuning, so when you send me this plan for tuning your code, I want to see this information. However, beware, because this is most likely actual user data!
I now know that, when you ran the query to get the plan in Figure 2, you passed in the values John and Wood for first and last name, and that when the procedure originally executed, it was called for last name Rubio and first name NULL, which given the query means ‘filter on last name only’. These values probably come from an employee searching for the records of a customer that’s on the phone, or a customer requesting their own data on a web form, or a program iterating over values retrieved from another source. In any case, I know the names of two of your customers and that’s personally identifiable information that you probably did not want to leak.
More Values…and Their Cardinality
And it gets even worse. Let’s look at another operator, the Index Scan on the Person table, on the top right of the execution plan. Figure 5 shows its properties.
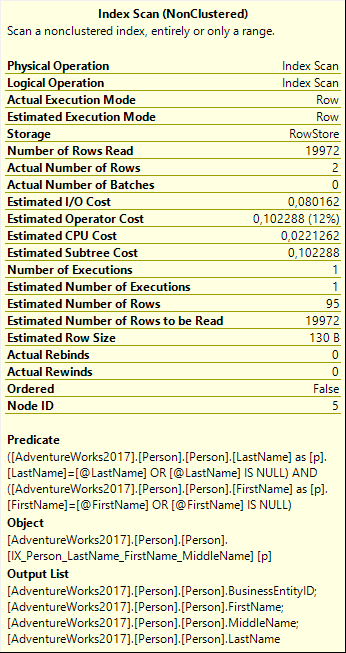
Figure 5
In this scan, the Predicate property does not show hardcoded values; it uses the @FirstName and @LastName parameters we saw before. By using the two sets of values for these parameters that we found in the Parameter List property and combining that with the information in Figure 5, I can find out even more about your data.
Remember that when this query executed, the name passed in was John Wood. Now look at the Actual Number of Rows property and you see that currently exactly two persons with that name are in the table. But there is even more! We also saw that this plan was optimized for the sniffed parameter values of last name Rubio and first name NULL. Now, look at the Estimated Number of Rows property: 95. This shows that the optimizer expected to find 95 people with last Name Rubio. While this is only an estimate, it does give me a fair idea how often this last name appears in your database.
If I want to go even deeper, I can inspect the OptimizerStatsUsage property of the SELECT operator to double check how long ago you last updated the statistics on this column, and with what sampling percentage. In this case they were updated with a full scan, but several months ago, so I’d have to apply some margin of error to these cardinality estimations.
Following the Data
Just by looking at the properties of a single operator alone, I was already able to find out that there are two people named John Wood in your database and that, based on somewhat dated statistics, the optimizer expected to find 95 people named Rubio. So how much more can I find if I looks at how the values of some of these properties change, across the plan?
Figure 6 shows the top left part of the execution plan, with the Estimated and Actual Number of Rows flowing between operators exposed.
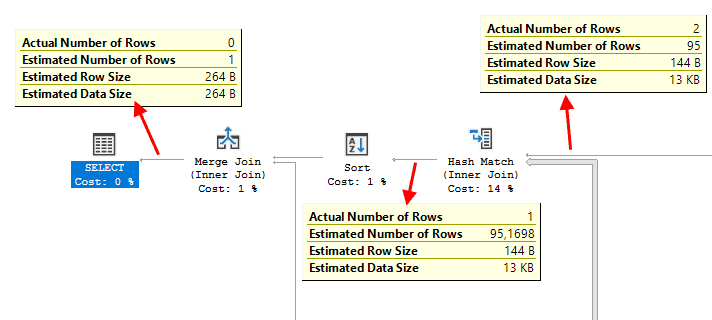
Figure 6
To the right we see the data that originated in the Index Scan on the Person table. We already saw the numbers, 2 and 95, and what I was able to infer from this. Let’s now follow the data flow and look at changes in the actual number of rows coming into and out of the join operators.
It starts with the Hash Match where the rows from the Person table are joined to data coming from the BusinessEntityAddress table. The Actual Number of Rows changes from 2 to 1, so you do have an address registered for one of the two John Woods in your database, but not for the other one. Conversely, looking at how the Estimated Number of Rows increases from 95 to 95.1698, I can deduce that, based on the statistics that SQL Server collected in your own database, there are apparently very few people with more than one registered address.
The Merge Join on the right does the final join, to data from the Address table, filtered on the City = 'Perth' predicate. We already know (from figure 3) that there are 80 such rows. But since the Actual Number of Rows after the Merge Join is down to 0, meaning that none of these are for John Wood. Apparently, the John Wood in your database that you do have an address for does not live in Perth. If he had, the Actual Number of Rows after the Merge Join would have been 1.
For the record, the fact that the Estimated Number of Rows after the final Merge Join is 1 does not tell me anything. Even if all Rubios in your database are living in Perth, it would not affect this estimate. The cardinality estimator has no knowledge of correlation between different tables, so this estimation is based on a generic assumption.
Can we Share XML Plans Safely?
To recap: from this XML plan, without having any access to your database, I was able to conclude that 4% of your business is in Perth, that two of the people in your Person table are called John Wood, but you only have an address for one of them and it’s not in Perth. I also learned that roughly 95 people in your database have last name Rubio, but this is based on outdated statistics so I should apply a large margin of error here. Oh, and only a very small fraction of the people in your database have more than a single address registered.
Now is this bad? That, once more, depends. What exact values are included in the execution plan? If it’s just a common last name, you are probably fine. But what if your database stores addresses of famous actors, and the execution plan reveals that a specific actor lives in a small village? Or, what if we had also passed in the Social Security Number as one of the parameters, and we would now know that you have one John Wood on file with SSN 123456789?
This is a harder issue to fix. We can edit the hard-coded values in our queries to fantasy values. We can also change the values passed into stored procedures, and parameterized SQL, so that they are random, meaningless values, like ‘LastName0001’.
The downside is that SQL Server then uses those values during optimization, and you’ll likely get a different execution plan. It’s safe to post now, but not remotely like the one with which you needed help.
A better, but harder, approach is to edit the .sqlplan file. It is just XML data, so you can open it in a text editor, find all user data and replace it. Find every reference to “Rubio” and replace them all with “Lastname1”. Then replace each “Wood” with “Lastname2”. And so on. Ensure you are consistent: do not replace one instance of “Rubio” with “Lastname1” and another instance of “Rubio” with “Lastname2”, and do not replace two different last names with the same placeholder. The exact values do not matter for understanding the execution plan, but knowing whether values are the same or different does matter. Save the file, then check that you can still open and view the execution plan in SSMS to verify you didn’t butcher the XML. When sharing this execution plan, tell the recipient that you edited the plan to replace sensitive data values.
Obviously, you should only do this for values that you need to protect. If you are working on the sales data of Microsoft and your query has a filter on Product = 'SQL Server 2017', you are not leaking any data that is not already known, so don’t bother. However, if you there are a few filters that narrow it down to Server 2017 sales in 2018, in Germany within the education market segment, then the combination of those values and the Actual Number of Rows property values is probably strategic information on market share, to be kept far from the competition. You should obscure at least some of these values in the execution plan if you intend to share it.
Sharing Plans from Third Party Tools
Up to now, we’ve focused only on standard SQL Server tools, but many people use additional third-party tools. Some of these tools, like Redgate’s SQL Monitor, give you easy ways to find problem queries and access and share their execution plan, without changing any of the information stored within that plan. Others however have the option to collect even more information and store that along with the execution plan.
One example of the latter is SentryOne’s Plan Explorer. Do remember that I include this as an example. Whatever tool you are using might or might not do similar things, so this is just an illustration of the type of dangers you should look out for when using this and other tools. Beyond this, my advice is simply to contact the vendor, and ask them for full details on the information that is and isn’t included in any files their tools allow you to create and share
SentryOne’s Plan Explorer not only captures the execution plan, but also lets us collect various bits of runtime data and other additional statistics, as a query is running. This additional data, along with all the normal information stored in a .sqlplan file, can be saved as a Plan Explorer Session (.pesession) file.
This is a great file to have when query tuning because all that additional data may sometimes be exactly what you need to find out why a plan is running slowly, but you will not be surprised to learn, at this stage, that sharing this file entrails a risk of exposing sensitive data.
Of all the extra information that a .pesession file contains, the worst offender, in terms of the potential to expose sensitive data, is the Index Analysis tab. This tab includes the statistics histogram for each of the indexes used in the plan, as shown in Figure 6. You may not need this very often, but I have at times been able to respond to forum posts, and explain an execution plan, based on this very information.
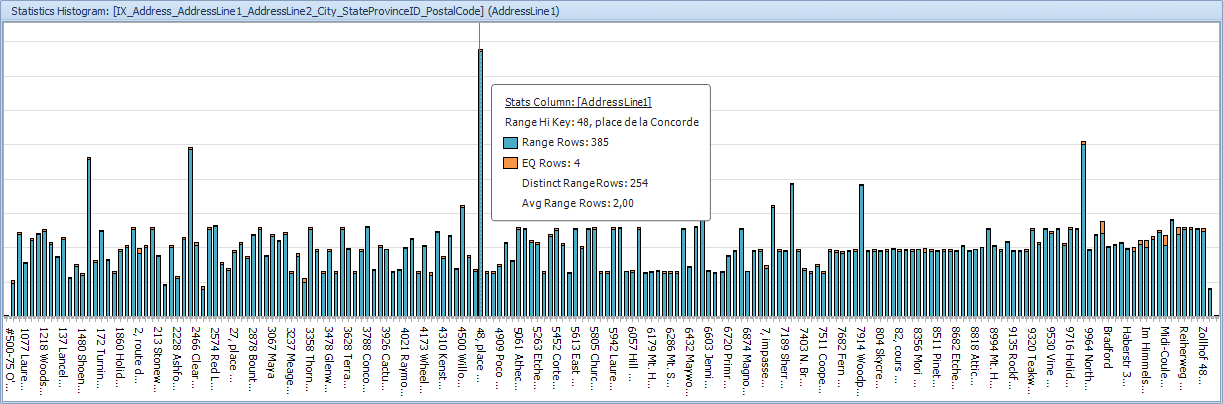
Figure 7
Here’s the rub: if you tested your query on production data, then the histograms included are all based on production data. Each of the values in the histogram (up to 200 values) comes from the actual table. And not only does the histogram contain these values, it adds a handy count of how often that value was seen, when the statistics were last updated.
In Figure 7, we can read directly that at that time the Address table had 4 rows with value “48, place de la Concorde”. I can hover my mouse over each of the bars in the histogram and get the information for each of the values that is represented in this statistics object. When you share a .pesession file, you share all that information. Whoops!
The fix is simple but radical: the tool has a built-in option to anonymize the execution plan. Use that, and it does some very hard scrubbing of the execution plan, removing all information from the Index Analysis tab, as well as all hardcoded values from the plan properties, and changing all column and table names. An anonymized version of our stored procedure plan, for example, will show only that the query uses two parameters (called Column13 and Column11), optimized for values Value3 and Value4 but called at runtime with values Value1 and Value2, and these are then used in an Index Scan on a table called Object3. So, with just a single click of a button it is now perfectly safe to share this execution plan with everyone.
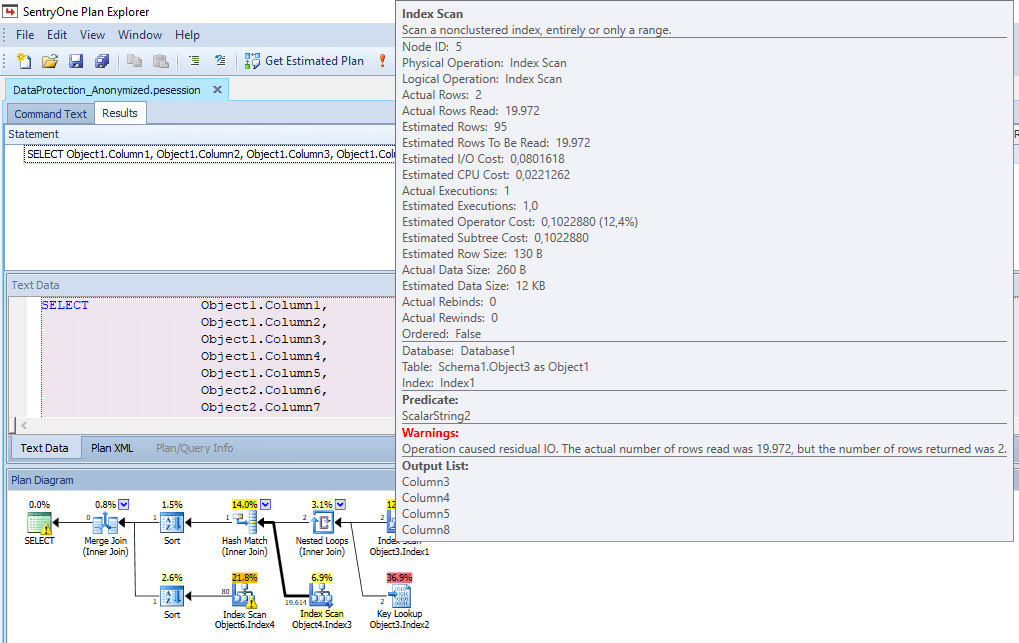
Figure 8
Of course, this comes at a price. An anonymized execution plan is almost impossible to tune and not because of the anonymized table and object names, per say. There are other issues. For instance, in the original plan the Predicate property on the Person table reveals that the query can filter on first and last name, but can also accept NULL values to return all first names or all last names, or both. In the anonymized plan, the Predicate expression has been replaced by a very nondescript “ScalarString2“. I no longer see what the predicate is, which means that if the predicate is part of the problem, I cannot help you find the problem if you share an anonymized plan.
Conclusion
All data professionals need help, occasionally, to understand or tune a ‘difficult’ query, and sharing its execution plan is the most effective way to get that help. The intent of this article is not to make you wary of sharing a plan, but rather to make you more aware of the need to verify what data the plan contains, before you share it, so that you avoid accidentally ‘leaking’ sensitive or personal information.
The extent of the action you need to take depends entirely on the data values that the execution plan contains. Reproducing the problem in a test environment with anonymized or made-up data, and changed object names, is the best choice, but not always feasible.
If you’re using real data, then it’s a relatively straightforward task to edit a .sqlplan file to anonymize table and object names, before sharing, and this on its own should not hamper the plan recipient too much.
However, there may be times when you need to remove or anonymize every piece of data stored in the plan. This is a harder task, and the catch is that you probably also removed some information that was key to fixing the bad performance!
There is no simple solution to this, but it’s only in the cases involving very sensitive data that you should consider not sharing the plan at all. Most of the time, you just need to remember to do a thorough check of all the information that is included in the plan, to make sure you are not exposing anything that should not be disclosed.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments