
We need search engines to query and analyse the massive amounts of data that many organizations are required to access: We have no great problem in storing it but how can we then find what we need? Large organizations store many types of structured and unstructured content such as documents in different formats, e-mails, CMS pages or Microsoft Office files. They want their employees and clients to be able to search and analyze it through one user interface.
At the same time, Internet users, who are used to Google-like search, expect every bespoke search to be as fast and precise: They need autocomplete, they assume that the search tolerates misspellings, and they expect to be able to use filters and many other advanced search features.
Many .NET developers might now ask: ‘Why would we need other search engines when we are happy with SQL Server’s Full-Text Search feature?’ The answer is that it might be enough for simple searches, but other search engines are a better choice when we need to index and search unstructured data from different sources or when we need custom functionality such as spellchecking, hit-highlighting, autocomplete or advanced scoring.
This is where search engines come into play. In order to get more familiar with the way they work, I will show how to build a search page that will query the dump of StackOverflow questions. The dump has considerable amount of data (7 million questions) and it is easy for developers to test the relevance of the search results. The search page will have following features:
- Full text search
- Grouping by tags
- Autocomplete
Why Elasticsearch?
Elasticsearch is an open source search engine, written in Java and based on Lucene. It is currently the most popular search engine.
It offers greater scalability than SQL Server’s full-text search: After all, Stack Exchange initially grew on SQL Server Full-Text Search, but the limitations of its feature and performance forced them migrate to Elasticsearch for their search requirements.
I decided to test Elasticsearch because it does not require that we create an up-front schema file and it exposes Web-friendly APIs (REST and JSON).
NEST
To interact with Elasticsearch, we will use NEST 2.3.0 which is one of two official .NET clients for Elasticsearch. NEST is a high-level client which maps closely to Elasticsearch API. All the request and response objects have been mapped. NEST provides the alternatives of either a fluent syntax for building queries, which resembles structure of raw JSON requests to API, or the use of object initializer syntax.
In order to build a web page, I will use Single Page Application (SPA) approach with AngularJS as MVVM framework. The client side will make AJAX requests to ASP.NET Web API 2. The Web API 2 controller will use NEST to communicate with Elasticsearch. 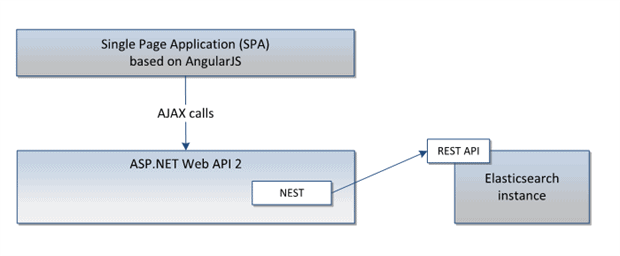
Code snippets in this article will only show the service implementation. Web API 2 code is just a boilerplate code so I decided to skip it, as well as the AngularJS code which you can replace with your favourite UI framework. The whole code is available on GitHub.
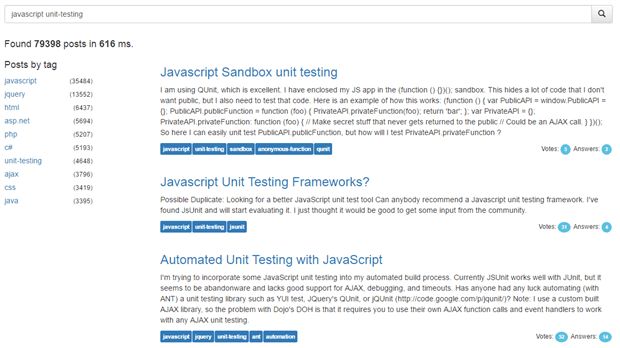
The page after applying HTML and styles may look like this:
Installation of Elasticsearch
Elasticsearch is very easy to install. Just go to its web page, download an installer, unzip it and install in three simple steps. Once it is installed, Elasticsearch should be available by default under http://localhost:9200.
It exposes a HTTP API so it is possible to use cURL to make requests but I recommend using Sense which is Chrome extension. Sense offers syntax highlighting, autocomplete, formatting and code folding. The Elasticsearch reference contains samples in cURL format: for example the request to get high level statistics for all our indices looks like this:
|
1 |
curl localhost:9200/_stats |
but Sense offers a nice copy and paste feature that translates cURL requests to the proper Sense syntax:
|
1 |
GET /_stats |
Search index population
Elasticsearch is document-oriented, meaning that it stores entire documents in its index. First of all we need to create a client to communicate with Elasticsearch.
|
1 2 3 4 |
var node = new Uri("http://localhost:9200"); var settings = new ConnectionSettings(node); settings.DefaultIndex("stackoverflow"); var client = new ElasticClient(settings); |
Next, let’s create a class representing our document.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class Post { public string Id { get; set; } public DateTime? CreationDate { get; set; } public int? Score { get; set; } public int? AnswerCount { get; set; } public string Body { get; set; } public string Title { get; set; } [String(Index = FieldIndexOption.NotAnalyzed)] public IEnumerable<string> Tags { get; set; } [Completion] public IEnumerable<string> Suggest { get; set; } } |
Although Elasticsearch is able to dynamically resolve the document type and its fields at index time, you can override field mappings or use attributes on fields in order to provide for more advanced usages. In this example we decorated our POCO class with some attributes (which I explain later) so we need to create mappings with AutoMap.
|
1 2 3 |
var indexDescriptor = new CreateIndexDescriptor(stackoverflow) .Mappings(ms => ms .Map<Post>(m => m.AutoMap())); |
Then, we can create our index called and put the mappings.
|
1 |
client.CreateIndex("stackoverflow", i => indexDescriptor); |
Now that we have defined our mappings and created an index, we can seed it with documents. Elasticsearch does not offer any handler to import specific file formats such as XML or CSV, but because it has client libraries for different languages, it is easy to build our own importer. As StackOverflow dump is in XML format, we will use .NET XmlReader class to read question rows, map them to an instance of Post and add objects to the collection. The field Suggest should be also populated with the same values as Tags, which will be explained later in the article.
Next, we need to iterate over batches of 1-10k objects and call the IndexMany method on the client:
|
1 2 3 4 5 6 |
int batch = 1000; IEnumerable<Post> data = LoadPostsFromFile(path); foreach (var batches in data.Batch(batch)) { client.IndexMany<Post>(batches, "stackoverflow"); } |
On my machine, i7 quad core with 16GB RAM and HDD drive, it took around two seconds to index each batch. Depending on size and structure of documents, you can increase batch size until the performance drops drastically.
Full text search
Now that our document database is populated, let’s define the search service interface:
|
1 2 3 4 5 6 7 |
public interface ISearchService<T> { SearchResult<T> Search(string query, int page, int pageSize); SearchResult<Post> SearchByCategory(string query, IEnumerable<string> tags, int page, int pageSize); IEnumerable<string> Autocomplete(string query, int count); |
and a search result class:
|
1 2 3 4 5 6 7 |
public class SearchResult<T> { public int Total { get; set; } public int Page { get; set; } public IEnumerable<T> Results { get; set; } public int ElapsedMilliseconds { get; set; } } |
The search method will execute the multi match query against user input. The multi match query is useful when we want to run the query against multiple fields. By using this, we can see how relevant the Elasticsearch results are with the default configuration.
First of all we need to call the parent Query method that is a container for any specific query we want to execute. Next, we call the MultiMatch method which calls the Query method with the actual search phrase as a parameter and a list of fields that we want to search against. In our case these are: Title, Body, and Tags.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
var result = client.Search(x => x // use search method .Query(q => q // define query .MultiMatch(mp => mp // of type MultiMatch .Query(query) // pass text .Fields(f => f // define fields to search against .Fields(f1 => f1.Title, f2 => f2.Body, f3 => f3.Tags)))) .From(page - 1) // apply paging .Size(pageSize)); // limit to page size return new SearchResult<Post> { Total = (int)result.Total, Page = page, Results = result.Documents, ElapsedMilliseconds = result.Took }; |
The raw request to Elasticsearch will look like:
|
1 2 3 4 5 6 7 8 9 10 11 |
GET stackoverflow/post/_search { "query": { "multi_match": { "query": "elasticsearch", "fields": ["title","body","tags"] } } } |
Grouping by tags
Once our search returns results, we will group them by tags so that users can refine their search. To group result by categories, we will use the bucket aggregations. They allow as to compose bucket of documents which falls into given criterion or not. As we want to aggregate by tags, which is a text field, we will use the term aggregations.
Let’s look at attribute on the Tags field
|
1 2 |
[String(Index = FieldIndexOption.NotAnalyzed)] public IEnumerable<string> Tags { get; set; } |
It tells Elasticsearch to neither analyze nor process the input, and to search against the field. It would store values as they are. Thanks to that, it would not change ‘unit-testing’ tag to ‘unit’ and ‘testing’ etc.
Now, we can extend the search result class with a dictionary containing the tag name and the number of posts decorated with this tag.
|
1 |
public Dictionary<string, long> AggregationsByTags { get; set; } |
Next, we need to add Aggregation, of type Term, to our query and give it a name.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
var result = client.Search<Post>(x => x .Query(q => q .MultiMatch(mp => mp .Query(query) .Fields(f => f .Fields(f1 => f1.Title, f2 => f2.Body, f3 => f3.Tags)))) .Aggregations(a => a // aggregate results .Terms("by_tags", t => t // use term aggregations and name it .Field(f => f.Tags) // on field Tags .Size(10))) // limit aggregation buckets .From(page - 1) .Size(pageSize)); |
The search results now contain aggregation results so we use the newly-added field to return it back to the caller:
|
1 2 |
AggregationsByTags = result.Aggs.Terms("by_tags").Items .ToDictionary(x => x.Key, y => y.DocCount) |
The next step is to allow users to select one or more tags and use them as a filter. Let’s add a new method to the interface. It will enable us to pass the selected tags to the search method.
|
1 |
SearchResult<Post> SearchByCategory(string query, IEnumerable<string> tags, int page, int pageSize); |
In the method implementation, first of all we need to map the tags into an array of filters.
|
1 2 3 |
var filters = tags .Select(c => new Func<FilterDescriptor<Post>, FilterContainer>(x => x .Term(f => f.Tags, c))); |
Then, we need to build our search as a bool query. Bool queries combine multiple queries with must or should clauses. The queries inside clauses will be used for searching documents and applying a relevance score to them.
Then we can append a Filter clause which also contains a Bool query which filters the result set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
var result = client.Search<Post>(x => x .Query(q => q .Bool(b => b .Must(m => m // apply clause that must match .MultiMatch(mp => mp // our initial search query .Query(query) .Fields(f => f .Fields(f1 => f1.Title, f2 => f2.Body, f3 => f3.Tags)))) .Filter(f => f // apply filter on the results .Bool(b1 => b1 .Must(filters))))) // with array of filters .Aggregations(a => a .Terms("by_tags", t => t .Field(f => f.Tags) .Size(10))) .From(page - 1) .Size(pageSize)); |
The aggregations work in the scope of a query so they return a number of documents in a filtered set.
Autocomplete
One of the features that we frequently use in search forms is autocomplete, sometimes called ‘typeahead’ or ‘search as you type’.
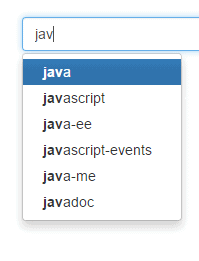
Searching big sets of text data by only a few characters is not a trivial task. Elasticsearch provides us with the completion suggester which works on a special field that is indexed in a way that enables very fast searching.
We need to decide which field or fields we want autocomplete to operate on and what results will be suggested. Elasticsearch enables us to define both input and output so, for example, user text can be searched against title or author and return a term or even the whole post or subset of its fields.
For simplicity, in our case we will search user input against the tags and display matched tags as well. It will work as a dictionary of tags. That is why we decorated our Post class with a special attribute.
|
1 2 |
[Completion] public IEnumerable<string> Suggest { get; set; } |
The field decorated with Completion may contain Input, Output, Payload (which can store any arbitrary object) and Weight that ranks suggestions. We will use only mandatory input so the type will be a collection of strings.
Now we can implement an autocomplete method:
|
1 2 3 4 5 6 7 8 |
var result = client.Suggest<Post>(x => x // use suggest method .Completion("tag-suggestions", c => c // use completion suggester and name it .Text(query) // pass text .Field(f => f.Suggest) // work against completion field .Size(count))); // limit number of suggestions return result.Suggestions["tag-suggestions"].SelectMany(x => x.Options) .Select(y => y.Text); |
The method will return a collection of terms that match the query. The result of particular suggestion is a collection of suggestion options. We may order them by frequency or weight (which we did not defined) and return the suggested text.
Summary
This article demonstrated how to build a full text search functionality that includes grouping results by tags and an autocomplete feature.
We have seen that the installation and configuration of Elasticsearch is very easy. The default configuration options are just right to start working with. Elasticsearch does not need a schema file and exposes a friendly JSON-based HTTP API for its configuration, index-population, and searching. The engine is optimized to work with large amount of data.
We used a high-level .NET client to communicate with Elasticsearch so it fits nicely in .NET project. It allowed us to define our index using POCO classes with little configuration work. We also choose to use a fluent syntax to build queries, but object initializer syntax is also available.
Finally, we have extended our search with two functionalities with not much effort. Having implemented a search service, we can now hook it up with either Web API with AngularJS or ASP.NET MVC.
Elasticsearch is an advanced search engine with many features and its own query DSL. Before we can build a production search site, we would require more analysis on how to store and query our data and fine tuning queries but I hope this article helped you to learn the basics in examples.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments