
This article explains about how the data modifications is handled by Cassandra, to handle Update’s and Delete is effectively we need to first understand the Write Path and the Read Path in Cassandra.
The Write Path
When a write request (insert) is received is by Cassandra, the data will be stored in Memtable & Commit Log simultaneously. Imagine Memtable as data cache, once the Memcache is full, data is flushed out (written) to the SSTable. Below diagram showcases how writes are handled by Cassandra.
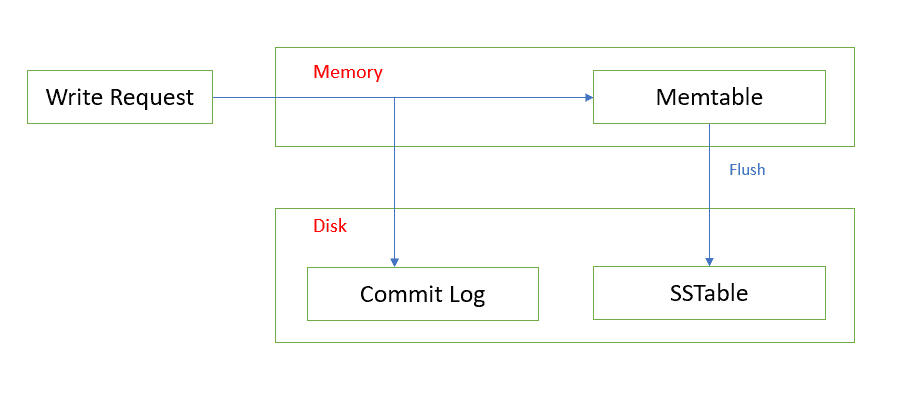
Memtable – Memtable is an in-memory cache (RAM), it is like Hash Table data structure where contents are stored as key-value pairs. When a Memtable exceeds the configured size, a flush is triggered which moves data from Memtable to SSTable. If we need to change the default Memtable configuration size, we need to modify the field ‘memtable_total_space_in_mb’ in Cassandra.yaml file
Commit Log- Whenever any write operation is handled by Cassandra, the data is simultaneously written to both Memtable & Commit Log. The main purpose of Commit Log is to recreate the Memtable in case if a node gets crashed, Commit Log is a flat file which is created on Disk. Once the Memtable is full, the data will be flushed (written) to SSTable that’s when data will be Purged from Commit Log as well.
Commit Log files can be found under ‘/data/commitlog/CommitLog-***.log’
To change the default Commit Log configuration, we need to modify the ‘commitlog_total_space_in_mb’ field in Cassandra.yaml file.
We can manually flush the data from Memcache to SSTable using ‘nodetool’ command.
SSTable (Sorted Strings Table) – SSTable a flat file of Key-Value pairs which is sorted by keys and it is used by Cassandra to persist the data on the disk, SSTable files are immutable, each SSTable contains a sequence of blocks where by default each block is of 64 KB size and it can be configured.
On the disk, SSTable can be found under data folder with the name ‘/data/data/keyspace/table/*-Data’.db
Compaction: The processing of merging of various SSTables to fewer SSTables is known as Compaction. Compaction is essential process in Cassandra because every operation except ‘select’ is a write in Cassandra and every write happens with a new Timestamp for every Insert, Update and Delete. More details about compaction is provided later in the article.
How Data is Stored:
When data is written in Cassandra, the Partitioner (Murmur3 by default) generates a token which is a hash value, based on generated hash value a node is also identified in a cluster where the data is going to be stored, in a nutshell Partitioning key is a hash value generated by Cassandra’s Murmur3 Partitioner. During the ‘select’ operation, again the node / partition is identified, and the data is retrieved.
To understand how Cassandra stores the data, consider a table where column ‘Name’ is the Partitioning Key.
|
NAME |
DATETIME |
COUNTRY |
COUNT |
|
VZ |
2020-08-01 01:00:00 |
US |
30000 |
|
TM |
2020-08-04 04:00:00 |
US |
90000 |
|
VZ |
2020-08-05 03:10:10 |
EU |
10000 |
Internally Cassandra stores the data as row-key value
|
VZ |
2020-08-01 01:00:00 US 30000 |
2020-08-05 03:10:10 EU 10000 |
|
TM |
2020-08-04 04:00:00 US 10000 |
Keep in mind that Row-key, Primary Key & Partitioning Key are synonyms.
The Read Path
In Cassandra, data may be stored in various locations like Commit Log, ‘n’ number of SSTables. But Commit Log is used to recreate the Memtable in case of any node crashes, that’s why in the read path it’s not important to go in details of Commit Log.
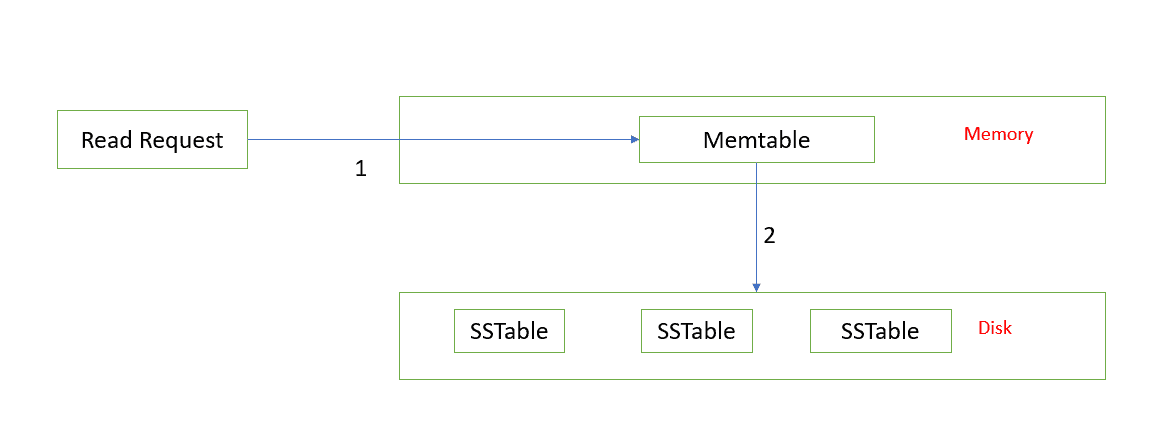
When Cassandra receives the read request, data will be searched first in the Memtable, then data will be searched in SSTables and if data exists it is returned.
Consider below table which represents the read operations performed against a table named ‘User’, where Partitioning Key is the ‘user_id’ and Timestamp is the time when the data is written to the Cassandra, the Data Location column represents where the data is currently located in Cassandra.
|
SEQ |
user_id |
user_name |
Timestamp |
Data Location |
|
1 |
10 |
David P |
TS – 300 |
Memtable |
|
2 |
20 |
Tim K |
TS – 250 |
Memtable |
|
3 |
20 |
Nick |
TS – 220 |
SSTable |
|
4 |
10 |
David |
TS – 190 |
SSTable |
|
5 |
20 |
Tim |
TS – 135 |
SSTable |
In the table we can see that Sequence 1 and 4 has the same info but timestamp is different, similarly in the Sequence 2,3 and 5 also has the same details except the timestamp. In this case, Cassandra compares the Timestamp of the records which has same details and the one with the latest timestamp is returned. Because, Cassandra uses Timestamp to resolve conflicts between the data which is stored in Memtable or SSTable.
On execution of the below queries, the data with the latest timestamp in the table will be returned and other records will be ignored after Timestamp comparison.
select * from table where user_id = 10
|
10 |
David P |
TS – 300 |
Memtable |
select * from table where user_id = 20
|
20 |
Tim K |
TS – 250 |
Memtable |
There is a possibility that Memtable contains the multiple entry of same the record, in this case also the record with the latest timestamp is returned.
Similarly, if the data is flushed from Memtable to SSTable, say a record is scattered across SSTables then also the timestamp is compared and the record with latest timestamp is returned.
Update
When Cassandra receives an Update request, it never validates first whether data exists or not to update the data like it happens in SQL world. Instead, Cassandra creates a new record every time when an Update command is received by Cassandra, in a nutshell Update request is an Upsert operation in Cassandra.
Please keep in mind that, In Cassandra except ‘select’ every operation is a write including Deletes.
Scenario1: Let’s execute update query on the user table and create a new record which never exists in the system.
update user set user_name=’Mick’ where user_id=30;
select * from user;
result:
user_id | user_name
———+———–
10 | David P
30 | Mick
Note: ‘select * from user’ query is not very efficient, whenever the data is retrieved from Cassandra, Partitioning key is always expected in the where clause. If Partitioning key is not given, then most of the time query will be Timed out, because Cassandra needs to coordinate with every node to return the data and the default time out in Cassandra is 10 seconds. I have used that query as an example because I have a limited data.
Scenario 2: On modifying an existing user, let’s check whether a new record is created or the existing one is updated.
update user set user_name=’David P’ where user_id=10;
In the read-path section we have seen that Cassandra uses Timestamp to resolve the conflict, since user table already had an entry for user_id=10, on receiving the update query request, Cassandra must have created another record for the same user_id. To verify that, let’s flush the records from the Memtable and verify the SSTable, to do that execute nodetool command which is
‘nodetool flush KEYSPACE TABLE’
After executing the nodetool command, with the help of ‘sstable2json’ or ‘sstabledump’ (windows equivalent) command, SSTable records are returned to us as a JSON. On my system, there are 2 SSTable files are created, first one with the name ‘mc-1-big-Data’ contains json record captured in a Screenshot.
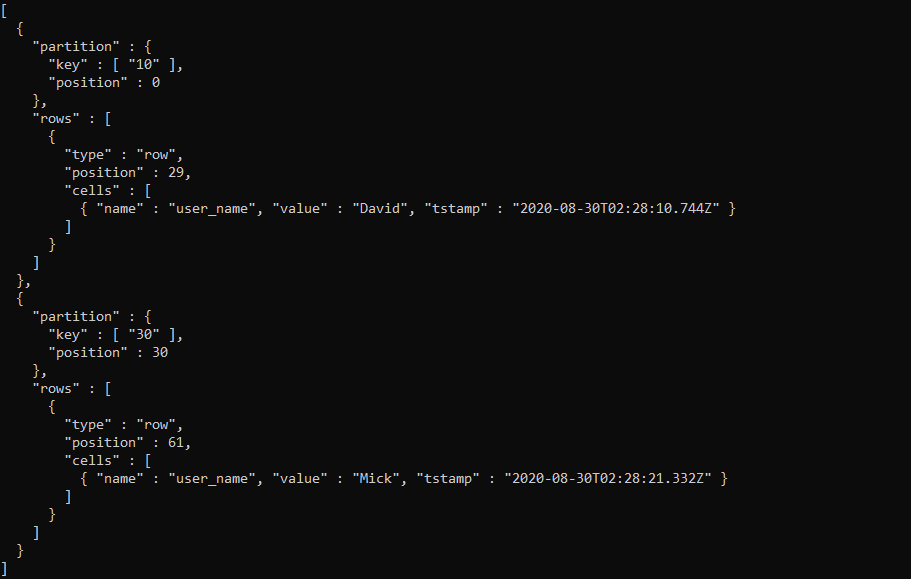
and the second with the name ‘mc-2-big-Data’ contains the record, which was created using update query. The second file is created after I manually flushed the data from the Memtable to SSTable
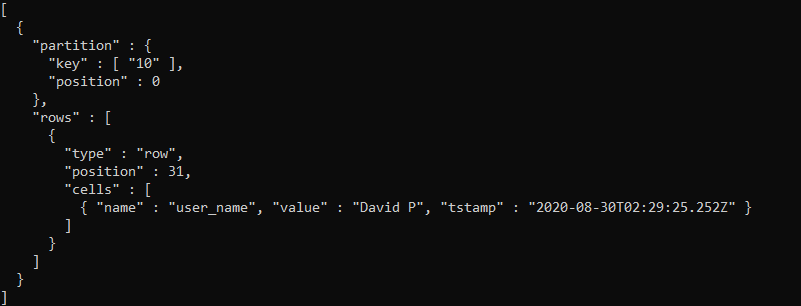
On executing the select query, Cassandra returns the record with the latest timestamp, In the JSON above for the key 10, there are 2 entries one with timestamp ‘2020-08-30T02:28:10.744Z’ and the other one with timestamp ‘2020-08-30T02:29:25.252Z’ which is clearly the latest, hence on executing the select query the record with the latest timestamp is returned.
select * from user where user_id=10;
result
user_id | user_name
———+———–
10 | David P
Delete
When Cassandra receives a delete request, it creates a tombstone, tombstone means it marks the record for deletion. Tombstone is just another JSON field which is a timestamp.
Let’s delete a record from the system
delete from user where user_id=30;
On flushing the data from Memtable to SSTable and check the JSON record,

‘deletion_info’ key is a Tombstone.
Cassandra doesn’t delete the record immediately because if the deletion happens immediately and a replica node is down, once the node is back-up there is a possibility that it replicates the data to the nodes that had previously deleted it, because this node is unaware of the delete. Usually there are lots of nodes in the cluster (100s) and it is a usual scenario. The below diagram indicates that it is a 6 nodes cluster and the node 4th is down. Once the 4th node is up it may replicate the data to other nodes.
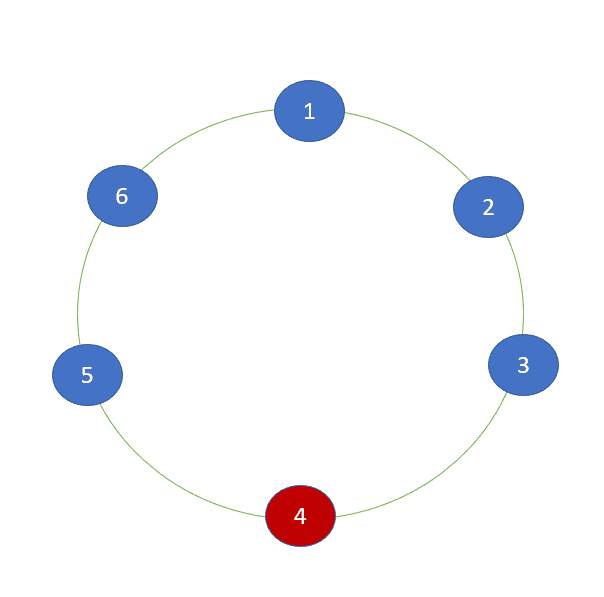
The minimum amount of time taken by the delete is set in ‘gc_grace_seconds’ field of the table, the default value of ‘gc_grace_seconds’ is 864000 seconds which is 10 days. Once the gc_grace_seconds is crossed, the data gets eligible for deletion and during compaction the data is deleted from the System.
Compaction is a process in which multiple SSTables are combined to improve the performance of the reads. For example, if there are 8 SSTables, during Compaction all the 8 SSTables are combined to fewer tables (2 SSTables). Usually compaction happens when the 4 SSTables files are created and then all 4 are combined to one.
Compaction brings two benefits, first the read query performance will be improved as now Cassandra needs to read only fewer SSTables, second benefit is the disk space is reclaimed.
Compaction happens automatically but it can be done manually also using ‘nodetool compact’ command.
‘nodetool compact KEYSPACE TABLE’
TTL
Time To Live (TTL) is a way of setting an expiration date in seconds for the data which is being written. TTL records are also marked like Tombstones and the flow is same as Delete, that once the ‘gc_grace_seconds’ is passed and after compaction data is deleted from the system.
Let’s understand by an example
insert into user (user_id, user_name) values (20, ‘Mark’) using ttl 30
On executing the select query, following rows will be returned.
user_id | user_name
———+———–
10 | David P
20 | Mark
After flushing the data from Memtable to SSTable, we can see that in the JSON file, the newly created record with a ‘ttl’ key set to 30 which means that data is set for expiration after 30 seconds.
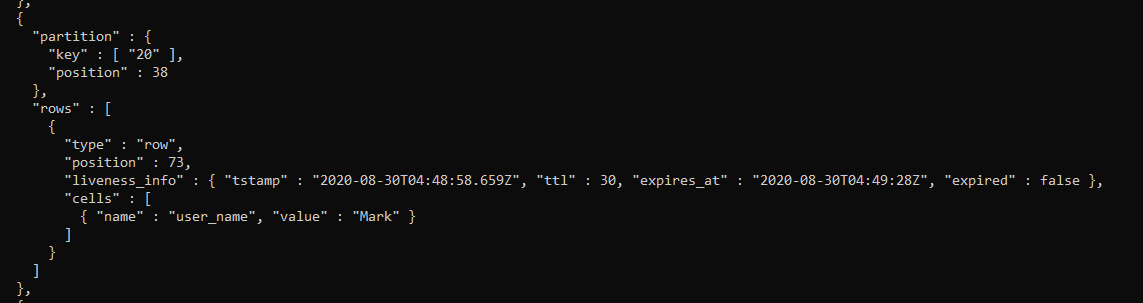
On executing select query after 30 seconds, Cassandra removes the record
user_id | user_name
———+———–
10 | David P
But the data from the disk will be remove only after ‘gc_grace_seconds’ is passed, and compaction is completed.
Updating TTL
TTL of a record can be updated using Update query, let’s insert a record
insert into user (user_id, user_name) values (40, ‘ROB’)
select * from user
Records in the table
user_id | user_name
———+———–
10 | David P
40 | ROB
If we want to set an expiration to any column of the record, we can do it by using Update query with Using TTL clause. First, let’s update the record using Update query
update user using ttl 40 set user_name=’ROB’ where user_id= 40
execute select query after 40 seconds,
select * from user
Records in the table
user_id | user_name
———+———–
10 | David P
40 | null
The above query will set only user_name field as ‘null’ & in Cassandra if any column has ‘null’ values that record is marked with Tombstone.
Record can be set for expiration even with Insert query, if we want to remove the entire row using TTL approach
Conclusion
If we setup Cassandra locally and understand the file structure, like Filter, Index, Statistics, Summary, Data etc. working with Cassandra becomes lot more easier, executing nodetool flush command & compact command gives us a better insight on how data is updated and how Cassandra creates tombstones for deletion.
It becomes extremely important to understand the Read Path, Write Path, Update and Delete basics specially if we are using Cassandra as the backend for any web application, better understanding of these basics helps us in designing better data models.
Sameer Shukla
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments