


T-SQL Notebooks is one of the new features announced during FabCon Europe.
The most distracted could miss the fact this is a new feature at all. Yes, it is. Notebooks were capable to support Spark SQL, but T-SQL is something new.
The main examples being announced are built with data warehouses, but let me confirm and highlight this:
T-SQL Notebooks support lakehouses as well.
There is at least one limitation: DML is not supported with lakehouses.
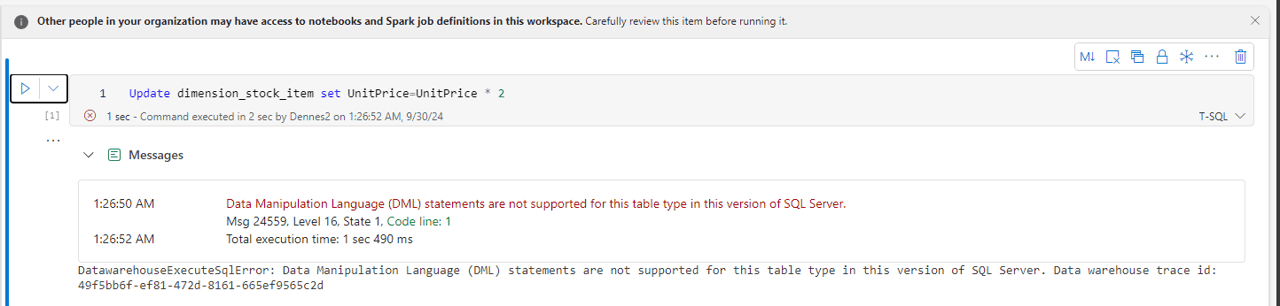
Let’s start from the beginning.
The T-SQL Notebooks UI
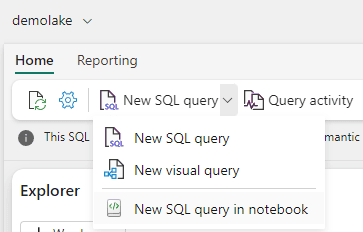
The easiest way to create a T-SQL notebook is using the button “New Query” at the top of a lakehouse of Data Warehouse. The button has options, and the new one is “New SQL Query in Notebook”
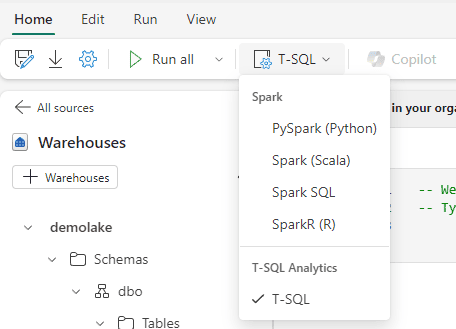
Once the notebook is created, it’s like a regular notebook. You can change the notebook type at the top if you want, but T-SQL is already selected by default.
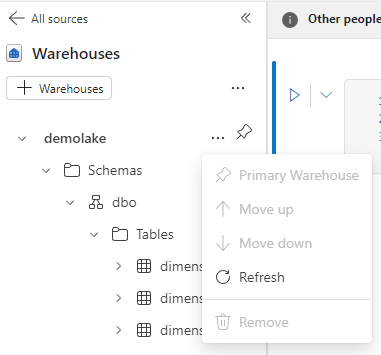
It has an explorer of warehouses attached, but they can be lakehouses as well. Exactly as in a regular notebook, you can set a default when there are many sources attached. The name of the option is different: “Primary Warehouse”.
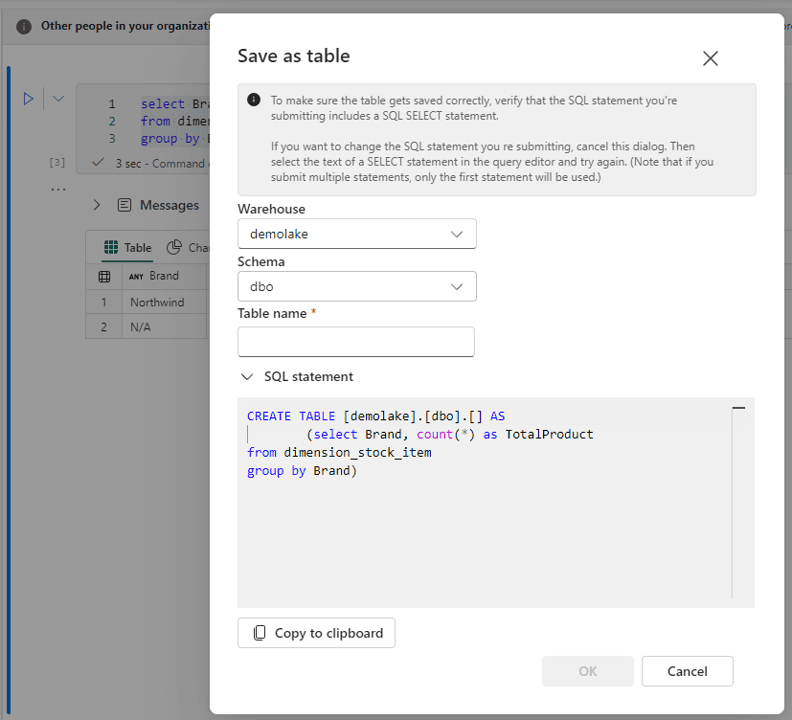
Another interesting feature is the button “Create Table”, allowing to transform any SQL query created in the notebook in a new table
Scheduled Tasks for Warehouses
When using the T-SQL notebooks with warehouses, they can be used for the most expected purpose: You can create scheduled processes using the notebooks.
In this way, a team who choose to work with a warehouse doesn’t need to use pySpark to schedule something, they can use pure T-SQL.
Version Control for Lakehouse T-SQL Objects
I suffer with this problem right now, in a solution I work on. How to make version control of lakehouse objects, especially views?
The creation of views is made using the queries created in the SQL Endpoint UI. There is no way to make a version control of these queries.
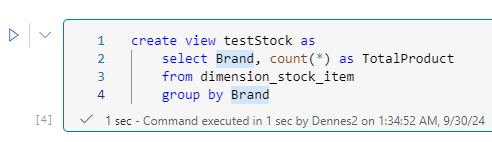
T-SQL notebooks support the creation of views. We can replace the queries in SQL Endpoints by T-SQL notebooks. We can add them to source control and in this way control the version of the views.
Of course, the notebooks also support deployment pipelines. We can easily use DevOps to create a release pipeline promoting the notebook from one stage to another, executing it in the new stage and making a commit in the workspace.
Summary
This is a great advance in source control, and a very unexpected one: While thinking about making an advance on processing creation for a data warehouse, a great advance in source control for lakehouses was also achieved
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments