
SQL Server Row-Level Security adds overhead to every query against a protected table – the overhead level depends on two factors: how the access predicate authenticates the user (the authentication method), and how well the access predicate function is tuned (indexes, denormalization, join complexity). This article – Part 3 of the full deep-dive Row-Level Security in SQL Server series – covers both.
Authentication performance compares the six RLS methods – SESSION_CONTEXT is the fastest, AD group lookups add external overhead, and direct user name lookups don’t scale at high user counts. Authorization performance covers the core access predicate tuning principle: keep the predicate function simple, flat, and well-indexed – every join added to a predicate degrades performance at scale. The troubleshooting section covers the most common ETL and service account RLS issues: ghost records (rows invisible to an under-privileged service account), excess deletes in anti-join patterns, and service account RLS bypass strategies.
A brief introduction
Previous sections gave a brief introduction to RLS, including some common use cases. They also showed how to implement RLS using a few different methods. This section focuses on performance and potential issues you may encounter.
There are two main areas where RLS can impact performance. The first is the user or authentication lookup. Some kind of lookup must be performed in the access predicate to determine either the user name, group membership, or specific values in the session context. Considering that RLS is non-prescriptive, the lookup isn’t confined to these methods, but they are very easy methods to use and implement and are standard based on implementations I’ve seen.
The second area is the authorization lookup. The authorization lookup, checking if a user has access to particular rows, can have a much bigger impact on performance. This is also in the access predicate. Following the basic rules for performance and keeping lookups simple goes a long way to minimizing the impact of RLS on performance. The goal is to keep performance levels as close as possible to a table without RLS. If indexes and predicates are correct, RLS can improve performance in some situations due to the automatic filtering that happens.
Authentication Performance
This section focuses on authentication performance. As you look at authentication performance, don’t forget about ease of implementation. Some of the methods below scale better than others, from a management perspective, since they are easier to add new users or add new RLS criteria. This will differ based on your environment and solution, but be sure to consider ease of management when you select a method.
You may also be interested in: SQL Server RLS setup – access predicates and security policies (Part 2)
Session context
Using session context is a relatively lightweight solution that works well if you have a good method to consistently set the SESSION_CONTEXT. The session context lookup is very fast and is similar to the role lookup solutions below.
I expected SESSION_CONTEXT to have the most potential for performance issues, but testing indicates no issues. In fact, it was the fastest method by far. Performance isn’t the only consideration for your architecture. Maintenance considerations are probably a higher priority, as long as non-functional requirements (NFRs) are met for performance. As long as you test your usage, and keep the implementation simple, SESSION_CONTEXT performs well.
Active Directory Group Membership
Active Directory or Azure Active Directory group membership has to perform a lookup outside of the SQL Server environment. Even with this lookup, it is a fast lookup process. This fits well for smaller implementations or specific security overrides in the access predicate, such as db_owner groups.
|
1 |
SELECT IS_MEMBER(‘Domain\Group’) |
SQL Server User Role Assignment
User role assignment is similar to group membership lookups. This is part of the method used in the WideWorldImporters example database. It generally scales better than group lookups from an administrative standpoint. You don’t need to add multiple active directory groups and train teams on their usage. It might be more difficult to ensure a pattern exists for the group depending on enterprise standards.
|
1 |
SELECT IS_ROLEMEMBER(‘RoleName’) |
User Name Lookup
Direct user name lookups aren’t scalable from a maintenance perspective but are useful when combined with other methods. This can be especially useful for administrators or service accounts in conjunction with other methods, such as SESSION_CONTEXT.
|
1 2 |
SELECT USER_NAME() SELECT SUSER_NAME() |
Performance Comparison
I did a quick test comparing the authentication methods listed above. It isn’t a definitive test, but I ran it many times and it was very consistent between runs. Once you get above 10,000 executions it levels out. There isn’t a huge difference between the fastest and slowest execution time for 1 million executions, under 300 milliseconds, but you can see the difference below. Your implementation may vary so be sure to performance test and tune as you implement. It was interesting to see that with 100 thousand executions, the SESSION_CONTEXT lookup had a run time of 0 milliseconds and is the reason I increased to 1 million executions.

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 |
SET STATISTICS TIME ON SET STATISTICS IO ON GO --GRANT SELECT ON SCHEMA::RLS TO RLSLookupUser DECLARE @AuthTime TABLE ( AuthTimeID int NOT NULL PRIMARY KEY CLUSTERED identity ,AuthType varchar(25) NOT NULL ,AuthStart datetime NOT NULL ,AuthEnd datetime NOT NULL ,AuthCount int NOT NULL ) DECLARE @StartTime datetime ,@EndTime datetime ,@AuthCount int ,@AuthType varchar(25) EXECUTE AS USER = 'RLSLookupUser' SELECT @StartTime = GETDATE() ,@AuthType = 'User Name Lookup' SELECT TOP 1000000 * INTO #RLSLookupUser FROM RLS.UsersSuppliers UP CROSS JOIN dbo.Numbers N WHERE UP.UserId = USER_NAME() SELECT @EndTime = GETDATE() ,@AuthCount = @@ROWCOUNT REVERT INSERT INTO @AuthTime ( AuthType ,AuthStart ,AuthEnd ,AuthCount ) VALUES ( @AuthType ,@StartTime ,@EndTime ,@AuthCount ) DECLARE @ROLES TABLE ( RoleName varchar(255) ) INSERT INTO @ROLES ( RoleName ) VALUES ('db_datareader') ,('db_datawriter') ,('db_owner') SELECT @StartTime = GETDATE() ,@AuthType = 'Role Lookup IS_MEMBER' SELECT TOP 1000000 * INTO #ISMEMBER FROM @ROLES R CROSS JOIN dbo.Numbers N wHERE IS_MEMBER(R.RoleName) = 1 SELECT @EndTime = GETDATE() ,@AuthCount = @@ROWCOUNT INSERT INTO @AuthTime ( AuthType ,AuthStart ,AuthEnd ,AuthCount ) VALUES ( @AuthType ,@StartTime ,@EndTime ,@AuthCount ) SELECT @StartTime = GETDATE() ,@AuthType = 'Role Lookup IS_ROLEMEMBER' SELECT TOP 1000000 * INTO #ISROLEMEMBER FROM @ROLES R CROSS JOIN dbo.Numbers N wHERE IS_ROLEMEMBER(R.RoleName) = 1 SELECT @EndTime = GETDATE() ,@AuthCount = @@ROWCOUNT INSERT INTO @AuthTime ( AuthType ,AuthStart ,AuthEnd ,AuthCount ) VALUES ( @AuthType ,@StartTime ,@EndTime ,@AuthCount ) BEGIN TRY EXEC sp_set_session_context N'RLSRegion', 'Central', 1 END TRY BEGIN CATCH PRINT 'SESSION ALREADY SET' END CATCH SELECT @StartTime = GETDATE() ,@AuthType = 'Session Context' SELECT TOP 1000000 * INTO #SESSIONCONTEXT FROM dbo.Numbers N WHERE SESSION_CONTEXT(N'RLSRegion') = N'Central' SELECT @EndTime = GETDATE() ,@AuthCount = @@ROWCOUNT INSERT INTO @AuthTime ( AuthType ,AuthStart ,AuthEnd ,AuthCount ) VALUES ( @AuthType ,@StartTime ,@EndTime ,@AuthCount ) SELECT * ,DATEDIFF(ms,AuthStart,AuthEnd) TotalTimeMS FROM @AuthTime DROP TABLE #ISMEMBER DROP TABLE #ISROLEMEMBER DROP TABLE #RLSLookupUser DROP TABLE #SESSIONCONTEXT |
Authorization Performance
As with authentication, authorization can be implemented in multiple ways. Standard tuning techniques can be used to meet your NFRs. This includes proper indexing, table design, and hardware choices will impact system performance.
Protect your data. Demonstrate compliance.
Denormalization
Denormalization is an important part of performance with RLS. Any additional joins in the access predicate have a tendency to decrease performance. Complex queries, such as joins with an OR clause can be performance killers. When possible, denormalize the data by including the lookup column in each table with RLS. The extra overhead in the ETL and disk IO is minimal and compensated for by the improved performance during queries.
This is also a good reminder to think about your security architecture during the design phase so refactoring isn’t necessary. Performance testing and tuning is a key activity, especially when using RLS with transactional systems (or even warehouses). Adding extra columns and maintaining those columns is less tenable in systems with high numbers of transactions, so be sure RLS fits your usage patterns.
Single-level security lookup tables
Avoid joins in lookups. A flattened, single level lookup table for security, performs much better than traversing multiple levels for access predicates to the key column. They often can’t be avoided completely, but they should be minimized. This would apply to scenarios such as geographical regions or any other hierarchical organizational unit.
A specific example is region level access to data, with state level access (which includes all counties), country level access (which includes all states / provinces), and complete world level access (which includes all countries) at the top. It is possible to assign security at a country level and have the access predicate join to states and counties, which then joins to the correct rows using county in the final clause. Since the access predicate is executed for each row, even a small difference in performance can have a large overall impact.
Maintaining a hierarchical structure for joins is possible, but much better performance is realized by flattening the hierarchy. This is done during pre-processing using ETL as an asynchronous process. In the county, state, country, world example, much better performance is realized if world access is saved to the security tables as all counties per user. This can result in a lookup table with many rows, but it performs much better than traversing four structures and including OR logic in the access predicate. If the data can’t be flattened, union statements are generally more efficient than using OR in the join.
Indexing and Performance Tuning
Access predicates should be tuned like any other function or query. Like all queries, join columns and where clauses are great starting points for tuning. Ensure both sides of the join clause are indexed correctly as well as the filter columns. Pay special attention to joins with OR logic. As mentioned above, queries with an OR in the join usually perform better as two separate statements with a UNION. Even with these general guidelines, changes to predicates for performance should be tested and validated.
Azure Synapse / Elastic Query / Linked Server
Azure Synapse is listed in the Microsoft documentation as a valid target for RLS access predicates and security policies. Tuning with external sources can be limited if you don’t maintain those external systems. The same general guidelines apply. Keep logic as simple as possible. Perform any operations on the source instead of over the network when feasible. This means, if joins or calculations must be done, perform them in the source using a view and include any filters via a WHERE clause in the view on the source also.
If the teams that maintain source systems are different from the consumer’s system, it can help to show the performance difference if teams are reluctant to add the logic on the source system. It also helps if the view definition is provided to the source owners so they just need to review and check in / deploy the code.
Troubleshooting
If users are unable to access rows which they should be authorized to access, it can be confusing to troubleshoot. This is especially true for support team members less familiar with the inner workings of RLS and how all of the authentication (who is the user and is their identity verified, i.e., the login process) and authorization (does the user have permission to access a resource) mechanisms fit together.
The pattern for troubleshooting access to tables with RLS is identical to troubleshooting general access with a few additional steps added. The user should have a valid login or contained user, they should have database access, object access, should not be blocked, etc. RLS troubleshooting will be specific to the implementation. If the system is unfamiliar, scripts can be used to find the access predicate and the RLS logic.
The Exploring Errors article covers a specific vulnerability in the older view-based approach that RLS replaces: how view-based row-level security exposes data through SQL Server error messages
Authentication
A brief review of SQL Server security mechanisms is useful for understanding how to troubleshoot RLS at an authorization level. This is the login process. The first step in authorization for SQL Server is determining and specifying the login method.
The way this is done depends on the tool getting used and the methods configured on the server. It ranges from a SQL Server login, a contained database user with login, a Windows integrated account (trusted login) and various Azure authorization mechanisms. An end user must first be authorized before they can access a database.
Authentication is relatively easy to troubleshoot. A login failed message is a clear indicator for this problem. It could still mean that the user typed in the wrong server name, the wrong user name, a bad password, or authorization is blocked at a network level, but it certainly narrows down the list of things to verify. The DBA or Active Directory team may need to get involved at this stage. Verify that the SQL Account, Active Directory account or Azure Active Directory account is enabled and not locked out. SQL Trace / Profiler or a SQL Audit can be very useful to show that the authentication attempt is hitting the server.
If the authentication failure doesn’t show in the trace or audit, the request isn’t even hitting the server and more basic troubleshooting is indicated. From a client perspective, command line tools such as sqlcmd.exe can simplify this process. I find that sqlcmd.exe is easier for troubleshooting because the exact command can be shared with the user and they can paste it in their command line exactly. This eliminates some of the communication errors that can happen with non-technical users (or even technical users). If the login is a SQL login, the support team can also verify it themselves. None of these techniques are specific to RLS, but authentication is the first thing to check.
Server Authorization
If the account passes the authentication check, server authorization should be validated. This is essentially the same thing when considering a SQL login. For trusted authentication, a login exists on the server or a group the user is a member of is mapped to the server. That user also needs to be allowed access to the server which just means it is not disabled. If this has been done, the active users on the server can be verified.
A trace can also be used to capture all logins. If the user is found in the trace, server authorization is not the problem. DMVs such as sys.processes also show current users, the network protocol used, authentication method and many more details that can be useful for troubleshooting.
|
1 2 |
SELECT * FROM sys.sysprocesses |
Database Authorization
Database authorization is the process of a login being mapped to a database user and that user getting access to the database. In the case of an Azure database contained user, the server authentication or login is the same as the database authorization. If the login is mapped to a user, the other common item to check is that the user isn’t orphaned due to a recent database restore from a different server.
This isn’t likely in a production environment but it should be checked if the user is present but the user isn’t able to access the database. Sys.sysusers shows the login SID associated with a user account. A NULL sid value is generally an indication of a problem for non-system user accounts. You can also use the GUI to look at users and their associated logins.
|
1 2 |
SELECT * FROM sys.sysusers |
Object / Table Authorization
SQL Server provides great flexibility in the methodology for assigning security to users. The most important aspect of assigning security is consistency. Simplicity of design is also important but consistency makes interpreting security faster and adding security for users easier.
Some methods are better than others from an organizational perspective and a maintenance perspective, but are outside the scope of this article and when troubleshooting access, the design phase is already done. Each of the following methods for allowing authorization need to be checked.
Direct Access
Direct access, assigning SELECT, INSERT, UPDATE, DELETE, EXEC for a database object, for users and groups should be checked. Direct access is clear and easy to interpret at this level. It is generally not a best practice to assign security directly at a user level, but there are use cases for this and it happens frequently. Be sure to check for explicit deny permissions at this level too. Even if this is not the agreed upon pattern, this should be validated. Organization changes can result in confusion and standards not getting followed.
Database Role Membership
Role level access is usually where security will be granted. This includes the built-in roles and user defined roles. You may need to enumerate group membership to get a clear picture. As discussed in the design section, built-in roles are likely not optimal for RLS solutions and should be used with caution, if at all, with RLS.
Server Role Membership
Server level roles apply to all databases, so they need to be checked as well. This won’t, or shouldn’t, apply to regular user accounts, but a quick check of these roles is warranted. There should be a very small number of users in this category. This means checking for the sysadmin role since it impacts all databases and translates to dbo access in each of them.
RLS Authorization
If a user account is authenticated, is authorized at the server, database, and object level, the last thing to check is RLS authorization. As mentioned above, Row Level Security is not a prescriptive technology, it is dependent on each team to decide the specific method that best meets the requirements of the project. Documenting the particular method used for RLS in each application is highly recommended and will ease this portion of troubleshooting.
Depending on the method used, check the database tables used by RLS, check Active Directory groups, validate the SESSION_CONTEXT() (hopefully not CONTEXT_INFO()), or any other method used. It can be helpful to have another user with the same permission set to check their access to data to help narrow down the issue. There is no single method to do this, but understanding the design and how authorization is granted will give you a starting point.
There are a few RLS use cases that aren’t as obvious during the planning phases but will quickly become obvious when it is moved to production. Be sure to include ETL service accounts in the RLS plans. They generally should have access to all data, but if that is not the case, ensure that all scenarios are tested. The same is true for admin accounts and other service accounts. Putting a user is in the db_owner or sys_admin role doesn’t automatically grant them access to all rows in an RLS protected table. If you need admins to run DML scripts for your team in production, be sure they have access. An override statement for admins in the access predicate is something to consider.
If you provide validation or setup scripts to a support team, be sure to include RLS in those scripts. You will also want to give developers and support teams a base level of training even if database development or support isn’t their primary area of responsibility. At the very least, the support team should understand that RLS is used in the database and how an issue with RLS access appears from a user’s perspective.
ETL and Admin Issues
As mentioned above, ETL packages are no exception to Row Level Security rules. The same general troubleshooting rules apply to service accounts used by ETL. If RLS uses tables for authorization, be sure the ETL account has access to that schema. This will differ from regular user account access but it is needed so the ETL account can maintain those tables. In any case, ensure that ETL accounts are setup to access all data.
Service Account Access and Admin Access
Any service account used to access the database, ETL or otherwise, must be setup with the correct RLS access in addition to standard authorization. If the account will be performing DML operations, it should have access to all rows or the ETL operations should be tested more thoroughly than usual. Administrators must also have full access if they perform any DML operations. The block filter can also help with the issues presented below.
False Duplicates
The ETL service account must have full access to the data or duplicate key errors are possible during INSERT or UPDATE. Key lookups and anti joins used to find missing records don’t work if the lookup table isn’t accessible via RLS. The query engine will interpret the inaccessible rows as non-existent in the table and try to insert them again. The error message will show a duplicate key error and may be difficult to interpret if you aren’t looking for it and if troubleshooting happens with an account having full access.
A block modifier will prevent this operation, but may hurt performance. In highly critical systems, the extra effort to populate RLS tables and the chance of an error may be worth the performance benefits. This is clearly dependent on the system needs and service level agreement (SLA).
Excess Deletes
It is also possible to delete excessive rows with an anti-join if the RLS is not allowed for the source table. ETL service accounts run with elevated privileges and RLS must be included in those privileges. Testing is recommended when implementing RLS and extra care should be taken when adding to a pre-existing database.
These issues aren’t limited to ETL, they can happen with any account that is allowed direct CRUD access, but it is a scenario unique to RLS. Sanity checks before deleting (only deleting if the percentage of rows to be deleted is low enough) can help avoid these situations.
Ghost Records
Joins in the access predicate can cause issues beyond performance. The referenced table must be accessible to the account performing the lookup. Ghost records, records that are inaccessible to the user but block operations that should be allowed, can happen when JOINs are required in the access predicate.
If the table containing the lookup column deletes rows before the target table, the target table will not return the expected rows and they can’t be deleted normally. This is much more likely in warehouses without foreign keys maintaining referential integrity. It happens when table keys are deleted in referenced tables without first deleting the rows referencing them, so in non-enforced or logical foreign keys.
Fast, reliable and consistent SQL Server development…
Requirements to reproduce this scenario
- A lookup table is used to apply RLS rules
- The table with RLS applied to it must perform an additional lookup (JOIN) to retrieve the RLS column
- In the scenario below, the PurchaseOrderLineID is used to get to PurchaseOrderID then the SupplierID
- In the scenario below, the PurchaseOrderLineID is used to get to PurchaseOrderID then the SupplierID
- No foreign keys are protecting the referential integrity of the tables
- Likely scenario in a warehouse or reporting database
- Likely scenario in a warehouse or reporting database
- The table containing the lookup column, in this case SupplierID, is deleted before the referencing table, in this example, Purchasing.PurchaseOrderLines.
- The account performing ETL does not have an exclusion to RLS. You can see in the following example that db_owner would see all records and this would not happen.
- You wouldn’t want to grant dbo rights to an ETL account
- Consider adding the ETL account to your RLS exclusion list to bypass this issue
This can be prevented by deleting in the correct order, but in real-world scenarios, that doesn’t always happen. The easiest way to deal with these records, after they are corrupted, is to lock the target tables, drop RLS, fix the incorrect data, reapply RLS, and unlock the tables.
The scenario
The following shows this scenario for Purchasing.PurchaseOrderLines. It needs access to the SupplierID maintained in the Puchasing.PurchaseOrders table. If the SupplierID records are deleted first, the PurchaseOrderLines records can’t be deleted with a normal user account.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
--Setup accounts for this test CREATE USER RLSGhostRecords WITHOUT LOGIN ALTER ROLE db_datareader ADD MEMBER RLSGhostRecords DENY SELECT ON SCHEMA::RLS TO RLSGhostRecords INSERT INTO RLS.UsersSuppliers ( UserID ,SupplierID ) VALUES ( 'RLSGhostRecords' ,12 ) GO CREATE USER RLSETLUser WITHOUT LOGIN ALTER ROLE db_datareader ADD MEMBER RLSETLUser ALTER ROLE db_datawriter ADD MEMBER RLSETLUser --Note that this user also has access to the RLS schema --Also note, this user does not have db_owner permissions, best practice for user accounts --The following is needed for the user to change the state of the security policy GRANT ALTER ANY SECURITY POLICY TO RLSETLUser GRANT ALTER ON SCHEMA::RLS TO RLSETLUser INSERT INTO RLS.UsersSuppliers ( UserID ,SupplierID ) SELECT 'RLSETLUser' ,SupplierID FROM Purchasing.Suppliers ORDER BY SupplierID GO |
This grants all records to the ETL account and a single SupplierID to the new regular user account, RLSGhostRecords.
The following shows the RLS access predicates and security policies:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
--Simple access predicate CREATE FUNCTION RLS.AccessPredicate_SupplierID_PurchasingPurchaseOrders(@SupplierID int) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 AccessResult WHERE IS_MEMBER('db_owner') = 1 UNION SELECT 1 AccessResult FROM RLS.UsersSuppliers US INNER JOIN Purchasing.PurchaseOrders PO ON US.SupplierID = PO.SupplierID WHERE US.SupplierID = @SupplierID AND US.UserID = USER_NAME() GO CREATE SECURITY POLICY RLS.SecurityPolicy_SupplierID_PurchasingPurchaseOrders ADD FILTER PREDICATE RLS.AccessPredicate_SupplierID_PurchasingPurchaseOrders(SupplierID) ON Purchasing.PurchaseOrders ,ADD BLOCK PREDICATE RLS.AccessPredicate_SupplierID_PurchasingPurchaseOrders(SupplierID) ON Purchasing.PurchaseOrders AFTER UPDATE WITH (STATE = ON, SCHEMABINDING = ON) GO --Simple access predicate with a lookup CREATE FUNCTION RLS.AccessPredicate_PurchaseOrderLineID_PurchasingPurchaseOrderLines(@PurchaseOrderLineID int) RETURNS TABLE WITH SCHEMABINDING AS RETURN SELECT 1 AccessResult WHERE IS_MEMBER('db_owner') = 1 UNION SELECT 1 AccessResult FROM RLS.UsersSuppliers US INNER JOIN Purchasing.PurchaseOrders PO ON US.SupplierID = PO.SupplierID INNER JOIN Purchasing.PurchaseOrderLines POL ON PO.PurchaseOrderID = POL.PurchaseOrderID WHERE US.UserID = USER_NAME() AND POL.PurchaseOrderLineID = @PurchaseOrderLineID GO CREATE SECURITY POLICY RLS.SecurityPolicy_PurchaseOrderLineID_PurchasingPurchaseOrderLines ADD FILTER PREDICATE RLS.AccessPredicate_PurchaseOrderLineID_PurchasingPurchaseOrderLines(PurchaseOrderLineID) ON Purchasing.PurchaseOrderLines ,ADD BLOCK PREDICATE RLS.AccessPredicate_PurchaseOrderLineID_PurchasingPurchaseOrderLines(PurchaseOrderLineID) ON Purchasing.PurchaseOrderLines AFTER UPDATE WITH (STATE = ON, SCHEMABINDING = ON) GO |
To replicate a reporting database, I also removed the foreign keys. Remember that if the foreign keys are in place, this issue can’t happen:
|
1 2 3 4 5 6 7 |
ALTER TABLE [Purchasing].[PurchaseOrders] DROP CONSTRAINT FK_Purchasing_PurchaseOrders_SupplierID_Purchasing_Suppliers ALTER TABLE [Purchasing].[SupplierTransactions] DROP CONSTRAINT FK_Purchasing_SupplierTransactions_SupplierID_Purchasing_Suppliers ALTER TABLE [Warehouse].[StockItems] DROP CONSTRAINT FK_Warehouse_StockItems_SupplierID_Purchasing_Suppliers ALTER TABLE [Warehouse].[StockItemTransactions] DROP CONSTRAINT FK_Warehouse_StockItemTransactions_SupplierID_Purchasing_Suppliers ALTER TABLE Warehouse.stockItemTransactions DROP CONSTRAINT FK_Warehouse_StockItemTransactions_PurchaseOrderID_Purchasing_PurchaseOrders ALTER TABLE Purchasing.SupplierTransactions DROP CONSTRAINT FK_Purchasing_SupplierTransactions_PurchaseOrderID_Purchasing_PurchaseOrders ALTER TABLE [Purchasing].[PurchaseOrderLines] DROP CONSTRAINT |
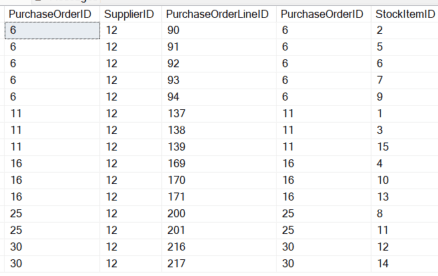
With the base configuration, and all records intact, the standard user is able to see all Purchasing.PurchaseOrderLines associated with the supplier they are assigned. This is the expected behavior:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
EXECUTE AS USER = 'RLSGhostRecords' GO SELECT PO.PurchaseOrderID ,PO.SupplierID ,POL.PurchaseOrderLineID ,POL.PurchaseOrderID ,POL.StockItemID FROM Purchasing.PurchaseOrders PO INNER JOIN Purchasing.PurchaseOrderLines POL ON PO.PurchaseOrderID = POL.PurchaseOrderID WHERE PO.SupplierID = 12 REVERT |
If this supplier is removed from the system and the corresponding Purchasing.PurchaseOrders are removed, it creates the ghost records in Purchasing.PurchaseOrderLines:
|
1 2 3 4 5 6 |
EXECUTE AS USER = 'RLSETLUser' GO DELETE Purchasing.PurchaseOrders WHERE SupplierID = 12 REVERT GO |
Re-running the SELECT statement as RLSGhostRecords shows no records. This is expected since it is an INNER JOIN, and those records were just deleted.

What can be difficult to troubleshoot is that even directly looking up the records associated with SupplierID 12, no records are returned. Note that an account with DBO access would see these records due to the exception in the access predicate for members of db_owner. If your access predicate does not have an exception in it for dbo, even those accounts won’t see the records.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
EXECUTE AS USER = ‘RLSETLUser’ GO SELECT * FROM Purchasing.PurchaseOrderLines POL WHERE POL.PurchaseOrderLineID IN (90 ,91 ,92 ,93 ,94 ,137 ,138 ,139 ,169 ,170 ,171 ,200 ,201 ,216 ,217 ) GO REVERT GO |

This may not be a huge issue in a reporting system, but it will cause record counts to not match. It can cause other issues with ETL depending on the exact scenario. It can be very frustrating to troubleshoot.
Fixing the issue
After you have determined the cause, you have a couple of choices to fix the issue. The first is to delete the offending rows with an account that has an exception in the access predicate. If this happens on a regular basis or you don’t have an exception, I would use a process like the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
EXECUTE AS USER = 'RLSETLUser' GO --Use serializable to ensure other users don’t access the table when RLS is disabled SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO --Use an explicit transaction to further ensure other users can’t access the table BEGIN TRANSACTION BEGIN TRY --Disable the security policy ALTER SECURITY POLICY RLS.SecurityPolicy_PurchaseOrderLineID_PurchasingPurchaseOrderLines WITH (STATE=OFF) --Delete the bad rows with an anti-join DELETE Purchasing.PurchaseOrderLines WITH(TABLOCK) FROM Purchasing.PurchaseOrderLines POL LEFT JOIN Purchasing.PurchaseOrders PO ON POL.PurchaseOrderID = PO.PurchaseOrderID WHERE PO.PurchaseOrderID IS NULL --Re-enable the security policy ALTER SECURITY POLICY RLS.SecurityPolicy_PurchaseOrderLineID_PurchasingPurchaseOrderLines WITH (STATE=ON) COMMIT TRANSACTION END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION ALTER SECURITY POLICY RLS.SecurityPolicy_PurchaseOrderLineID_PurchasingPurchaseOrderLines WITH (STATE=ON) END CATCH SET TRANSACTION ISOLATION LEVEL READ COMMITTED GO REVERT GO |
Summary
Implementing RLS incurs a certain amount of responsibility with performance considerations, administrative overhead, and training. Initial design decisions will have a large impact on overall system performance and will also impact ease of administration and support issues.
Standard design patterns should be maintained when implementing RLS and performance tuning should be a part of the design process and may involve refactoring tables to include RLS columns. This is easier in warehouse solutions but tuning is arguably more important in transactional systems.
Simple Talk is brought to you by Redgate Software
FAQs: SQL Server Row Level Security Deep Dive. Part 3 – Performance and Troubleshooting
1. Which Row Level Security authentication method is fastest in SQL Server?
In order of performance: SESSION_CONTEXT (fastest – reads a pre-set session variable, no lookup required), SQL Server role membership (fast – uses the existing security context), user name lookup with USER_NAME() (fast but limited scalability for maintenance), local lookup table with a flat single-join structure (scalable for complex access tiers), and Active Directory group membership (slowest – requires external AD lookup outside SQL Server’s security context). For high-throughput OLTP workloads, SESSION_CONTEXT with application-managed context setting is the recommended approach.
2. How do I tune a SQL Server RLS access predicate for performance?
Three principles: (1) Keep the predicate simple – every JOIN in the access predicate function executes for each row evaluated; complex predicates with multiple joins degrade performance at scale. (2) Flatten your security lookup table – denormalize multi-tier security hierarchies into a single lookup table rather than traversing a hierarchy in the predicate. (3) Index the lookup table on the user identifier column and the row filter column – these are the JOIN and WHERE clause columns in every predicate execution. Profile the access predicate function independently with representative data volumes before deploying RLS.
3. Why is my ETL producing incorrect results when Row Level Security is enabled?
ETL service accounts are subject to RLS like any other user. If the ETL account only has partial row access, three issues can occur: ghost records (rows that exist but are invisible to the ETL account appear as missing – the ETL may attempt to re-insert them, causing duplicate key errors); excess deletes (an ETL anti-join delete operation can delete more rows than intended if the source query is filtered by RLS); and incomplete updates (rows the ETL cannot see are not updated). Fix: grant the ETL service account full access via UNMASK or include a dbo_override check in the access predicate for service accounts.
4. How do I troubleshoot a user not seeing the rows they should with RLS?
Work through the authorization hierarchy: (1) authentication – can the user log in? (2) server authorization – does their login have access to the SQL instance? (3) database authorization – is their login mapped to a database user with appropriate rights? (4) object authorization – do they have SELECT permission on the table? (5) RLS authorization – does the access predicate return rows for their identity? Test the access predicate function directly: SELECT * FROM dbo.AccessPredicateFunction(CURRENT_USER) to see what the predicate returns for the troubleshooting user’s context.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments