
sys.dm_db_index_physical_stats is the SQL Server DMV (Dynamic Management View) that returns physical fragmentation statistics for indexes and heaps. It reports the key metric avg_fragmentation_in_percent – the percentage of pages in the index that are out of logical order – along with page count, fill factor, and other storage information. DBAs use this DMV to identify which indexes need maintenance and whether to use ALTER INDEX REORGANIZE (for lower fragmentation, 5–30%) or ALTER INDEX REBUILD (for higher fragmentation, above 30%).
This article covers the DMV’s five input parameters, its most important output columns, and a practical T-SQL query for identifying indexes that need attention across your databases.
A quick look at the key data from this dmv that can help a DBA keep databases performing well and systems online as the users need them.
When the dynamic management views relating to index statistics became available in SQL Server 2005 there was much hype about how they can help a DBA keep their servers running in better health than ever before. This particular view gives an insight into the physical health of the indexes present in a database. Whether they are use or unused, complete or missing some columns is irrelevant, this is simply the physical stats of all indexes; disabled indexes are ignored however.
In it’s simplest form this dmv can be executed as:
![]()
The results from executing this contain a record for every index in every database but some of the columns will be NULL. The first parameter is there so that you can specify which database you want to gather index details on, rather than scan every database. Simply specifying DB_ID() in place of the first NULL achieves this.
In order to avoid the NULLS, or more accurately, in order to choose when to have the NULLS you need to specify a value for the last parameter. It takes one of 4 values – DEFAULT, ‘SAMPLED’, ‘LIMITED’ or ‘DETAILED’. If you execute the dmv with each of these values you can see some interesting details in the times taken to complete each step.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DECLARE @Start DATETIME DECLARE @First DATETIME DECLARE @Second DATETIME DECLARE @Third DATETIME DECLARE @Finish DATETIME SET @Start = GETDATE() SELECT * FROM [sys].[dm_db_index_physical_stats](DB_ID(), NULL, NULL, NULL, DEFAULT) AS ddips SET @First = GETDATE() SELECT * FROM [sys].[dm_db_index_physical_stats](DB_ID(), NULL, NULL, NULL, 'SAMPLED') AS ddips SET @Second = GETDATE() SELECT * FROM [sys].[dm_db_index_physical_stats](DB_ID(), NULL, NULL, NULL, 'LIMITED') AS ddips SET @Third = GETDATE() SELECT * FROM [sys].[dm_db_index_physical_stats](DB_ID(), NULL, NULL, NULL, 'DETAILED') AS ddips SET @Finish = GETDATE() SELECT DATEDIFF(ms, @Start, @First) AS [DEFAULT] , DATEDIFF(ms, @First, @Second) AS [SAMPLED] , DATEDIFF(ms, @Second, @Third) AS [LIMITED] , DATEDIFF(ms, @Third, @Finish) AS [DETAILED] |
Running this code will give you 4 result sets;
- DEFAULT will have 12 columns full of data and then NULLS in the remainder.
- SAMPLED will have 21 columns full of data.
- LIMITED will have 12 columns of data and the NULLS in the remainder.
- DETAILED will have 21 columns full of data.
So, from this we can deduce that the DEFAULT value (the same one that is also applied when you query the view using a NULL parameter) is the same as using LIMITED.
Viewing the final result set has some details that are worth noting:

Running queries against this view takes significantly longer when using the SAMPLED and DETAILED values in the last parameter. The duration of the query is directly related to the size of the database you are working in so be careful running this on big databases unless you have tried it on a test server first.
Let’s look at the data we get back with the DEFAULT value first of all and then progress to the extra information later.
We know that the first parameter that we supply has to be a database id and for the purposes of this blog we will be providing that value with the DB_ID function. We could just as easily put a fixed value in there or a function such as DB_ID (‘AnyDatabaseName’).
The first columns we get back are database_id and object_id. These are pretty explanatory and we can wrap those in some code to make things a little easier to read:
|
1 2 3 4 |
SELECT DB_NAME([ddips].[database_id]) AS [DatabaseName] , OBJECT_NAME([ddips].[object_id]) AS [TableName] ... FROM [sys].[dm_db_index_physical_stats](DB_ID(), NULL, NULL, NULL, NULL) AS ddips |
gives us
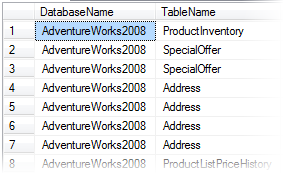
|
1 2 3 4 5 6 7 |
SELECT DB_NAME([ddips].[database_id]) AS [DatabaseName] , OBJECT_NAME([ddips].[object_id]) AS [TableName] , [i].[name] AS [IndexName] , ..... FROM [sys].[dm_db_index_physical_stats](DB_ID(), NULL, NULL, NULL, NULL) AS ddips INNER JOIN [sys].[indexes] AS i ON [ddips].[index_id] = [i].[index_id] AND [ddips].[object_id] = [i].[object_id] |
|
1 |
These handily tie in with the next parameters in the query on the dmv. If you specify an object_id and an index_id in these then you get results limited to either the table or the specific index. Once again we can place a function in here to make it easier to work with a specific table. eg.
|
1 2 3 |
SELECT * FROM [sys].[dm_db_index_physical_stats] (DB_ID(), OBJECT_ID('AdventureWorks2008.Person.Address') , 1, NULL, NULL) AS ddips |
Note: Despite me showing that functions can be placed directly in the parameters for this dmv, best practice recommends that functions are not used directly in the function as it is possible that they will fail to return a valid object ID. To be certain of not passing invalid values to this function, and therefore setting an automated process off on the wrong path, declare variables for the OBJECT_IDs and once they have been validated, use them in the function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DECLARE @db_id SMALLINT; DECLARE @object_id INT; SET @db_id = DB_ID(N'AdventureWorks_2008'); SET @object_id = OBJECT_ID(N'AdventureWorks_2008.Person.Address'); IF @db_id IS NULL BEGIN PRINT N'Invalid database'; END ELSE IF @object_id IS NULL BEGIN PRINT N'Invalid object'; END ELSE BEGIN SELECT * FROM sys.dm_db_index_physical_stats (@db_id, @object_id, NULL, NULL , 'LIMITED'); END; GO |
In cases where the results of querying this dmv don’t have any effect on other processes (i.e. simply viewing the results in the SSMS results area) then it will be noticed when the results are not consistent with the expected results and in the case of this blog this is the method I have used.
So, now we can relate the values in these columns to something that we recognise in the database lets see what those other values in the dmv are all about.
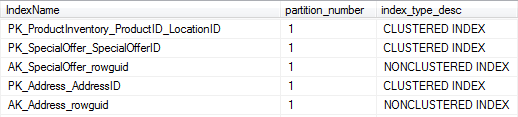
The next columns are: We’ll skip partition_number, index_type_desc, alloc_unit_type_desc, index_depth and index_level as this is a quick look at the dmv and they are pretty self explanatory.
The final columns revealed by querying this view in the DEFAULT mode are
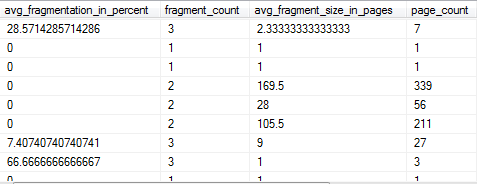
avg_fragmentation_in_percent. This is the amount that the index is logically fragmented. It will show NULL when the dmv is queried in SAMPLED mode.
fragment_count. The number of pieces that the index is broken into. It will show NULL when the dmv is queried in SAMPLED mode.
avg_fragment_size_in_pages. The average size, in pages, of a single fragment in the leaf level of the IN_ROW_DATA allocation unit. It will show NULL when the dmv is queried in SAMPLED mode.
page_count. Total number of index or data pages in use.
OK, so what does this give us?
Well, there is an obvious correlation between fragment_count, page_count and avg_fragment_size-in_pages. We see that an index that takes up 27 pages and is in 3 fragments has an average fragment size of 9 pages (27/3=9).

This means that for this index there are 3 separate places on the hard disk that SQL Server needs to locate and access to gather the data when it is requested by a DML query. If this index was bigger than 72KB then having it’s data in 3 pieces might not be too big an issue as each piece would have a significant piece of data to read and the speed of access would not be too poor. If the number of fragments increases then obviously the amount of data in each piece decreases and that means the amount of work for the disks to do in order to retrieve the data to satisfy the query increases and this would start to decrease performance.
This information can be useful to keep in mind when considering the value in the avg_fragmentation_in_percent column. This is arrived at by an internal algorithm that gives a value to the logical fragmentation of the index taking into account the multiple files, type of allocation unit and the previously mentioned characteristics if index size (page_count) and fragment_count. Seeing an index with a high avg_fragmentation_in_percent value will be a call to action for a DBA that is investigating performance issues. It is possible that tables will have indexes that suffer from rapid increases in fragmentation as part of normal daily business and that regular defragmentation work will be needed to keep it in good order. In other cases indexes will rarely become fragmented and therefore not need rebuilding from one end of the year to another.
Keeping this in mind DBAs need to use an ‘intelligent’ process that assesses key characteristics of an index and decides on the best, if any, defragmentation method to apply should be used. There is a simple example of this in the sample code found in the Books OnLine content for this dmv, in example D. There are also a couple of very popular solutions created by Michelle Ufford (SQL Server MVP) and Ola Hallengren which I would wholly recommend that you review for much further detail on how to care for your SQL Server indexes.
Right, let’s get back on track then. Querying the dmv with the fifth parameter value as ‘DETAILED’ takes longer because it goes through the index and refreshes all data from every level of the index. As this blog is only a quick look a we are going to skate right past ghost_record_count and version_ghost_record_count and discuss avg_page_space_used_in_percent, record_count, min_record_size_in_bytes, max_record_size_in_bytes and avg_record_size_in_bytes. We can see from the details below that there is a correlation between the columns marked. Column 1 (Page_Count) is the number of 8KB pages used by the index, column 2 is how full each page is (how much of the 8KB has actual data written on it), column 3 is how many records are recorded in the index and column 4 is the average size of each record.
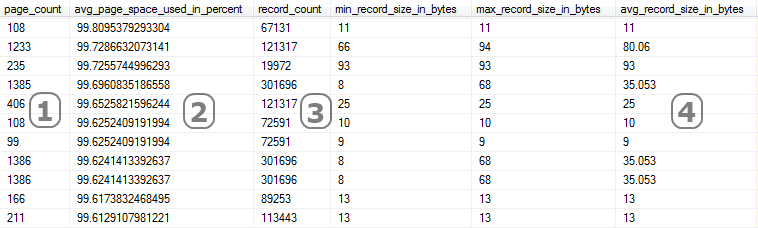
avg_page_space_used_in_percent is an important column to review as this indicates how much of the disk that has been given over to the storage of the index actually has data on it. This value is affected by the value given for the FILL_FACTOR parameter when creating an index.
avg_record_size_in_bytes is important as you can use it to get an idea of how many records are in each page and therefore in each fragment, thus reinforcing how important it is to keep fragmentation under control.
min_record_size_in_bytes and max_record_size_in_bytes are exactly as their names set them out to be. A detail of the smallest and largest records in the index. Purely offered as a guide to the DBA to better understand the storage practices taking place.
So, keeping an eye on avg_fragmentation_in_percent will ensure that your indexes are helping data access processes take place as efficiently as possible. Where fragmentation recurs frequently then potentially the DBA should consider;
- the fill_factor of the index in order to leave space at the leaf level so that new records can be inserted without causing fragmentation so rapidly.
- the columns used in the index should be analysed to avoid new records needing to be inserted in the middle of the index but rather always be added to the end.
* – it’s approximate as there are many factors associated with things like the type of data and other database settings that affect this slightly.
Another great resource for working with SQL Server DMVs is Performance Tuning with SQL Server Dynamic Management Views by Louis Davidson and Tim Ford – a free ebook or paperback from Simple Talk.
![]()
Disclaimer – Jonathan is a Friend of Red Gate and as such, whenever they are discussed, will have a generally positive disposition towards Red Gate tools. Other tools are often available and you should always try others before you come back and buy the Red Gate ones. All code in this blog is provided “as is” and no guarantee, warranty or accuracy is applicable or inferred, run the code on a test server and be sure to understand it before you run it on a server that means a lot to you or your manager.
FAQs: A quick look at: dm_db_index_physical_stats
1. What does sys.dm_db_index_physical_stats measure in SQL Server?
sys.dm_db_index_physical_stats returns one row per index (or heap) per partition, containing: avg_fragmentation_in_percent (the key metric – percentage of leaf-level pages out of logical order), page_count (total pages in the index level), avg_page_space_used_in_percent (how full each page is on average), fragment_count (number of contiguous page sequences), and record_count. Query it with five parameters: database_id, object_id, index_id, partition_number, and mode (LIMITED, SAMPLED, or DETAILED).
2. What fragmentation level requires an index rebuild in SQL Server?
Microsoft’s general guidance: fragmentation between 5% and 30% – use ALTER INDEX REORGANIZE (online, lower resource usage, interruptible). Fragmentation above 30% – use ALTER INDEX REBUILD (more thorough, can be run ONLINE in Enterprise Edition). Below 5% – no action needed. These are starting-point thresholds; adjust based on index size (page_count), workload type, and maintenance window availability. Rebuilding small indexes (under 1,000 pages) is rarely worth the overhead regardless of fragmentation.
3. How do I check index fragmentation for all databases in SQL Server?
sys.dm_db_index_physical_stats must be called per database – passing NULL for database_id returns the current database only. To check all databases, iterate sys.databases (filtering for ONLINE, user databases) and call sys.dm_db_index_physical_stats within each database context using dynamic SQL or a cross-database stored procedure approach. Filter results to page_count > 1000 to exclude trivially small indexes from the output.
4. What is the difference between SAMPLED and DETAILED mode in sys.dm_db_index_physical_stats?
The mode parameter controls how fragmentation is calculated. LIMITED (fastest) – scans only parent-level pages, returning page counts but not accurate fragmentation percentages for all index types. SAMPLED – scans a random sample of leaf pages (approximately 1% of pages), providing accurate fragmentation estimates with lower overhead than DETAILED. DETAILED – scans all leaf pages for exact fragmentation data. For routine maintenance queries across large databases, SAMPLED provides a good balance of accuracy and performance.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments