
Ingesting from API’s is a common task to build a Data Intelligence repository.
When making this ingestion in a Fabric Lakehouse, there are many tricks we can use. One important ingestion concept is the idea to keep a copy of the data in the original format before starting the transformations. We can save the received data in JSON format to achieve this.
There are many specific challenges on the process of saving the result of one API call as a JSON file. In this blog we will analyse these challenges one by one and end up with a reusable notebook which you can call from others, after any API call
Here are the main challenges:
- The choice of the target for the ingestion
- The folder structure
- A reusable notebook
- A parameter cell
- Creating the path if it doesn’t exist
- Saving the File
The choice of the target for the ingestion
When ingesting data in Fabric, we have many storage options to choose. The main ones are Data Warehouse and Lakehouse.
Ingesting from an API to a lakehouse is a great option. It’s a good practice to keep the data in the exactly way it was received, before starting transformations to new tables.
In a lakehouse, we can use the Files area to save the result received from the API and then we continue the transformations.
The folder structure to store the JSON
The folder structure to be used in the Files area is an important point. It needs to make the files easy to locate, meaningful and unique on the execution level.
You need to use Date to easily identify the date of ingestion. You also need to use a folder name representing the API you are loading.
Which one would come first? The Date folder or the API name folder? As the usual reply, it depends. What’s more important, to identify the API and its content, or to identify all the API’s loaded in one date?
You will need to choose:
- F20240510\myAPI
- myAPI\F20240510
Inside the date folder, you need to create different folders for each execution. You could use the time, but a better method to avoid mistakes is to use a GUID as an execution Id. Each execution creates a different GUID, ensuring the files saved on each execution will be in a different folder.
You can create the execution Id using the following statement:
import uuid executionId=str.replace(str(uuid.uuid4()),"-","")
Finally, you need to define the file name. If each execution makes a single API call, this will be easy. On the other hand, if each execution makes multiple API calls, you need to ensure the file names will be unique. In this situation, probably you are making the calls with different parameters, probably a different key. You can add this key to the file name to make it unique.
A reusable notebook to save the JSON
We can create a notebook only to save the JSON file. In this way, we can reuse this notebook in any other notebook making API calls.
The call to the notebook needs to be made using MSSparkUtils.notebook.run. The other option, %Run, needs to be alone in a notebook cell. Probably you will need to call this notebook, to save the JSON, in the middle of a more complex algorithm, maybe some loop. In this case, the call needs to be made using MSSparkUtils.notebook.run.
mssparkutils.notebook.run("NB - Save JSON",arguments= { "contenttosave": func_result.text,"path": "myAPI/", "filenameprefix": f"myAPI{ingested_key}", "ingestionid": executionId })
On the example above, we call the notebook sending the following arguments:
- Contenttosave: The result returned by the API
- Path: The path to save the content. It’s implicitly under “Files”
- Filenameprefix: The prefix string to be used as part of the file name
- ingestionId: The execution Id, which will be used to make folders and file names unique
A Parameter Cell
The notebook needs to receive the parameters. We need to define the first cell of the notebook as a parameter cell, defining input parameters.
We use the cell top menu and select the option Toggle parameter cell
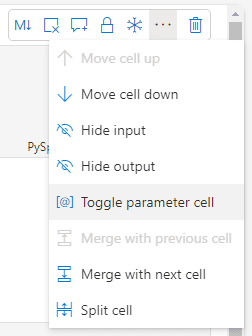
Once the cell is defined as a parameter cell, on the bottom right of the cell we can identify it as a parameter cell.
![]()
In the parameter cell, we only need to define variables. Each variable defined on the parameter cell can be received as an input parameter.
If the value for this variable is not sent by the called, the execution will continue with the default value for the variable, defined on this cell.
This is an example for a notebook to same a JSON file:
contenttosave="{\"accountNumber\": \"ACC-2227886-77464-28\", \"batchSize\": 3000, \"MaxLingerMs\": 1000}" path="ingestiontest/" filenameprefix="somejsonfile" ingestionid=""
Creating the Path if it doesn’t exist
In scenarios like this one, it’s a good idea to use what’s called Defensive Programming. Defensive Programming is the practice to build or code in a way to check for most possible failures, making the code reliable in many scenarios.
In this situation, the requirement for Defensive Programming is to ensure we check if each folder in the path exists and, if not, create it.
Luckly, the Fabric environment provide us with a good tool for this purpose. We can use MSSparkutils.fs . It’s capable to test each folder in the path, one by one, and if anyone doesn’t exist, creates it.
Although the code is quite simple, it’s still a good practice to create a function specially for this purpose. The function will be like this:
def createFolderIfDoesntExist(folder): if not mssparkutils.fs.exists(folder): mssparkutils.fs.mkdirs(folder)
The code is very simple: It checks if the path exists, if it doesn’t, creates it. The magic is done by both, the exists method and the mkdirs method. Both will check if the folder exists, one by one, and create them, one by one.
Saving the JSON file
The next challenge is to save the string provided by the API as a JSON file. We will need to use the OPEN statement to write a content into a file.
The OPEN statement is linked to the file system. Statements such as MSSparkUtils.fs use the lakehouse as their starting folder, we only need to specify the path beyond the lakehouse.
Statements linked to the file system, on the other hand, starts from the root of the spark environment. In this way, we need to start the path with ‘/lakehouse/default’ to reach our lakehouse.
A complete function using the OPEN statement to save the JSON file will be like this:
def saveResult (content, file_path, file_name): createFolderIfDoesntExist(file_path) full_path=file_path + "/" + file_name with open("/lakehouse/default/" + full_path, "a+") as write_file: write_file.write(content)
The complete notebook
The image below shows the first 3 cells of this entire notebook to save a JSON content.

First Cell: The parameters cell, as explained before.
Second Cell
This cell makes date/time processing. The date in string format will be used as part of a folder name. The time in string format will be used as part of the file name.
Third Cell
On this cell the code builds the full path for the file and the complete file name.
The path uses the prefix ‘Files/dropzone/’ . Files is a fixed place in the lakehouse, while “dropzone” is a naming choice in this solution. After that, we concatenate the path prefix received as parameter and finally one folder using the execution Id to identify the folder.
The image below contains the final 3 cells in the notebook.
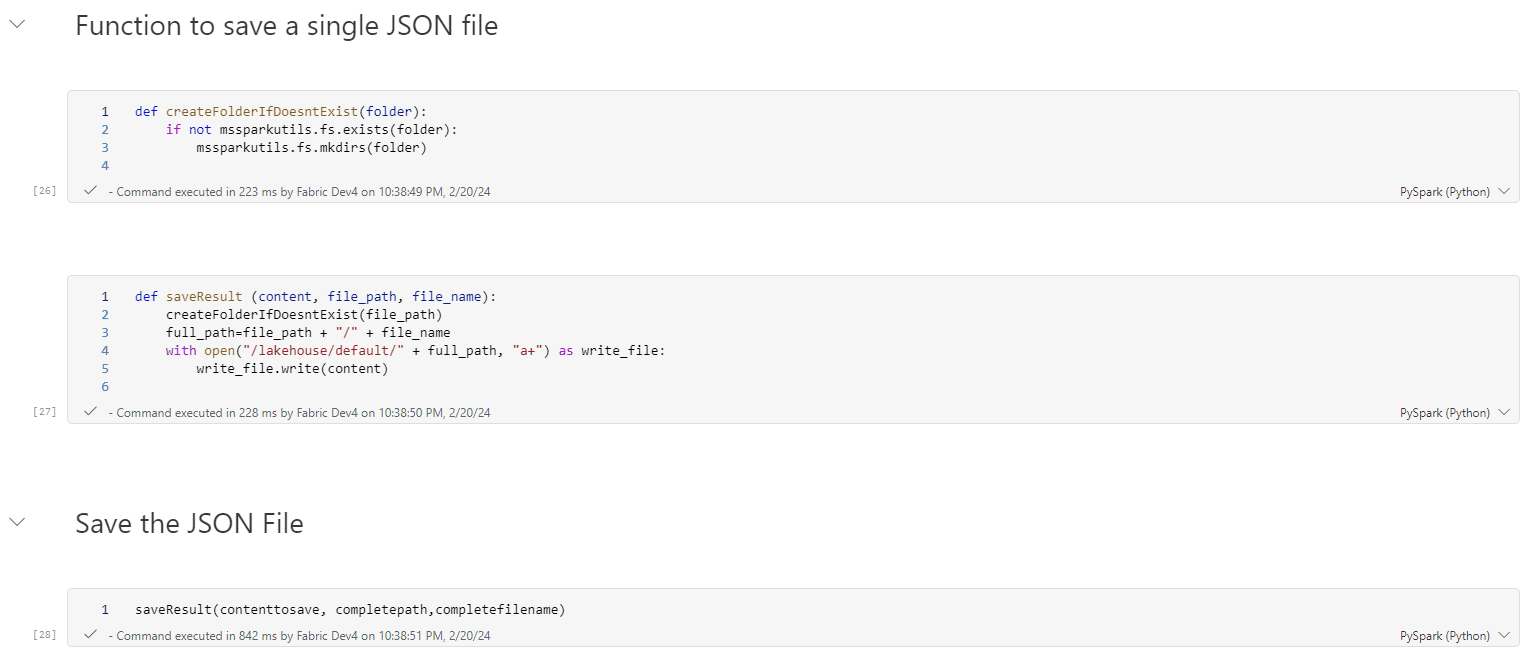
The first two cells contain the functions already explained in this blog.
The last cell is the one which triggers all the action in the notebook. One single line calling the function saveResult and the code is complete.
Conclusion
Storing the precise input content when ingesting data is a good technique and the Files area of a lakehouse is a great place for this.
This reusable notebook makes the process simple. One single line of code to call the notebook and it’s done.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments