
Testing a database upgrade script as part of a continuous integration process will only work if there is an easy way to automate the generation of the upgrade scripts.
There are two common approaches to managing upgrade scripts.
The first is to maintain a set of scripts as-you-go-along. Many SQL developers I’ve encountered will store these in a folder prefixed numerically to ensure they are ordered as they are intended to be run. Occasionally there is an accompanying document or a batch file that ensures that the scripts are run in the defined order.
Writing these scripts during the course of development requires discipline. It’s all too easy to load up the table designer and to make a change directly to the development database, rather than to save off the ALTER statement that is required when the same change is made to production. This discipline can add considerable overhead to the development process. However, come the end of the project, everything is ready for final testing and deployment.
The second development paradigm is to not do the above. Changes are made to the development database without considering the incremental update scripts required to effect the changes. At the end of the project, the SQL developer or DBA, is tasked to work out what changes have been made, and to hand-craft the upgrade scripts retrospectively.
The end of the project is the wrong time to be doing this, as the pressure is mounting to ship the product. And where data deployment is involved, it is prudent not to feel rushed.
Schema comparison tools such as SQL Compare have made this latter technique more bearable. These tools work by analyzing the before and after states of a database schema, and calculating the SQL required to transition the database.
Problem solved?
Not entirely.
Schema comparison tools are huge time savers, but they have their limitations. There are certain changes that can be made to a database that can’t be determined purely from observing the static schema states. If a column is split, how do we determine the algorithm required to copy the data into the new columns? If a NOT NULL column is added without a default, how do we populate the new field for existing records in the target? If we rename a table, how do we know we’ve done a rename, as we could equally have dropped a table and created a new one?
All the above are examples of situations where developer intent is required to supplement the script generation engine.
SQL Source Control 3 and SQL Compare 10 introduced a new feature, migration scripts, allowing developers to add custom scripts to replace the default script generation behavior. These scripts are committed to source control alongside the schema changes, and are associated with one or more changesets.
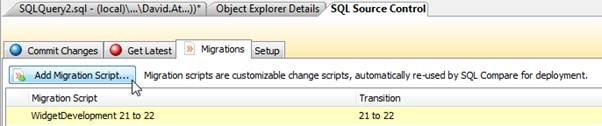
Before this capability was introduced, any schema change that required additional developer intent would break any attempt at auto-generation of the upgrade script, rendering deployment testing as part of continuous integration useless.
SQL Compare will now generate upgrade scripts not only using its diffing engine, but also using the knowledge supplied by developers in the guise of migration scripts.
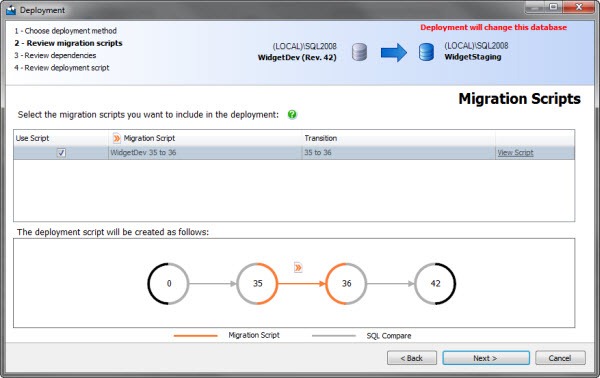
In future posts I will describe the necessary command line syntax to leverage this feature as part of an automated build process such as continuous integration.
Load comments