

Fabric Database was a great announcement during Ignite Conference. The announcement spread all around, a great new feature.
This feature seems simple, especially for everyone who already knows about Azure SQL. However, we don’t need to dig too deep to discover the small secrets this feature has. Secrets that can easily cause mistakes with bad consequences.
Let’s understand a bit more about this.
Fabric Database Internals
I call these as internals, but they are the very basics about how the feature works. An end user can easily skip this knowledge and make mistakes about the connection process.
Fabric Databases are, in fact, Azure SQL Databases, when we create a Fabric database, an Azure SQL Database is created.
The content of the Azure SQL Database is mirrored to Fabric. The mirroring is exactly the same mirroring I illustrated in Fabric Monday 41: Mirroring Azure SQL to Fabric. The only difference is that with Fabric Databases, the mirroring is automatically made and managed for us, we don’t see the objects directly.
The image below illustrates this mirroring and more internal details. I explained this in Fabric Monday 60: Fabric Databases.
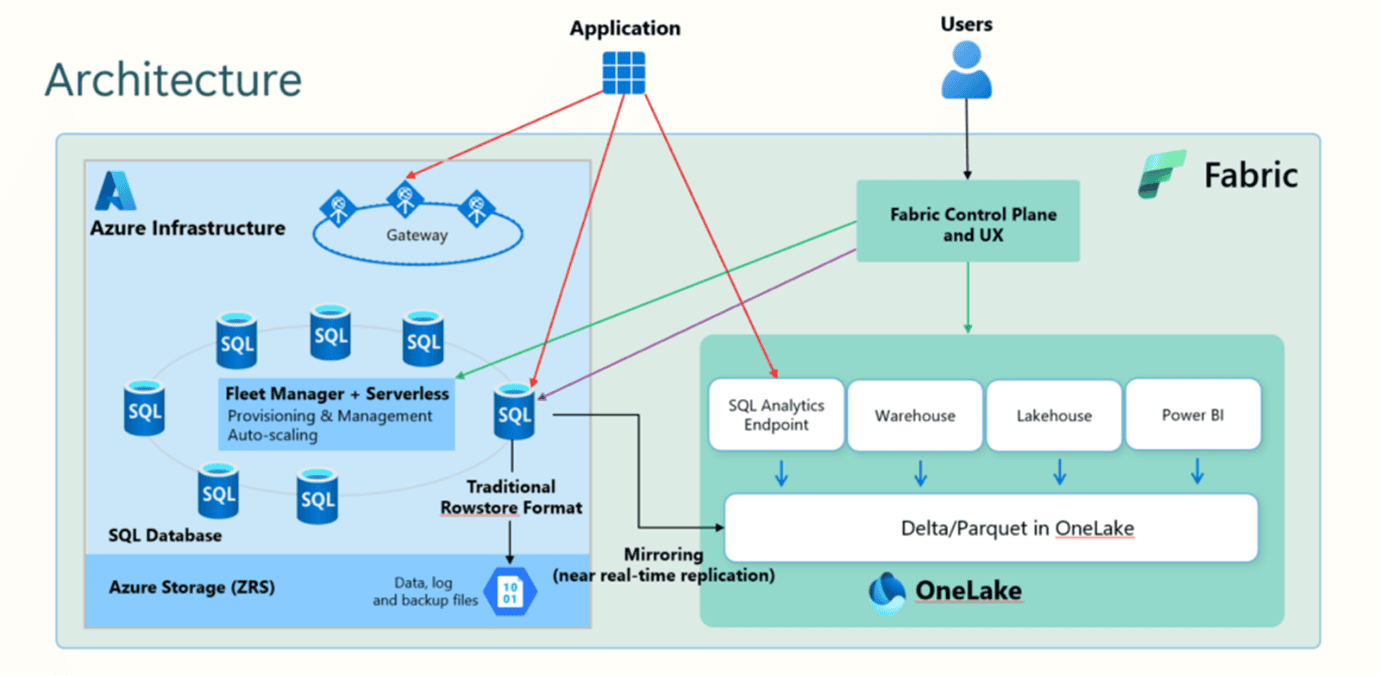
The benefits of this architecture
This architecture brings a big benefit: We can use the mirror for data analysis causing no impact on the production workload at all. The mirroring and the production are two different elements.
There is a recording of a user group meeting where I talk with the attendees about the importance to use different databases for production and data analysis.
The Internals and the Actual Fabric Database Objects
The Fabric Database objects seem very similar to other objects, such as lakehouses and data warehouse, but there are important differences in this case.
As other objects, we have the actual Fabric Database and a SQL Endpoint. However, these objects hold a secret easy to the missed.
Here is the secret: They point to different objects. While the actual Fabric Database object points to the database in Azure SQL, the SQL Endpoint points to the mirrored object in Fabric.

Two different connection details
Each of these objects has its own connection details, pointing to different locations.
In the Azure SQL Database, we can use the option Open in SSMS to retrieve the connection details for the Azure SQL Database.
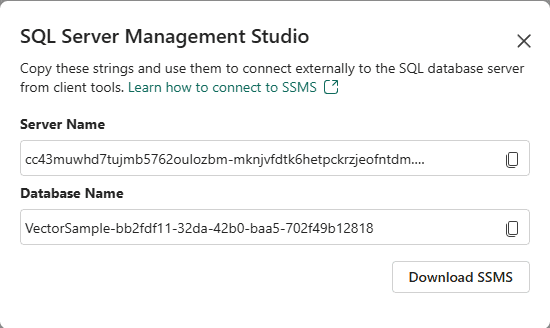
The server Name address is like <servername>.database.fabric.microsoft.com,1433
The suffix of the address tells you to which kind of object you are connecting.
On the other hand, on the SQL Endpoint you can use the already traditional Copy SQL connection string.
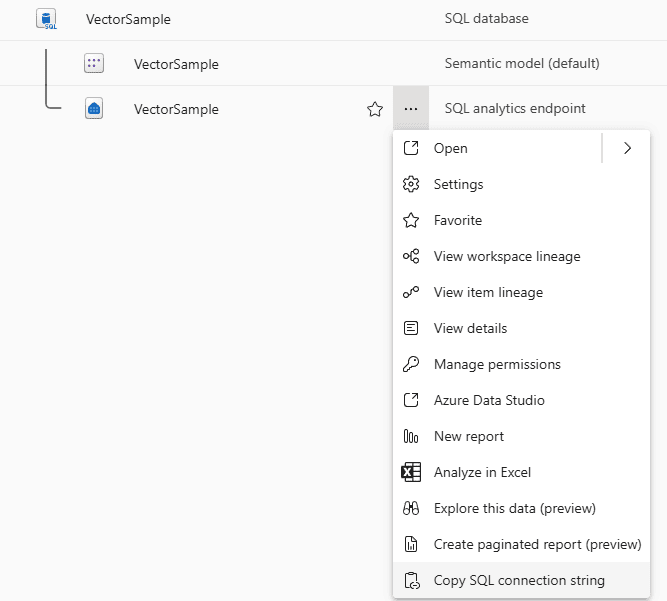
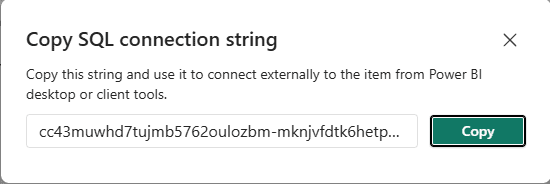
In this case, the address suffix is very different, telling us we are pointing to a different object: <servername>.datawarehouse.fabric.microsoft.com
The importance of the different Addresses and objects
The importance of this difference is exactly on the purpose of this architecture: We have a mirror in Fabric to ensure we don’t put analytical workload over production. What would happen if we mixed the addresses?
If we use the mirror address for production, it will not work at all due to the limitations of a mirror. Let’s talk more about these differences below.
If you use the production address for analytical processing, this is the worst scenario: You will be putting analytical workload over a production server, completely missing the point of this great architecture Microsoft built for you. It will work, your production will suffer, and you will not know what you are doing wrong.
The differences between the two objects
The difference between these two endpoints is basically the difference between an Azure SQL Database and a Mirror.
Let me list some interesting points.
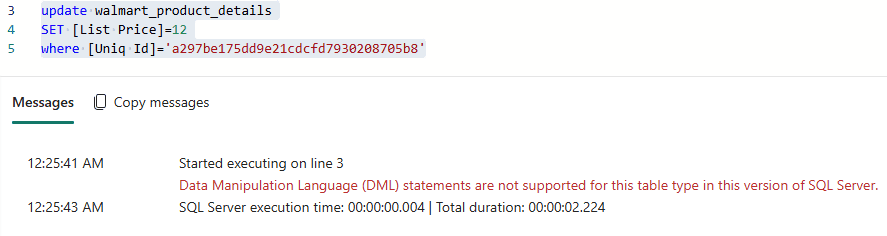
The mirror doesn’t accept any kind of change
It’s a mirror, the change needs to be made in the source database.
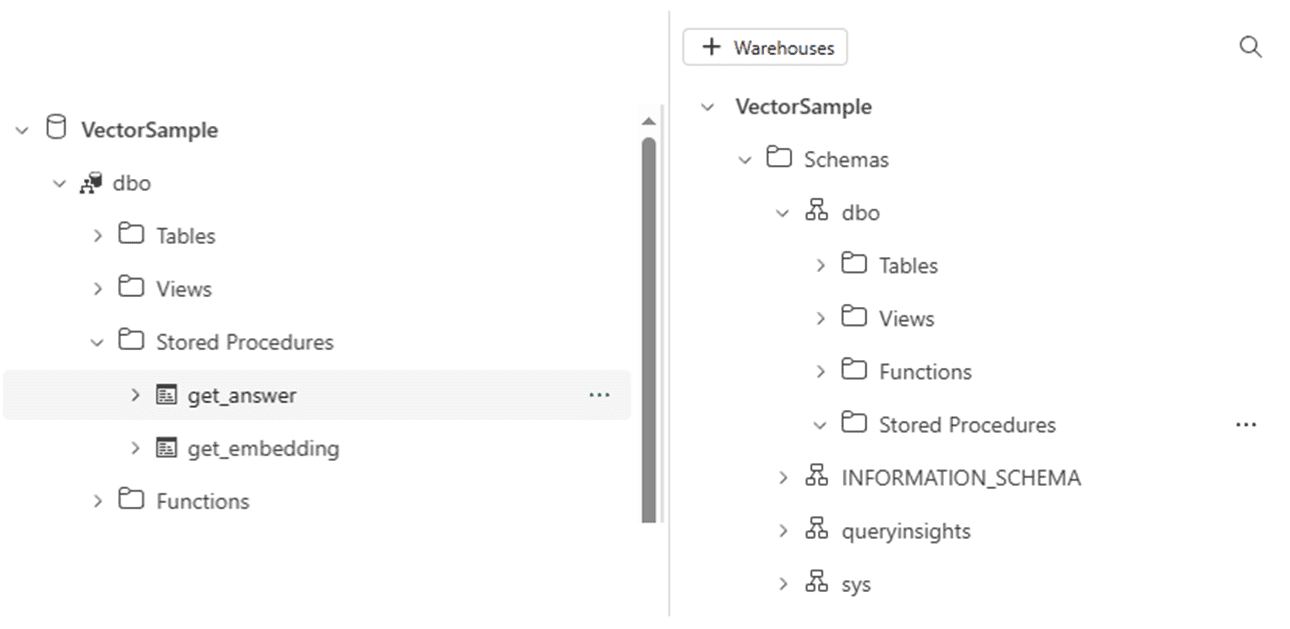
The mirror is only for tables
Views and stored procedures are not mirrored
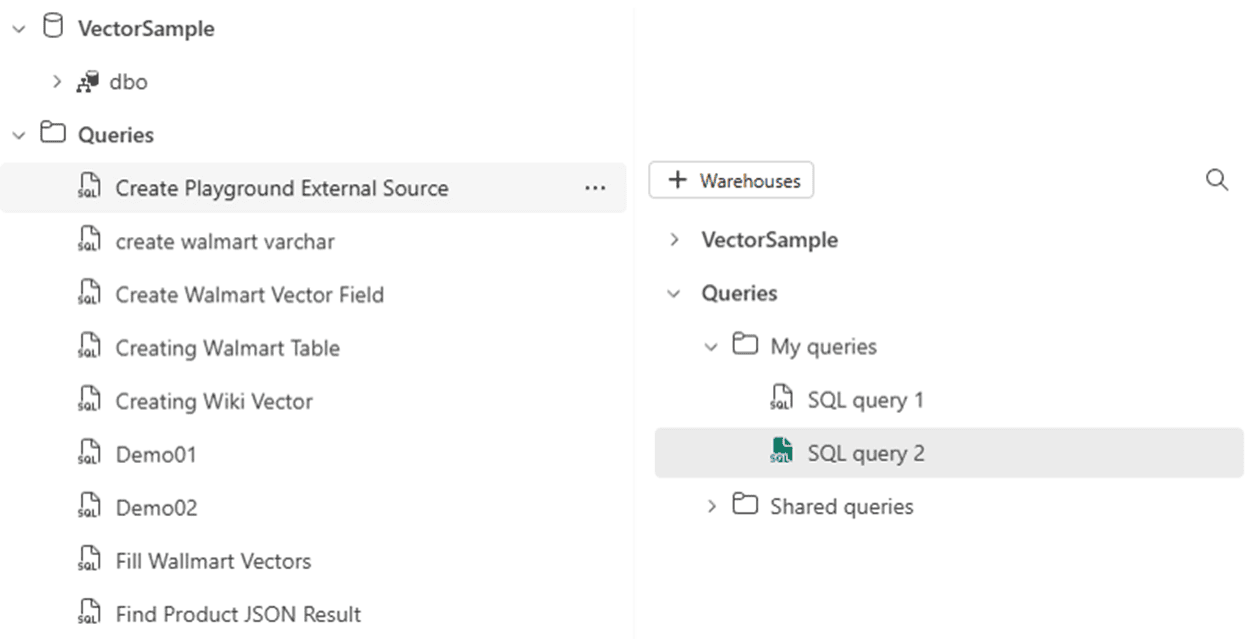
The queries saved in each object are independent
The query files we save together each object are not shared with each other, they are independent
Additional Differences
These are only some differences which attract our attention. The basic rule is that one is the actual database, and the other is the mirror. From this starting point, you can identify more differences.
Summary
This feature is very easy to use, but the users need to understand its internals to not make any mistake when deciding about details, such as which endpoint to use in each scenario
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments