
Let’s consider a simple statement for partitioning and save a table in a lakehouse:
df.write.mode("overwrite").format("delta").partitionBy("Year","Month","Day").save("Tables/" + table_name)
Let’s consider we load the data daily, with all the transactions from the day. The table will save the transactions for each day in different partitions. We can expect the table to keep the partitions from previous day, months and years to be kept, achieving a kind of incremental load, right?
Wrong.
The files are neither, overwritten or deleted, but they are removed from the delta log. The records are not directly acessible in the delta table any more.
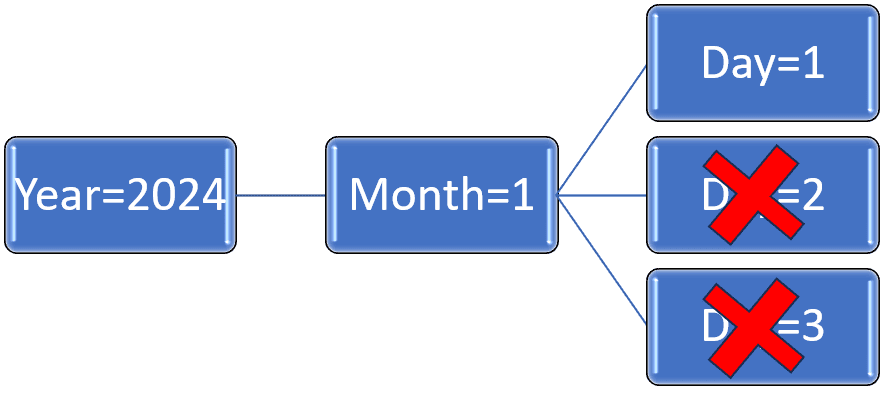
The table removes the previous partitions from the Delta Log
There are two possible solutions: If you load the data once a day, you can replace the “overwrite” by “append”. This solution only works if each ingestion never brings a record already loaded before.
df.write.mode("append").format("delta").partitionBy("Year","Month","Day").save("Tables/" + table_name)
However, if we load the data multiple times a day, bringing all the transactions from the day and containing records which are possibly already loaded in the warehouse, the “append” mode doesn’t work, because it will create duplicated records.
One of the solutions is to overwrite specific partitions instead of all of them. In this case, overwrite the “Day” partition.
The Spark configuration called “partitionOverwriteMode” can have the values static or dynamic. The default value is static. The table removes all old partitions from the delta log by default. When we set this configuration to dynamic, the table keeps the old partitions. It overwrites the ones coming in the dataframe.
After we set this configuration to “dynamic”, we can execute the same original statement to ensure the table will keep the old partitions:
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic") df.write.mode("overwrite").format("delta").partitionBy("Year","Month","Day").save("Tables/" + table_name)
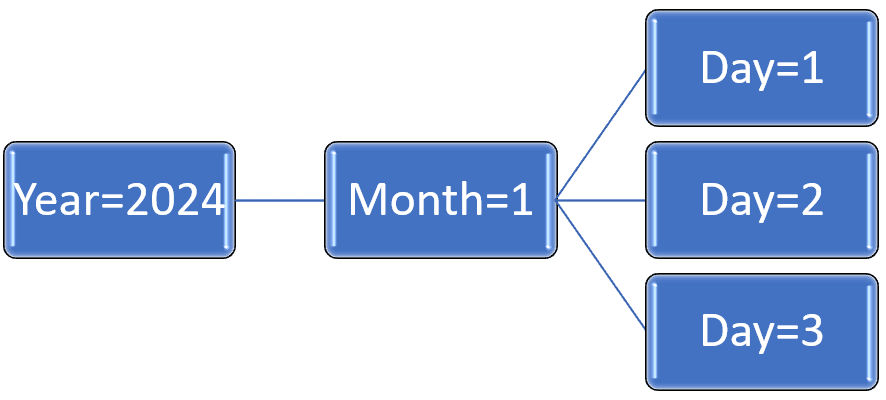
The table keeps the existing partitions, instead of overwritting them.
Summary
Using dynamic partitioning and defining the partition key correctly is one simple and fast way to achieve an incremental load. Of course, this is only one among other options we will talk about later.
You may also would like to take a look on how to set the configuration as default using environments
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments