
Database Projects for Fabric Data Warehouse is one of the most recent news of Fabric for SDLC (Software Development Life Cycle). Microsoft released the Database Projects around 2010 and have they evolved since that year. The original name was a tool called SSDT, released as part of SQL Server, but running inside a Visual Studio Shell.
If you had Visual Studio already installed, it would run inside it, otherwise it would install a shell to run.
What is a Database Project
A database project provides more than way of use it, so we need to define it carefully:
- From an existing database, we can generate the scripts of the existing database
- On a new database project, we can create the schema of the database and deploy
The main point is the possibility to keep the script of the database under source control, including the database project in the SDLC (Software Development Lifecycle).
Two methods of Database Source Control
We can consider in the market there are two methods of database source control:
- Incremental Scripts
- Differential Scripts
Incremental Scripts
Using this method, we keep incremental scripts of every change made in the database. The scripts have a sequential order. The execution is always done in this order.
This method requires a reverse. We need a script to reverse the change as well, so we can advance or reverse in time.
The image below shows an example of Migration scripts created by Entity Framework. Each file contains two methods, one for implement the changes and another to reverse them.
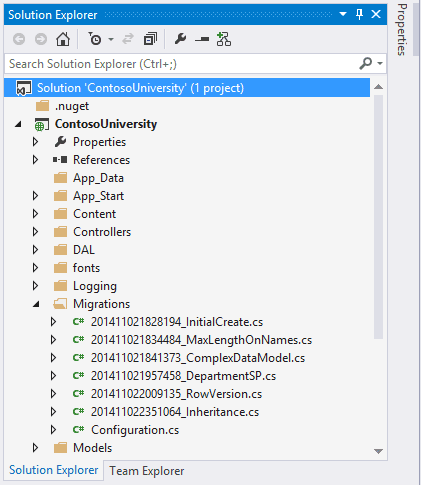
Using this method we extract the differential scripts and store them. We can use tools for this purpose or create the scripts manually (but I wouldn’t like to be the guy who does it manually).
If the scripts get mixed, lost, or anything similar, the updates will not work.
Example: Most ORM’s (Object Relational Mappings), such as Entity Framework or NHibernate, work in this way.
Differential Scripts – The Database Projects
This is the method used by Database Projects.
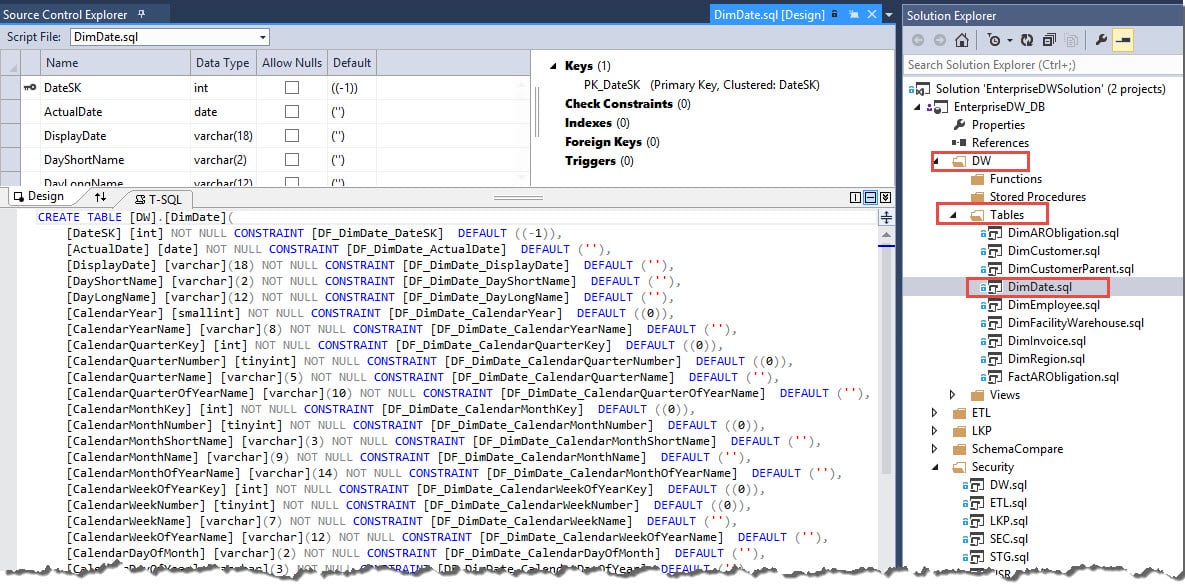
Using this method, we keep the database schema scripts. The scripts to create the objects.
This method requires a process call schema compare: The database project can be compared with the online version. The tool creates a differential script during the compare process, executes it and the script is discarded.
There are many configuration rules in relational about how the tool will proceed in relation to the differential script, the most important are:
- The scripts need to be transactional. In complex DDL scripts, this may not be so simple to build, but the tool manages it. The point is: Or the entire update happens, or nothing happens.
- Data movement may be needed. Some changes of structure may require an object to be dropped and created again and the differential script needs to manage the data movement required for this.
- Data loss could happen. For example, you could reduce the size of a field or remove it. All tools I know have by default an option to stop in case of data loss and let the DBA analyze and order to proceed or not on a case-by-case basis.
What database projects can do
Using Schema Compare instead of incremental scripts makes it easier to identify the changes from one version to another, comparing the script of the objects instead of analyzing what the incremental scripts are doing.
The schema compare feature brings the following possibilities:
- Compare two different versions of a project to find the differences and apply the differences from one to another
- Compare two different live versions of a database to find the differences and apply the differences from one to another
- Compare a project with a live version. The update can happen from the project to the live version or from the live version to the project. Of course, the last one is not good SDLC practice, but it can happen.
Which one to choose
In my personal experience, the Incremental scripts are the preferred choice by developers, because it’s close to their ORM work.
However, it leaves the database structure tied with development code. Because of that, the Differential Scripts are usually the preferred choice from DBAs.
Considering developers work mostly in production systems while the analytics is left for data specialists, it’s natural the first option for Microsoft Fabric Data Warehouse appears in the form of a Differential Script – The database projects
Database Projects for Fabric Data Warehouse and Synapse Serverless
The focus is so much on Fabric the fact the database projects are supporting Synapse Serverless as well will not be noticed. This is a considerable improvement on the SDLC (Software Development Lifecycle) for Synapse Serverless environments.
Over the years, extensions were created for Visual Studio Code and Azure Data Studio to support the database projects on them as well.
Using a difficult to understand strategy, Microsoft teams often release features on the extensions for these tools – Visual Studio Code and Azure Data Studio – and much later the feature is extended to Visual Studio itself.
These extensions are called SQL Database Project and are still in preview.
Each software has an insider version. The Insider version is like a version released directly from GitHub to you. I found less bugs on these extensions when testing the insider’s version, although, in my opinion, they are still a promise.
You cand download Azure Data Studio Insiders Version from this link
Creating the Database Project for Microsoft Fabric Data Warehouse
My tests were done with Azure Data Studio insiders’ version. The extension is available on the regular version, but I faced strange error messages which are pointed by links on the web to be related to compatibility level.
It doesn’t make much sense, because although we can see, we have no control over the compatibility level in Microsoft Fabric Data Warehouse.
Once the extension is installed, we get a new left bar icon for the database projects.
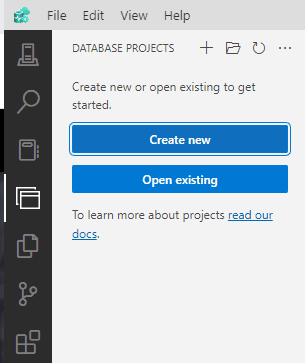
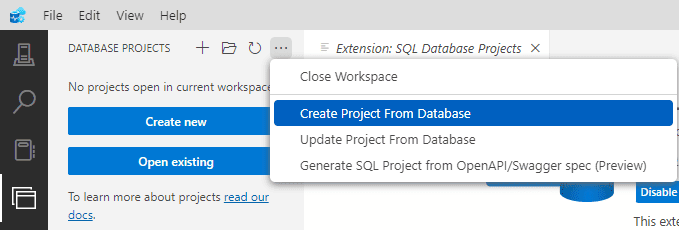
The main options are:
Create a Project : This will be an empty project
Open a Project : What the name implies
Create a Project from Database: Create the project and import the schema from the database
Update a project from the database: This should have the effect of a schema compared with the project as a target. It doesn’t seem a needed option.
Create a SQL Project from an OPENAPI/Swagger spec: This one surprises me. For someone my age, it seems like doing things in reverse order. On what scenarios would you use this option?
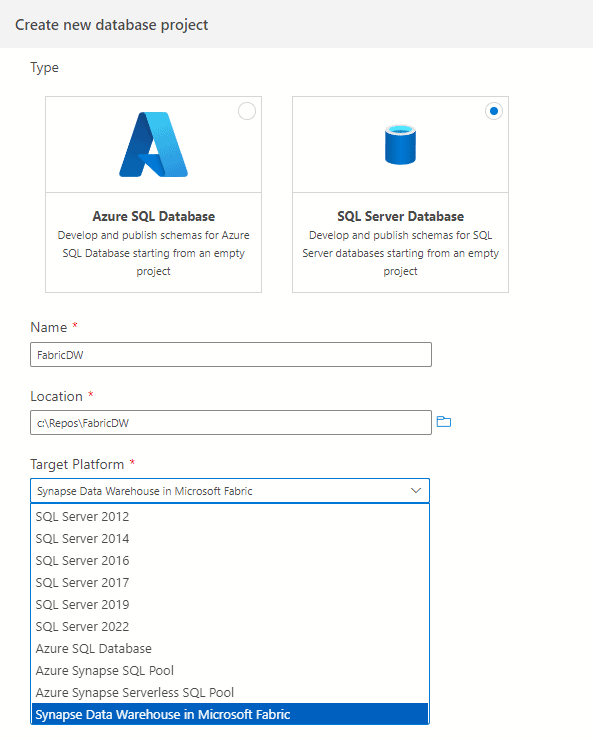
When we choose the option to create a project, we can choose what kind of project we would like to create and here are the new features. Under SQL Server project, we can find a Azure Synapse Data Warehouse in Fabric project and a Synapse Serverless SQL Pool, two new types.
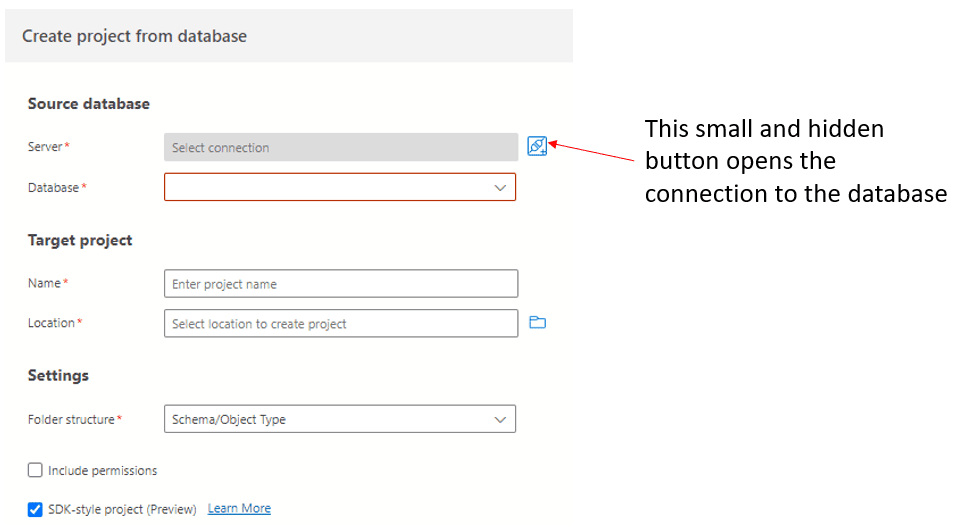
However, when you use the option Create a Project from Database, it asks immediately for the connection, not offering a list of types of projects.
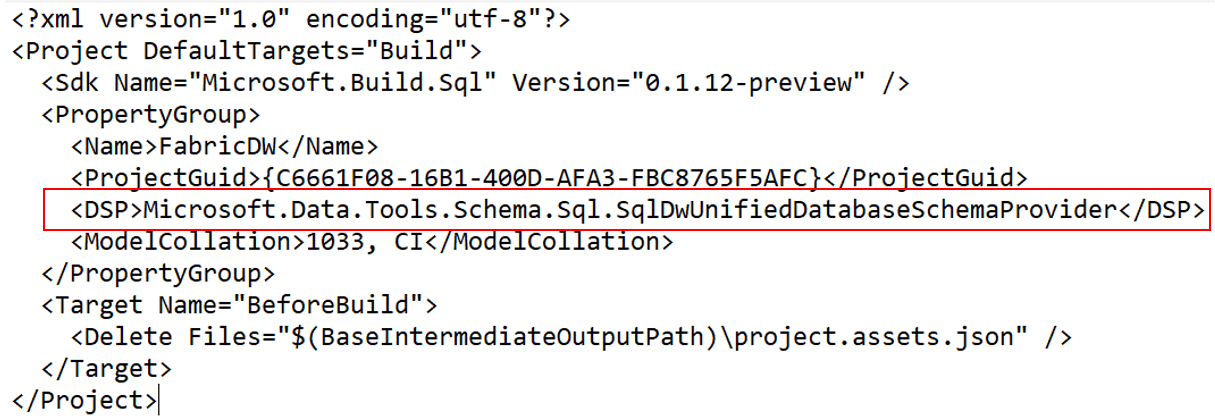
Default Option when No Project Type Selected
During my tests, sometimes it creates an Azure Synapse Serverless SQL Project by default. This made me edit the “.sqlproj” file on the notepad and discover the codename used for both type of projects, so I can change from one to the other one needed to solve bugs:
Microsoft.Data.Tools.Schema.Sql.SqlDwUnifiedDatabaseSchemaProvider : Fabric Data Warehouse
Microsoft.Data.Tools.Schema.Sql.SqlServerlessDatabaseSchemaProvider : Synapse Serverless Project
On the final version of Azure Data Studio, I faced some instable bugs. After some tests, only one persisted, during the schema compare:
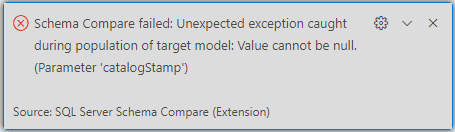
A google research mentions this with some relation with compatibility level, but although we can see compatibility level on Fabric, we can’t change it.
After all the instability, I gave up and went directly to the Insiders version.
Managing Connection with Fabric Data Warehouse
We need to go to Power BI and use the option Copy Connection String on the Data Warehouse.
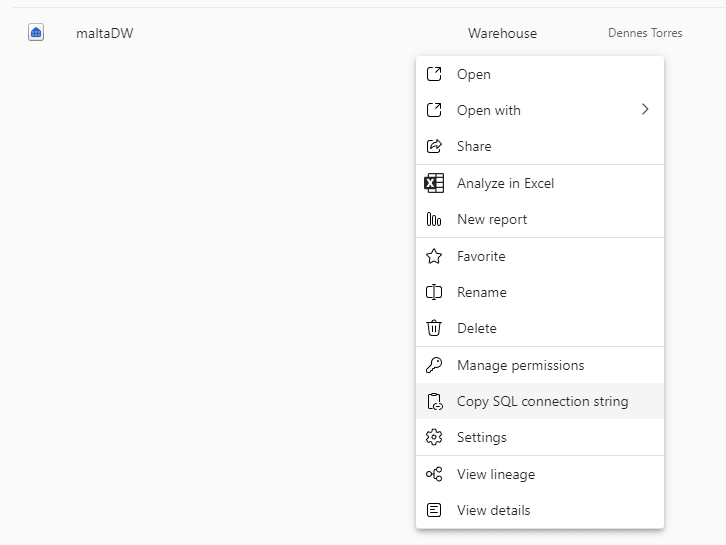
Every developer will recognize this is not a good choice of names. Connection String has a different meaning for developers, while in Power BI it contains only the server’s name, not the entire connection string.
The mismatch starts on Azure Data Studio by itself. When creating the connection, we can choose to input parameters one by one or the entire connection string. We need to choose one by one, because the connection string copied from Power BI is not a connection string, but only the server’s name, captche?
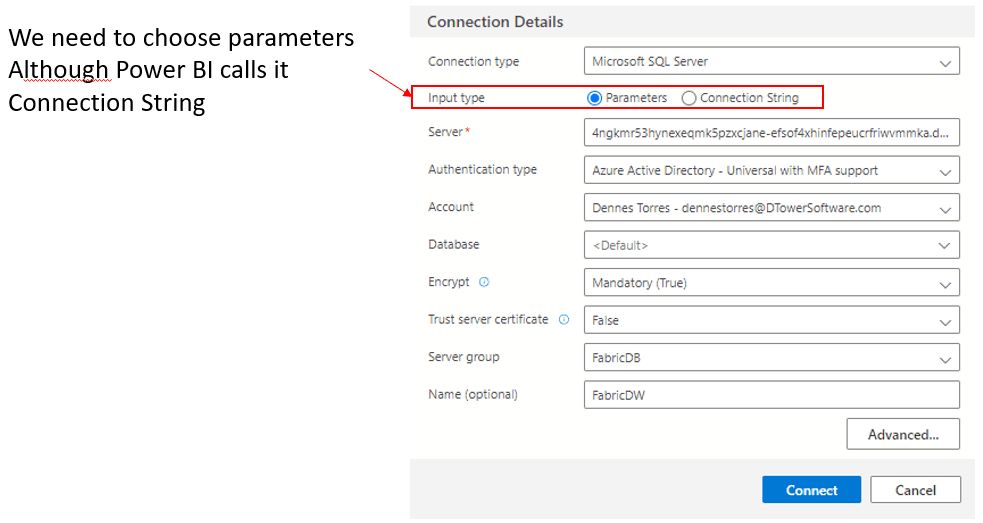
Active Directory was very recently renamed to Microsoft Entra. I found some inconsistency between the usage of Active Directory and Entra ID on the dropdown Authentication Type. Both options mean the same thing.
If I’m not mistaken, Synapse Serverless projects are using Entra ID, while Fabric Data Warehouse is using Active Directory. Or something similar.
When you make a login in active directory (I will take a long time to get used to Entra. Does this have a meaning in English? Did anyone research in other languages?) you get a token. Azure Data Studio is making a reasonable service storing this token for you. Sometimes it complains you have duplicated tokens, and if it happens, you need to close it and open it again. But it could be worse, way worse.
Azure Data Studio gives us the option to save the connection in a folder. This is a good way to organize our server connections.
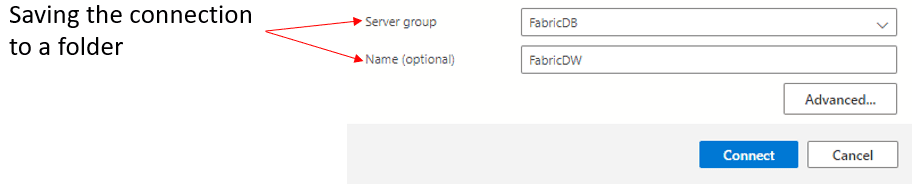
I don’t understand why it ignores the name we chose for the connection and saves it outside the folder we request, leaving the folder empty.
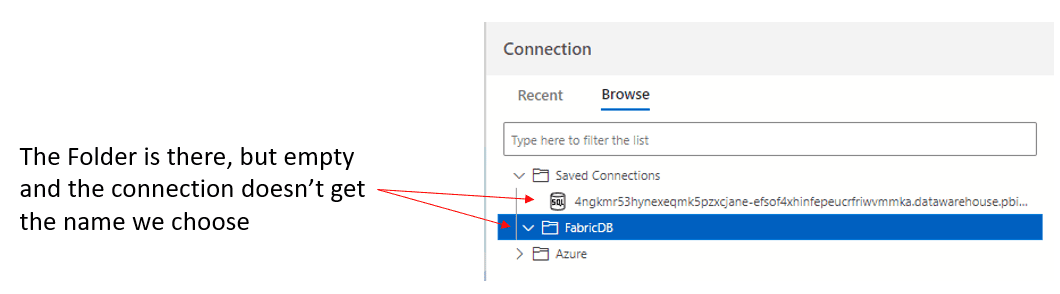
Importing the Database Schema
The connection is made to the server, it doesn’t contain a database name. Once the connection is established, the database names on the same server are retrieved and listed for us.
Some surprises appeared at this point:
- A list of several databases was displayed
- They are all databases in the same workspace
- There are lakehouses and Data warehouses mixed
We can easily conclude there is a different server for each workspace.
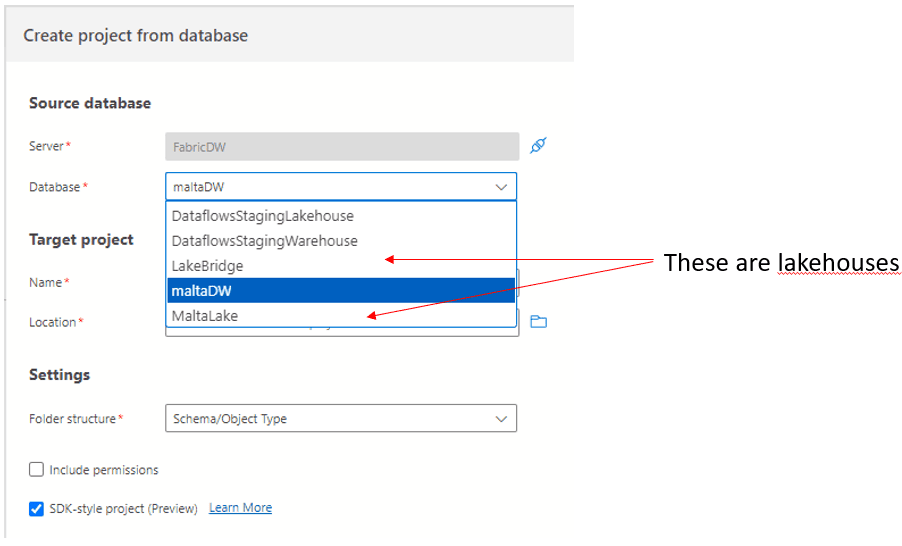
The last one was the biggest surprise. Is there a plan to make Database Projects work with lakehouses SQL Endpoints?
Warehouse Importing Result
Each object from the database is created in a different .SQL file using a folder structure. The files contain the simple .SQL script to create the file, nothing incremental or more complex. This makes it easy to make version comparisons in source control, identify exactly which objects were changed.
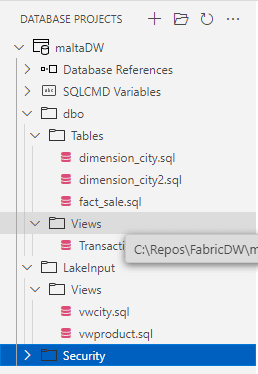
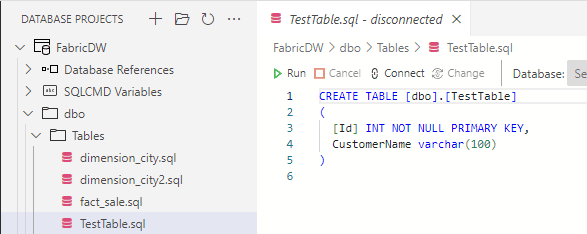
We can make changes to the structure offline. For example, we can create a new table. In the example below, I’m creating a new table called TestTable.
I will also change the size of one of the fact_sale table fields
Comparison and Comparison results
We start the schema compare using a right-click over the project and choosing Schema Compare menu item.
The project will already be filled as source, and the target will be empty.

The choice of the target connection for the schema compare use similar windows as when we created the project from the database, no news at this point.
The most common scenario is the source being the project and target being the server. However, on the top button bar you have an option to reverse the order, what will invert the comparison and application of changes.
![]()
The comparison is also triggered by a button on the top bar.
![]()
It takes some minutes to be completed and it will point out the differences on each file. The column Action tell us if the file was changed or if it’s a new file.

A small bug is causing all tables to be made as difference. During the import, some special character is included in the end of the files, and this is pointed out as a difference. The image below shows the difference pointed in empty rows when there is not a real difference.
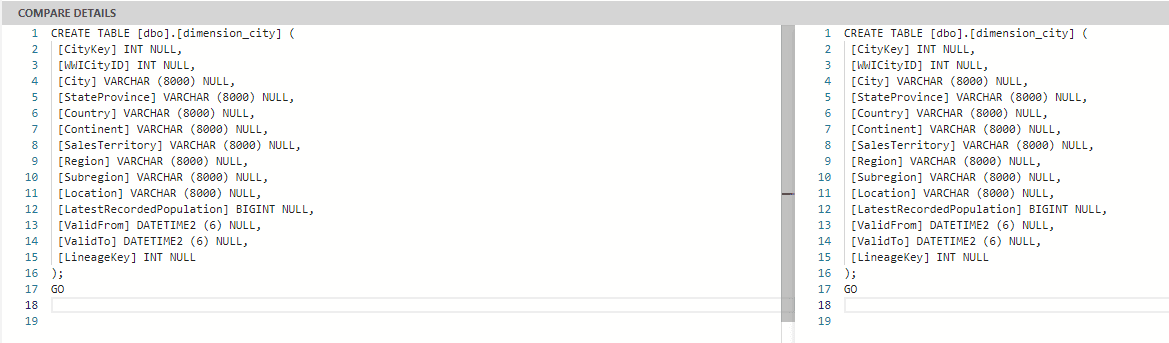
We can also see the difference of the fact_sale table highlighted for us:
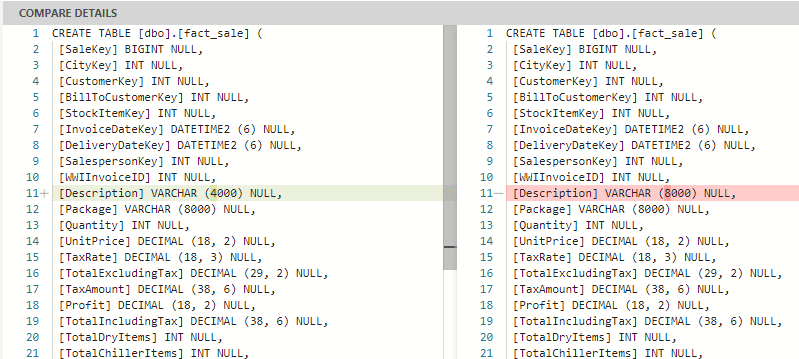
But the real differences will be pointed out as well, making it easy to decide what to update or not. The update application can be selective, you can decide what to update on the target side by checking or unchecking the column Include
Applying the Results
Unfortunately, when applying changes, we receive a mix of two messages: “Not supported” and an error about the roles of the user. It’s not clear if there is already a work around or if we will need to way a future version. The message also includes a mention to “Alter Table”, but when we are only adding tables the message continues to be the same.
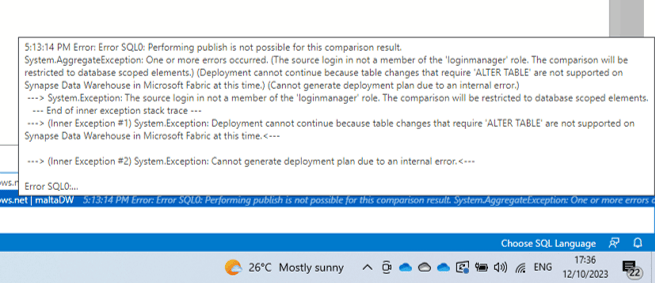
Summary
This is a very promising feature. It seems we will have it available for us in a bunch of weeks, and this will make the SDLC with Microsoft Fabric easier.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments