
SSMS new versions are full of very interesting features. With SQL Server 2019 arriving, it’s normal that our focus is captured by the new features in the database engine, however, SSMS has also a lot to offer.
Let’s highlight some very interesting features this tool has to offer on its new versions.
Vulnerability Assessment
Sometimes the configuration of a server and database seems very complex, especially in relation to security.
The vulnerability assessment feature analyses 53 potential problems, identify if the configuration is correct or not and if not, classifies the risk of the problem.
The evaluation can be made for each database and the reports can be saved in JSON format an open again later.
For each potential problem, the report explains the problem and provides the query used to check if the problem is present or not on the database.
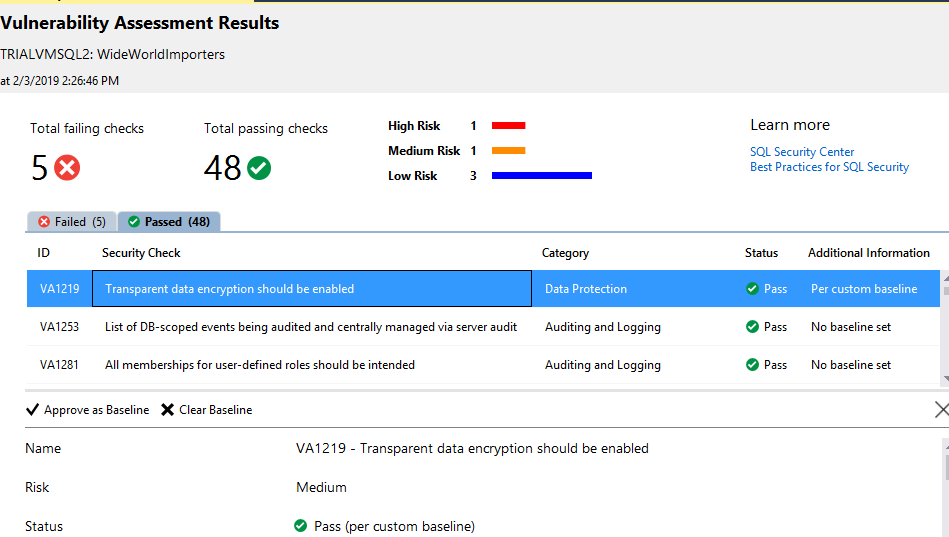
The tool also allows us to record the result as a baseline for our environment. By doing so, we take our custom configuration and needs out of the way so they are not reported as vulnerability issues. However, this is the weaker point of the tool: the baselines are stored in a JSON file on the same folder of the vulnerability report. As a result, if you run the report from different client machines you may get different results, ignoring previous baselines that have been saved.
You can read more about this feature on this link
Static Data Masking
GDPR brought a lot of restriction to the way we manage our data. We can’t use the production data to test new versions of our application, for example. The dynamic data masking was a beginning but sometimes we really need to hide the data, create a copy of the database replacing some fields with dummy data. That’s the static data masking.
This new feature allows us to choose which columns we would like to mask, choose a mask function and start the process, which will create a masked backup copy of the database, that we can deliver to a tester team, for example.
Data discovery and classification
In the era of GDPR and other similar laws around the world, it’s becoming more and more important to identify exactly what kind of data we have in our databases, if they are public, confidential, and so on.
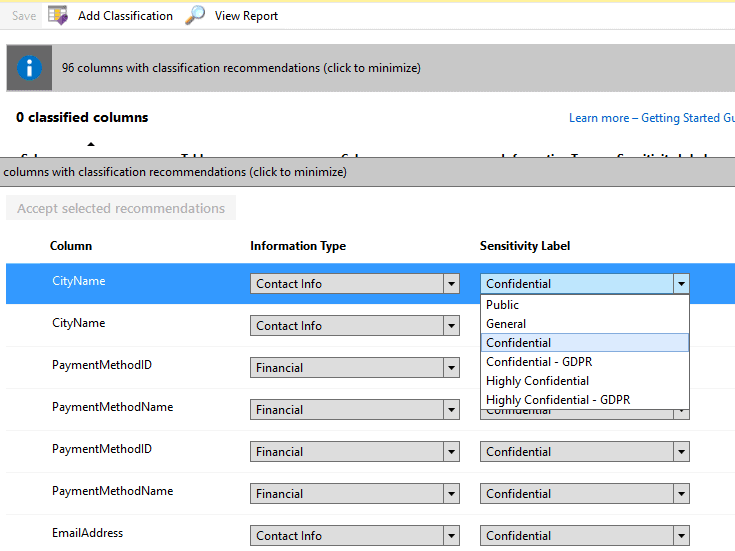
The data discovery and classification feature help us with this. First, it tries to automatically identify which fields are sensitive and recommend a classification for them. We can set classifications for the fields recommended and anyone else.
There are two labels we can set for each field: Information type and sensitive level, this last one includes GDPR levels.
Besides that, we can add both labels for any field in the model, even if it hasn’t initially being identified as sensitive.
All the classifications are stored in two system tables: sys_information_type_name and sys_sensitivity_label_name
It’s an interesting feature, the reports seem interesting, but it’s a modeling feature and SSMS lacks a lot of modeling features, even the database diagrams are being deprecated. I’m not sure about how useful a modeling feature will be inside SSMS.
What are your thoughts? Are you using this feature? Let me know what you think about.
You can learn more about this feature on this link.
Database Upgrade
In my humble opinion, this is the most powerful new feature in SSMS. Every SQL Server version brings many updates on the query optimizer, however, the query optimizer is so powerful that while most of the queries may be improved, some of them may have performance problems. Since SQL Server 2016, a procedure for these situations was established:
- After migrating the database to a new version, keep it on the old compatibility level
- Use query store during a while to create a baseline for query performance
- Change the compatibility level to the new version
- Wait to capture the query executions
- Fix query regressions by forcing old query plans
This feature, also called Query Tunning Assistant, or QTA, help us to execute this process. Mind that this process may take many days or weeks to capture the workload twice, before and after the compatibility model change. This feature creates an upgrade session, recommend the best configuration for query store and follow the workload capture.
The best part is the end of the process: The QTA doesn’t stick only to forcing old query plans, in this case, we could make all the tasks using query store by ourselves. QTA is able to analyze regressed queries and identify many well-known regression problems and suggest the creation of plan guides to solve the problems.
This is way more detailed than we could do by ourselves using the server tools, turning this feature very useful.
Integrated with Azure Data Studio
Azure Data Studio is a new Microsoft tool that allows access not only to SQL Server but to many different data sources either on the cloud or on premises. It’s not clear yet what’s the future relation between SSMS and Azure Data Studio, but now SSMS has the option to open the same connection in Azure Data Studio, moving from one tool to another.
When working with SSMS you are just one click away from opening the same server on Azur Data Studio, right-clicking the connection.
Open Folder
SSMS is a child of Visual Studio, it inherits many visual studio behaviours, including the pattern to work with solution files. Although it’s interesting, DBA’s are not used to solution files, they keep their scripts in .SQL files organized in different folders and that’s it.
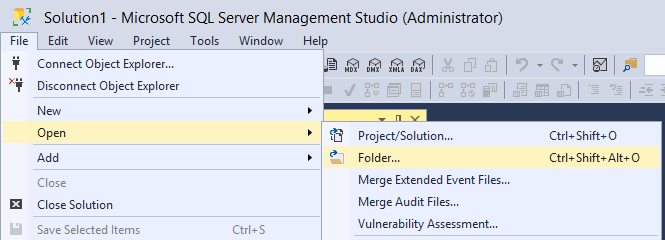
Allowing DBA’s to open a folder as a solution makes our lives way easier and help us with the organization of our scripts.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments