How to accelerate your SQL Server performance using Redgate Monitor

I’ve been lucky enough to spend some time as a racing driver, racing BMWs for three years before joining the BRSCC Porsche Championship. Steve McQueen famously said ‘Racing is life. Anything before or after is just waiting’. When I’m waiting, I’m a SQL Server DBA consultant and throughout my racing and DBA career, I’ve realised the key to better performance in both is data.
The biggest driver is data
If you’re collecting the right data, reviewing it, and taking actions based on that data, you can extract the optimum performance from your engine or SQL Server without your car going up in smoke or your server crashing.
So how do we get this data? In a car, you have readily available information like speed and fuel levels, plus major alerts like ABS or engine problems. This is similar to the basic information you get from task manager or performance monitor and, although it can be stored, it’s frequently looked at for a moment and then discarded.
The second and more detailed source of information is the on-board computer or ECU, which can provide information about engine faults, speed, fuel levels, oil pressure, and temperatures. There’s a lot of real-time information available here but it’s often lost by the time the mechanic has hooked up a laptop. In the SQL Server arena, this is equivalent to wait stats, plan caches, and the general information you get from DMVs.
The most comprehensive solution is to use a data logger. This plugs directly into the ECU and extracts detailed information while collecting other real-time events such as track location, acceleration, and corner force. Storing this data lets you review how the car is performing, informing you of the exact moment an engine code was alerted or the engine misfired, etc.
The data logger is much like Redgate’s Redgate Monitor, collecting and storing real-time data and letting you go back and review what happened during the peaks and troughs of your application’s workload. In the same way you can compare lap times to find the average or theoretical fastest lap, you can use Redgate Monitor to quickly find irregularities such as CPU spikes and resource waits.
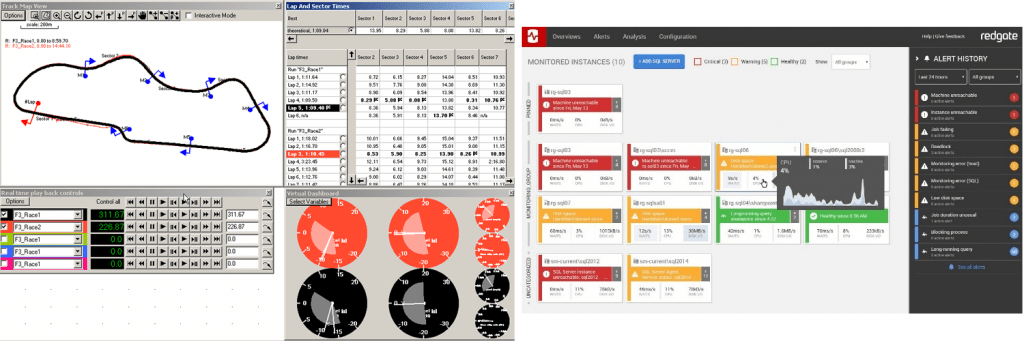
Data logger analysis software and Redgate Monitor
If more severe alerts occur like blocking or deadlocks, they’re logged along with point-in-time information, enabling you to see what other issues occurred and determine if there’s a pattern.
Only by having this detailed data of what happened, when, can you determine the why. And once you have the why, you can figure out what you need to change to improve it.
The biggest obstacle is change
When you make a change to a car, you often put pressure on another area. A rear spoiler may increase downforce at the back of the car and stop oversteer, for example, but can reduce straight-line speed and make the car understeer. You could resolve this by adding a front spoiler to add more downforce at the front end, but this again reduces straight-line speed.
The same is true for databases, where changes are made to address a specific problem and an issue arises elsewhere which is also ‘fixed’. This is how systems can become oversized, over-indexed and unnecessarily complicated.
Redgate Monitor can get you out of a corner here by giving you the ability to see the direct impact of any change you make. You can compare a specific period in time with another or with several periods to show the normal running values and extremes. This data is crucial when reviewing system changes and understanding how, for example, a code change at lunchtime caused increased blocking in the evening.
This is why recording system changes, benchmarking and historical data is important. By looking back at the data, you may find your systems now consume much more CPU during peaks or begin to struggle from resource contention after a change.
Keeping tracking of changes

After every track day, I store data from the car along with the weather conditions, temperature, initial/return tyre temperatures, and the suspension setup. I also note any significant changes to the car such as air filter type, fuel level or any additions like a quick-shifter. This data can then be reviewed when I next visit the track, helping me understand why the car is performing better or worse – and giving me the option to restore the configuration to what it was.
Similarly for SQL Server, I often record setup information before making any changes, especially during benchmarks, tests or system reviews. Here, I augment Redgate Monitor with the free tool I helped to develop, OmniCompare, which takes a snapshot of the SQL Server settings and lets me review them, compare them against the new setup, and share the configuration with colleagues.
(Interestingly, tracking external changes will become much easier in the next major release of Redgate Monitor, which will feature the ability to annotate graphs to see the impact of releases or schema changes.)
Increasing stability
There’s a motorsport saying which is To finish first, you first have to finish. There really isn’t much point having the fastest car in a straight line if you can’t stop it, or it handles so poorly you have to be cautious going around corners. With SQL Server, you can also buy the fastest server, but poor code or configurations can cause it to slow down or fail during peaks.
In both racing and databases, it’s important to focus on consistency and simplicity with the aim of creating a stable and predictable system anyone can get good results with. Compare this to a complex system riddled with hard to spot fixes such as query hints, trace flags or special maintenance queries. Yes, non-standard settings have their uses, but in most cases it’s a last resort or temporary fix.
Redgate Monitor helps you maintain consistency by collecting performance metrics and providing alerts on the long running queries, blocking and deadlocks which are causing your server to exceed its limits during peaks in workload.
It also offers alerts for other important issues such as failed backups, fragmented indexes and integrity checks. Teams often use these alerts as a to-do list and if you have no alerts, you’ll probably have a consistently performing system too
Pushing your data to the limit
Tuning a car’s performance can be just like a database in that you want to push it to just before the point where something breaks, then back off.
In motor racing, it’s about traction and in an ideal world you would extract 99% of the available traction from your tyres at every corner. Once you exceed 100% and your tyres are spinning or sliding, you need to back off the throttle to reduce traction demand before the tyres will grip again. So by overdriving the car, you actually end up going slower and your lap times suffer. For a fast lap, consistency is key.
This is often the case with SQL Server. A well designed database should be able to run at 95% CPU without seeing a degradation in performance. Once a database has been overloaded, you can’t just back off a little because the lack of CPU time may have resulted in inefficient plans being created and therefore queries that now require more resources to execute.
There may also be a backlog of requests which continue to overload a server long after the problematic query has finished or failed. This would be like wheel-spinning the entire lap. Again, consistency is key to the best performance, and Redgate Monitor highlights the inconsistencies for you.
A winning formula
As database professionals, we probably won’t get the champagne and the glory sales get when they land a big deal, or a developer receives for a killer new feature. But that’s not us. We’re not Lewis Hamilton. We’re more like F1’s Adrian Newey.
Using our knowledge and the correct data, we can create a consistent and stable system and, from there, start to push our servers harder, doing more with less, reducing operational costs while at the same time increasing overall performance.
To win in racing, you need to start with a good stable car and then analyze, tune, adapt and analyze again. It’s no different when working with SQL Server: a stable platform and good data will help you win too.
If you’d like to know more about Redgate Monitor, you can download a free fully-functional 14-day trial.
If you’d like to know more about Phil Grayson, you can follow him on Twitter.
Tools in this post
Redgate Monitor
Real-time multi-platform performance monitoring, with alerts and diagnostics
You may also like
-

Live training session
Redgate Monitor: Roadmap and Feature Preview
Get an exclusive look at the exciting features and updates we’re bringing to Redgate Monitor. This interactive session will give you a sneak peek at what's coming next, allowing you to stay ahead with the latest innovations and enhancements.
-

Article
Why is my SQL Server Query Suddenly Slow?
A SQL Server query is suddenly running slowly, for no obvious reason. Grant Fritchey shares a 5-point plan to help you track down the cause and fix the problem.
-
Live training session
Level up your database insights | Identify and diagnose the impact of your deployments with SQL Monitor
In this 30-minute training session, Redgate Solutions Engineer David Ong will show how you can build insights and understand your server performance in an instant with fast deep-dive analysis using SQL Monitor.
-
Article
Tagging in a monitoring tool: what is it and how can it benefit your team?
We recently released a minor version of Redgate Monitor, v12.1, that includes two exciting new features: ‘Tagging’ and a ‘Current Activity’ page. Find a post on the latter here. As you start to have responsibility for more than a handful of SQL Server instances, you’ll need to get more organised. Everyone around you benefits if
-

Webinar
Der ultmative Ratgeber zur Wahl des richtigen Datenbank-Monitoring-Tools
Die Wahl des richtigen Überwachungstools für Ihr Unternehmen geht über den Funktionsvergleich und oft sogar den Preis hinaus. Während Sie wahrscheinlich ein Budget haben, an das Sie sich halten müssen, gibt es neben den Kosten auch andere Faktoren, die Sie berücksichtigen sollten, wenn Sie das richtige Tool für Ihr Unternehmen auswählen. In diesem Webinar werden