Building a Database Directly from Object-level Source Scripts
Table manifests, and object manifests, which are just ordered lists, are a very useful output from and development database build. This article show how to generate a table manifest in SQL, and once you have it, you'll start to find several uses for it, besides the build process.
A tool like SQL Compare can create and update a set of object-level scripts, representing the current “state” of a database. With this object-level scripts directory as the ‘source’ and an empty database, or just an empty file system directory, as the target, it can also generate a ‘synchronization script’ that will build that version of the database, from scratch.
But how would you perform this task for an RDBMS where a schema comparison tool isn’t available? Many RDBMSs provide a tool that will write out an object-level source-code directory, via a script, but not to build a database from these scripts. Alternatively, perhaps you have an automated process that must build the latest version of a database directly from a set of object-level scripts in the version control system, whenever there are new commits, and then run some tests.
In either case, you would need, alongside the object-level source, a table manifest, which is a simple ordered list of your database objects in dependency order, which the build process can use to build the database from the source scripts.
This article will demonstrate how you might do this in SQL, using the redoubtable SQL Server practice database AdventureWorks by way of an example. There are other uses for a manifest too, such as in Managing Datasets for Database Development Work using Flyway.
What is the object-level script directory?
It is common for a database development to be based on, or require, object-level scripts. They are an obvious way of implementing database source control. The intuitive way of arranging the individual scripts that together create the database, is to keep them in an object-level directory. This is a directory that has a subdirectory for each type of database object, such as tables, functions and procedures. Within each of the object-type subdirectories is a collection of files, each of which builds an object.
Most of the popular relational databases provide a way of creating this source-code directory via a script, such as using pg_dump for PostgreSQL or mysqldump for MySQL. SQL Compare, and any other Redgate tool that uses schema comparison ‘under the covers’ (including Flyway Desktop), can do much more. As well as creating such directories, they can read from, compare with, and update changed objects in an object-level script directory. The following screenshot shows the object-level “Source” directory for AdventureWorks, as generated by SQL Compare. It has quite a rich collection of object-types for a small database, so serves to illustrate what such a directory looks like:
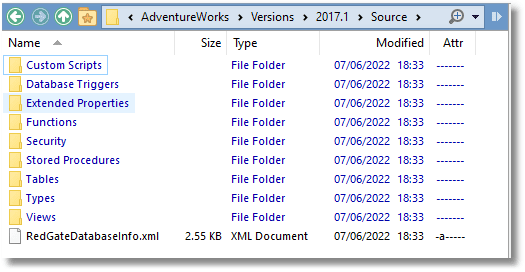
Some object-type folders also contain subfolders: The Security folder contains a subfolder for schemas. The Types folder contains a subfolder for User-defined Data types and XML Schema Collections. Each object-level source file includes both the schema and name of the object
The Custom Scripts directory is different and contains only pre- and post-deployment scripts. I’ve explained these in the article ‘Using Custom Deployment Scripts with SQL Compare or SQL Change Automation‘.
In the root of the folder of a Redgate directory is an XML file with implementation-level information about the database and the Redgate tool that created the object-level directory. Curiously, there is no natural place for the version of the database, and this is normally added via a version file or by the naming of the directory containing the object-level source folder.
Why have an object-level directory?
This question has been answered already in several articles, such as ‘How to create a directory of object-level scripts using SQL Compare‘ or ‘Comparing Two SQL Server Databases: When, Why, and How‘.
In summary, it is useful for a variety of different methods of building or migrating a database: You can build directly from such a directory or maintain it from a living development database that is being updated piecemeal by the developers. You can create it for each version of a migrated database. The $CreateScriptFoldersIfNecessary task in my Flyway Teamwork PowerShell framework generates the object-level scripts for several RDBMSs after each migration (see Creating Database Build Artifacts when Running Flyway Migrations). Where possible, it uses the schema comparison tool, but otherwise it uses the RDBMS’s native database dump utilities and calls it iteratively for every object (it’s slow but it works!).
In summary, these object-level directories are useful for
- Putting a database into version control. SQL Compare will accept an object-level directory as a source or a target. If you use it as a target, SQL Compare will update the files of any objects that are changed, so that their definitions match those in the source database.
- Tracking development changes before you are ready to commit to a team-based source control system
- Searching through a directory of scripts so that you will know immediately what views or functions, for example, reference a particular table.
- Renaming several objects at a time for a build or performing other extensive operations that similarly involve several database objects.
- Deploying just a few changed objects from one database to another to bring it to the same version.
When used with a source control system such a Git, you get a very precise feel for what objects have changed in a database, and how. This helps with team coordination because you can see what changes are currently being committed to the branch.
There is one thing missing, though. You can’t easily build a database directly from an object-level source because it is difficult to work out the order in which the objects should be built. Once you know the order, it becomes a simple scripting exercise.
Building from an object-level script directory using SQLCMD
To successfully build from an object-level script directory, you need to build any particular object only when the objects that it references have already been built. All the foreign key constraints, for example, are held with the table definition so you can’t sneakily add them in after all the tables are in place. In any case, if a schema-bound function is referenced by a computed field or constraint, it must also be in place first. The developers of SQL Compare spent a long time working out how to parse the script, work out the dependencies, and provide a bullet-proof way of scripting the result.
Normal practice is to save a complete build script every time that you save an object-level directory, which is a good belt-and-braces precaution, and one that I follow with Flyway Teamwork. However, all you need is a table manifest generated at the time to tell you the order of build, and this will generally cope with building from the directory, when some of the object-scripts have changed. Of course, if new object scripts are added, or changes to existing objects affects the dependencies between them, then you’ll need to alter the manifest accordingly or even generate a new manifest.
You might think that you are facing a world of tedium and pain in reading all those files and scripting stuff but, in fact, building a database from individual files, via a manifest, is old hat for most relational databases. There are always native tools that can help, by executing a SQL script in a file. In PostgreSQL, for example, there is the psql -f option, and the mysql.exe files allow several ways to do it.
For SQL Server, one of the original design aims of SQLCMD was that it could be used for an object-level build. This goes one-better by being able to execute what amounts to a manifest. There is a ‘:R‘ directive that allows you to execute as many SQL batches from a file as you want. It even allows you to configure placeholders. This means that you don’t need a separate manifest; you can execute a SQLCMD file to create a database from one SQL file that is just a list of directives that tells SQLCMD what actual files to use to build a database:
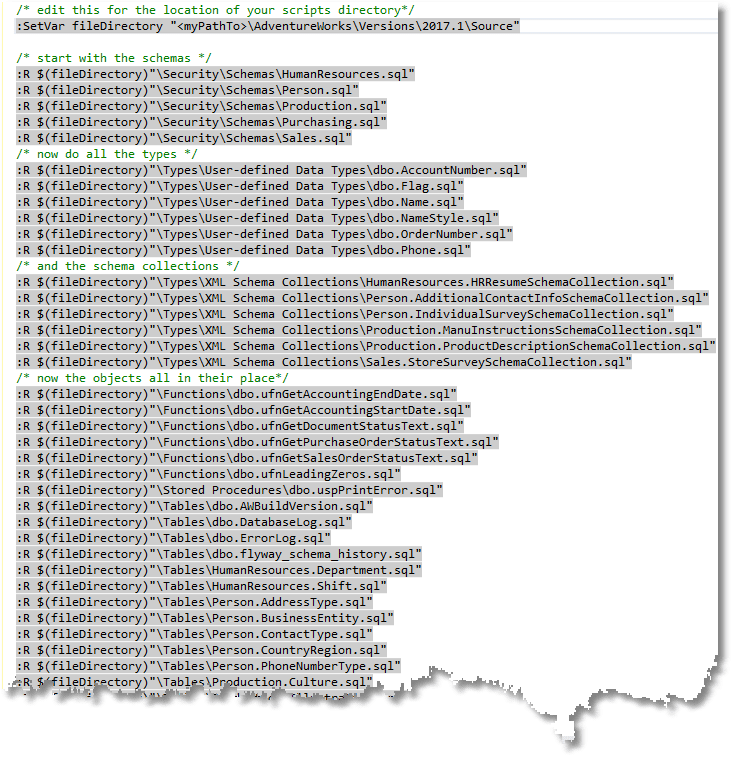
Creating the table manifest
All we need is a SQL function to create the manifest that we can then save in a handy directory, to be executed with SQLCMD. Even better for our demonstration, we can even execute it in SSMS as a SQLCMD script.
We just need a SQL script to derive an order of execution of the scripts to create each object in the right order. With this, we can generate the actual SQLCMD script. After we’ve done this, we either save the executable manifest or switch the SSMS browser pane into SQLCMD mode and then execute it in SSMS.
(Phil Factor spits on hands and commences work)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 |
CREATE OR ALTER FUNCTION dbo.CreateManifest /** Summary: > This is a Table-valued function that produces a manifest(list) of all the objects in the current database in the order of build so that there are no errors due to missing references. Author: Phil Factor Date: Tuesday, 21 June 2022 Examples: - Select * from dbo.CreateManifest(1) - SELECT ':R $(fileDirectory)"\' + TheType+'\' + TheSchema + '.' + TheName + '.sql"' AS List_Item FROM dbo.CreateManifest (1); Returns: > nothing **/ (@WeIncludeSchemas BIT = 1 -- you wouldn't want this with Flyway ) RETURNS @ManifestList TABLE (TheOrder INT IDENTITY, --the order in which you build. Actually the objects in --the same 'layer' can be built in any order. TheLayer INT NOT NULL DEFAULT 0, --the group of objects that can be built TheSchema sysname NOT NULL, TheType sysname NOT NULL, TheName sysname NOT NULL, TheObject_ID INT NOT NULL -- unique (can't use this with the non-object 'things') ) AS BEGIN DECLARE @objectList TABLE (TheType sysname NOT NULL, TheSchema sysname NOT NULL, TheName sysname NOT NULL, TheObject_ID INT NOT NULL UNIQUE); -- we gather all the important objects (views, tables and routines into a table INSERT INTO @objectList (TheType, TheSchema, TheName, TheObject_ID) SELECT --SQL Prompt Formatting off CASE theType when 'procedure' then 'Stored Procedures' else upper(substring(TheType,1,1))+lower(rtrim(substring(theType,2,80)))+'s' END asTheType, --SQL Prompt Formatting on TheSchema, TheName, TheObjectID FROM (SELECT CASE WHEN TABLE_TYPE = 'BASE TABLE' THEN 'TABLE ' ELSE TABLE_TYPE END AS TheType, TABLE_SCHEMA AS TheSchema, TABLE_NAME AS TheName, Object_Id ( QuoteName (TABLE_SCHEMA) + '.' + QuoteName (TABLE_NAME)) AS "TheObjectID" FROM INFORMATION_SCHEMA.TABLES UNION ALL SELECT ROUTINE_TYPE, ROUTINE_SCHEMA, ROUTINE_NAME, Object_Id ( QuoteName (ROUTINE_SCHEMA) + '.' + QuoteName (ROUTINE_NAME)) FROM INFORMATION_SCHEMA.ROUTINES) TheMetadata; /* we now add database 'things' that aren't classed as objects. you just add whatever fancy stuff you're using */ IF (@WeIncludeSchemas = 1) INSERT INTO @ManifestList (TheLayer, TheSchema, TheType, TheName, TheObject_ID) SELECT -2, '', 'Security\Schemas', name, -1 FROM sys.schemas WHERE schema_id > 4 AND name NOT LIKE 'db_%'; INSERT INTO @ManifestList (TheLayer, TheSchema, TheType, TheName, TheObject_ID) SELECT -1, Schema_Name (schema_id), 'Types\User-defined Data Types', name, 0 FROM sys.types WHERE is_user_defined = 1 UNION ALL SELECT 0, Schema_Name (schema_id), 'Types\XML Schema Collections', name, 0 FROM sys.xml_schema_collections WHERE schema_id > 4; -- we now make a table of all the relationships DECLARE @Relationships TABLE (Referencing_id INT NOT NULL, Referenced_id INT NOT NULL); INSERT INTO @Relationships (Referencing_id, Referenced_id) SELECT DISTINCT referencing_id, Referenced_id FROM -- we get all the hard relationships indicated by FKs (SELECT parent_object_id AS referencing_id, referenced_object_id AS Referenced_id FROM sys.foreign_keys UNION ALL --and all the 'soft' relationships SELECT SED.referencing_id, SED.referenced_id FROM sys.sql_expression_dependencies SED INNER JOIN sys.objects ON SED.referencing_id = objects.object_id WHERE SED.referenced_schema_name IS NOT NULL AND SED.referenced_minor_id = 0 AND SED.referenced_id IS NOT NULL AND SED.referenced_class = 1 --assume types done first. AND SED.referencing_id <> SED.referenced_id --AND SED.is_schema_bound_reference = 1 ) f; --at any point, we need to know what objects aren't in the manifest DECLARE @Unbuilt TABLE (TheSchema sysname NOT NULL, TheName sysname NOT NULL, TheType sysname NOT NULL, TheObject_ID INT NOT NULL); DECLARE @TheLayer INT = 1; --the current layer determining the order of build WHILE (@TheLayer < 20) BEGIN --find out all objects not yet in the manifest DELETE FROM @Unbuilt; --we refresh the unbuilt list INSERT INTO @Unbuilt (TheObject_ID, TheSchema, TheName, TheType) SELECT AllObjects.TheObject_ID, AllObjects.TheSchema, AllObjects.TheName, AllObjects.TheType FROM @objectList AllObjects LEFT OUTER JOIN @ManifestList RemovedObjects ON AllObjects.TheObject_ID = RemovedObjects.TheObject_ID WHERE RemovedObjects.TheObject_ID IS NULL; INSERT INTO @ManifestList (TheSchema, TheType, TheName, TheObject_ID, TheLayer) SELECT DISTINCT unbuilt.TheSchema, unbuilt.TheType, unbuilt.TheName, unbuilt.TheObject_ID, @TheLayer FROM @Unbuilt unbuilt LEFT OUTER JOIN (SELECT DISTINCT Referencing_id FROM @Relationships Relationships LEFT OUTER JOIN @ManifestList manifestList ON Relationships.Referenced_id = manifestList.TheObject_ID WHERE manifestList.TheObject_ID IS NULL) f ON f.Referencing_id = TheObject_ID WHERE f.Referencing_id IS NULL; SELECT @TheLayer = @TheLayer + 1; END; RETURN; END; GO |
Convert the manifest into a SQLCMD script
This script creates a result in which each line is a simple SQLCMD line to execute a script from a file. I can now convert this result into the basis for a SQLCMD script that can be executed in SSMS to create the database. To create this result, you just need to connect the query window in SSMS to the database that was used to create the object-level script (AdventureWorks, in my case), and run the following script:
|
1 2 3 4 |
SELECT ':R $(fileDirectory)"\' + TheType+'\' + CASE TheSchema WHEN '' THEN '' ELSE TheSchema + '.'END + TheName + '.sql"' AS List_Item FROM dbo.CreateManifest (1); |
The $(fileDirectory) placeholder will, when executed, be assigned the value of the location of the object-level directory of source scripts, for the version of the database you want to build. If you assign the value of 1 to the parameter of CreateManifest, it adds the files for creating each of the schemas (humanResources, Person, Production and so on) to the manifest.
If you want to run this “build-from-object-scripts” as in an automated process, with Flyway, you’ll need to omit the schema creation scripts (Flyway manages schema creation), which you can do by specifying a value of 0. You will also need to remove, from the output, any entry for a file that will create the Flyway schema history table!
For Adventureworks, the output will be …
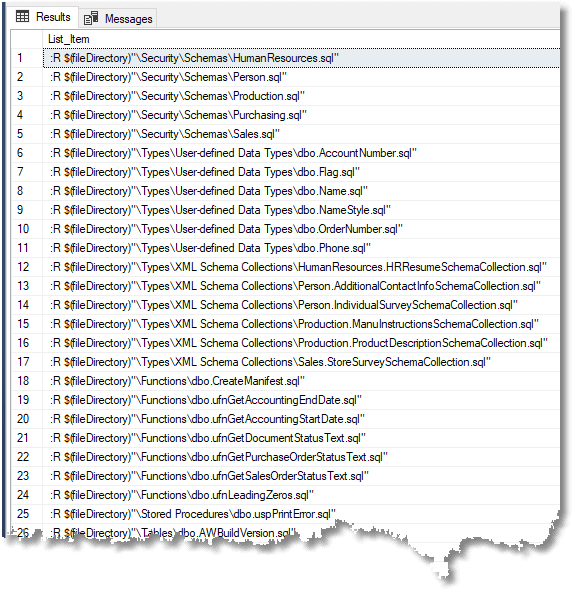
To try this out:
- Create an empty copy of your AdventureWorks database
- Open a query pane in SSMS, connect it to the empty database and set it to SQLCMD mode using the Query -> SQLCMD mode menu option
- Copy the above output into this new SQLCMD query pane; a grey background will appear for the text.
- Add a first line specifying a path for the SQLCMD placeholder that defines where your object-level script directory is held (:SetVar fileDirectory “<myPathTo>\AdventureWorks\Source”)
Now just run it and after twenty seconds, you have a new version of Adventureworks. Easy, eh? If you save this file, you can now execute it in SQLCMD to can create as many copies of the database as you fancy. All you need are the blank databases.
Manifests for the SQL Compare user
Armed with a table manifest, you can now build a database directly from an object-level directory of your database’s source, using SSMS or SQLCMD, as well as by using SQL Compare.
Why would you ever want to do that? The answer is that it helps to facilitate DevOps automation of a part of the development cycle. If you are using source control, then you need to build directly from the files that represent the current database to validate the source; maybe it is just to verify that it is possible to do so, or to then run automated tests. You can build a database very easily and reliably with SQL Compare at the command line with object-level directory as source, and the ’empty’ parameter for the target database, but this creates a new synchronization script that is then used to build the database.
You still need SQL Compare to maintain the object-level source. All you are doing is to provide a manifest that gives you a list of the best order for building the components of the database that will then allow you to build databases directly from the object source scripts. This would suit an automated solution that can be initiated from a Git hook. However, of course, you’d need to regenerate the manifest every time you added an object or changed the dependencies.
Conclusions
There is nothing mystical about the methods of building a database from object-level scripts. Whatever the database system we are using, we just must do it in the right order. The same goes for deleting data or updating data. In the case of a build, migration or change to a database, it is just the precaution we always take, however we do the task, to never create a table, function, or any other database object until all the other objects that it relies on are present. After all, you wouldn’t create a table in a schema that doesn’t yet exist. You wouldn’t create a foreign key in a table referring to a table you hadn’t yet created.
For this reason, table manifests and object manifests, which are just ordered lists, are a very useful output from and development database build. Once you have them, you’ll start to find several uses for them, besides the build process.
Tools in this post
You may also like
-

Article
Branching and Merging in Database Development using Flyway
How to exploit the branching and merging capabilities of Git for scaling up team-based development, when doing Flyway migrations.
-

Article
Checking for Missing Module References in a SQL Server Database Using Flyway
There are certain checks that need to be done after a database migration is complete. One good example of this is the check that a migration script, such as one that merges changes from a branch into main, doesn't cause 'invalid objects' (a.k.a. 'missing references') in your databases. I'll show you how to run this check, using
sp_RefreshSQLModule, and incorporate it into a Flyway "after" migration script. -

Article
Working with Flyway and Entity Framework Code First: Automation
This article will demonstrate how to automate a hybrid database change management system that uses Entity Framework Code First for development and Flyway for deployments. We automatically convert C# migrations, produced by EF, to the Flyway format and then use Flyway command line to deploy the migrations and save the 'object-level state' of each new database version, so we can track exactly which objects changed, and how, between versions.
-
Article
A first view of Flightpath
Once a year at Redgate we hold Down Tools Week. It’s our hack week, when we temporarily put aside our normal work and form ad-hoc teams to propose, vote on and tackle new problems. Last time one team took a look at database provisioning in tandem with Flyway. This year, as knowledge about Flyway has spread through
-

Article
SQL Compare Snapshots: a lightweight database version control and rollback mechanism
During the proof-of-concept phase of development work, SQL Compare Snapshots offer an easy way to work out what broke, if a change causes some tests to fail, as well as a simple ‘roll back’ technique to return quickly to the last working copy.